- The paper introduces C²DLM, which integrates concept-level causal meta-knowledge extraction and a V-aware re-attention mechanism to improve reasoning in LLMs.
- It demonstrates a 12% performance improvement on causal reasoning tasks and a 3.2× training speedup, with notable gains on datasets like Sudoku and the Spurious Token Game.
- The methodology leverages causal alignment to correct attention distortions, offering a scalable approach for more interpretable and robust AI systems.
Causal Concept-Guided Diffusion LLMs (C2DLM)
Introduction and Motivation
The development of LLMs has prominently featured two paradigms: Autoregressive (AR) models and Diffusion LLMs (DLMs). Both are pivotal but suffer from limited reasoning capabilities. Autoregressive models, which predict the next token in sequence using a causal mask, are constrained by left-to-right information flow, often leading to suboptimal global understanding. Diffusion models, while innovative with a fully connected attention framework, ignore causal order, which can dilute reasoning coherence. To address these deficiencies, the paper "C2DLM: Causal Concept-Guided Diffusion LLMs" introduces the C2DLM, aiming to leverage causal relationships inherently present in human reasoning to enhance both paradigms without their drawbacks.
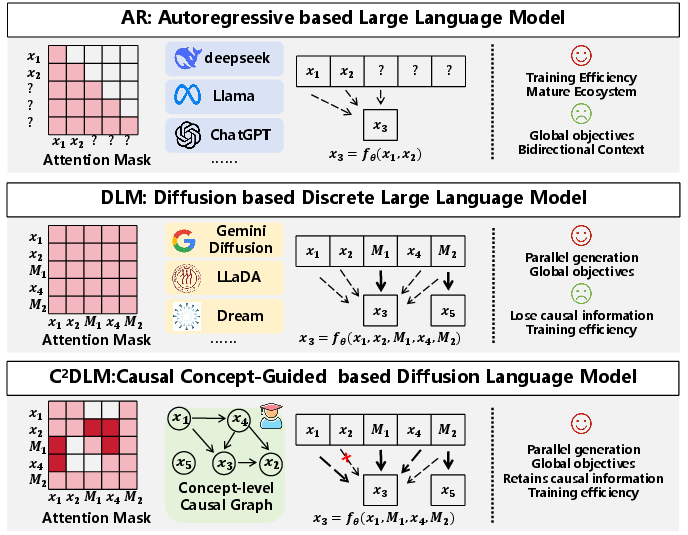
Figure 1: Difference between AR, DLM, and C2DLM. AR models struggle to capture global information, while DLMs discard causal structure. The C2DLM captures causal relations explicitly to improve language generation.
Methodology
The C2DLM's framework is constructed around two pivotal innovations: concept-level causal meta-knowledge extraction and causal alignment through a V-aware re-attention mechanism.
This automated process extracts causal graphs at a conceptual level from teacher models using in-context learning (ICL). The goal is to establish causal relationships within a LLM by constructing reasoning graphs that reflect true causal dependencies rather than mere token correlations. By doing so, the C2DLM systemically aligns model priors with the innate causal structures of natural language.
Causal Alignment through V-Aware Re-Attention Mechanism
Building further, the V-aware Re-attention mechanism adjusts attention weights in alignment with causal graphs. Derived from the norms of value matrices in attention heads, this re-weighting corrects potential distortions caused by the attention sink phenomenon, ensuring stability and fidelity in learning token interactions.
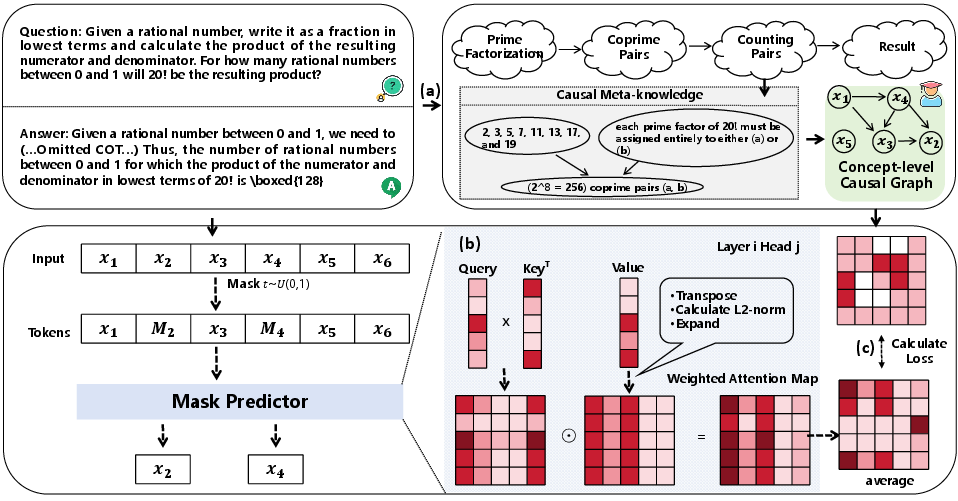
Figure 2: The causal teacher model uses prompts for concept extraction, generating causal meta-knowledge as signals for supervised learning.
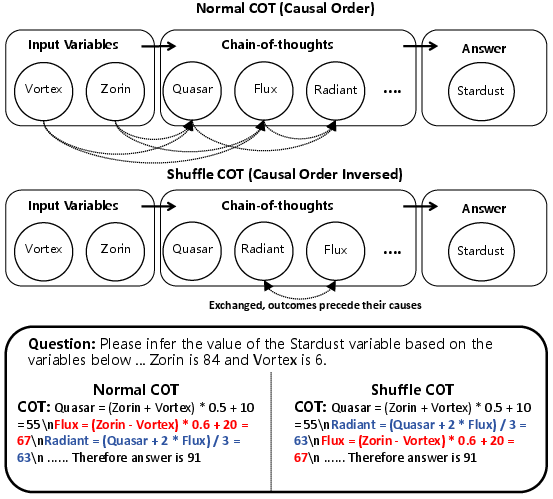
Figure 3: Normal COT follows the causal topological order for coherent reasoning step constructions, while Shuffle simulates causal disorder.
Experimental Evaluation
The C2DLM demonstrates its strength across multiple synthetic and real-world tasks.
COT-OrderPerturb Dataset
This new dataset explores the impact of causal order on AR and DLM models through controlled perturbations. It reveals that restructuring reasoning steps can diminish AR performance while perturbations less affect DLM due to their inherent robustness from order-independence. C2DLM achieves a 12% increase in performance on standard causal chains, along with a 3.2× training speedup.
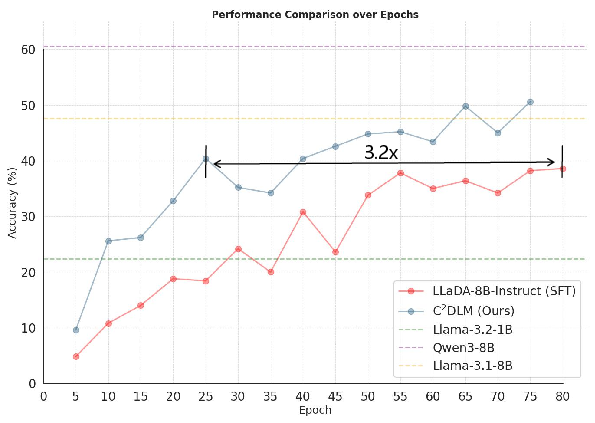
Figure 4: Accuracy curve indicating training progress with COT-OrderPerturb, highlighting improved efficiency.
C2DLM significantly outperformed baseline models in datasets with strong causal priors like Sudoku and the Spurious Token Game (STG), demonstrating a 7.43% improvement on average. Additionally, for general reasoning tasks including GSM8K and MATH500, C2DLM achieved consistent gains even with limited causally annotated examples, emphasizing its practical applicability.
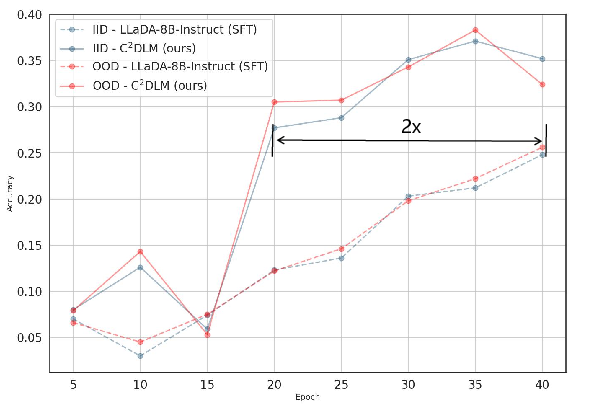
Figure 5: Performance change curve during different training epochs on the STG_H dataset.
Conclusions and Future Directions
The research outlines a novel integration of causal structures into diffusion-based LLMs, proving that such alignment can enhance reasoning capability and efficiency significantly. By addressing the conceptual misalignment present in both AR and DLM frameworks, C2DLM unlocks potentials for more interpretably robust AI systems. Future work could explore the scalability of this approach, particularly in pretraining stages and larger-scale applications, as well as address complex causal graphs and extended chain-of-thought scenarios.

