- The paper introduces a modular in-context pipeline that decomposes the PC algorithm into discrete reasoning stages, achieving nearly an 18% F1 improvement.
- The paper leverages reasoning-specialist LLMs like OpenAI's o3-mini and DeepSeek-R1 to perform iterative self-checks and refine causal inference under data perturbations.
- The paper demonstrates that decomposing causal discovery into structured stages enhances robustness and accuracy, outperforming conventional zero-shot models on the CORR2CAUSE benchmark.
Modular In-Context Learning for Causal Discovery
The paper "Causal Reasoning in Pieces: Modular In-Context Learning for Causal Discovery" (2507.23488) addresses the challenge of robust causal discovery using LLMs, particularly in scenarios where conventional models exhibit overfitting and poor generalization under data perturbations. The authors introduce a modular in-context pipeline framework that decomposes the PC algorithm into distinct reasoning stages, leveraging state-of-the-art reasoning-specialist LLMs like OpenAI's o3-mini and DeepSeek-R1. The results demonstrate significant improvements over traditional baselines, highlighting the importance of structured in-context learning for maximizing the capabilities of advanced reasoning models in causal inference tasks.
Background and Motivation
LLMs have shown promise in various reasoning tasks, but their ability to perform robust causal discovery remains a challenge. The Corr2Cause benchmark [jin2024largelanguagemodelsinfer] reveals that even fine-tuned models struggle with minimal perturbations, often relying on superficial pattern matching rather than genuine causal inference. In response, the authors evaluate the performance of reasoning-specialist LLMs, which exhibit internally disciplined inference processes. They introduce a modular in-context pipeline inspired by Tree-of-Thoughts and Chain-of-Thoughts methodologies [yao2023treethoughtsdeliberateproblem, wei2023chainofthoughtpromptingelicitsreasoning] to improve accuracy by guiding the model through a sequence of subproblems, each with its own prompt and parser.
Methodology: Modular In-Context Pipeline
The paper's core contribution is a modular in-context pipeline framework tailored for PC-algorithm-based causal discovery. The framework decomposes the causal discovery process into four focused prompts: undirected skeleton extraction, v-structure identification, Meek’s rules orientation, and hypothesis evaluation. (Figure 1) illustrates the stage-wise in-context pipeline, where each stage's output serves as the input for the next stage. This decomposition allows for richer intermediate artifacts, sharpens the model's focus, and transforms a brittle one-shot pass into a robust multi-stage inference procedure. The PC algorithm's correctness relies on three assumptions: DAGs, the Causal Markov Condition, and faithfulness [scheines2005introduction, 10.1214/12-AOS1080].
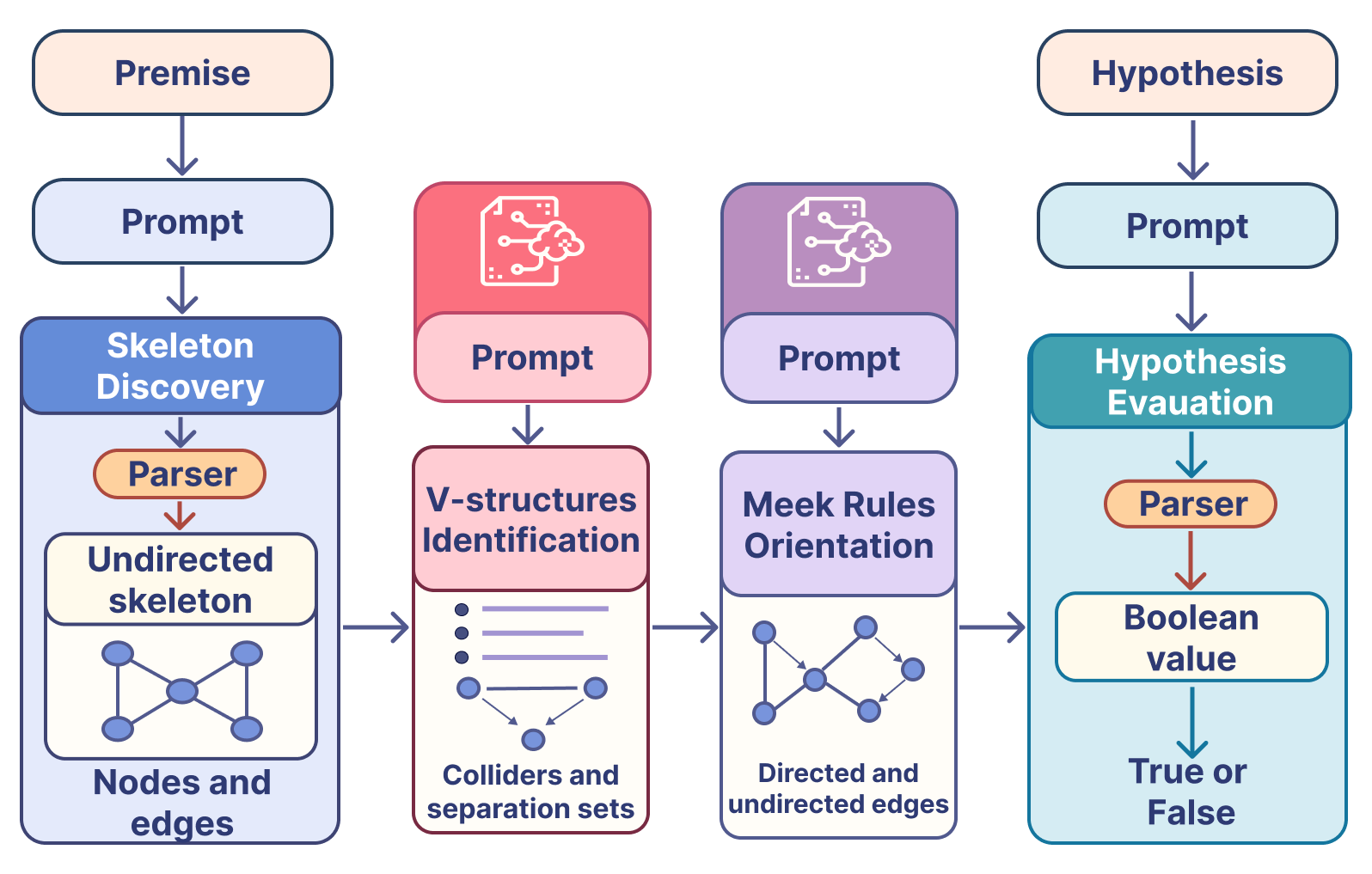
Figure 1: Stage-wise in-context pipeline for causal discovery, illustrating the flow of data between prompts and parsing modules.
Implementation Details
The implementation builds upon the PC algorithm [spirtes2001causation], a constraint-based causal discovery algorithm that uses conditional independence testing to recover a causal graph from observational data. The algorithm consists of two main phases: constructing an undirected skeleton and partially orienting the remaining edges. The modular pipeline issues each stage as a dedicated prompt, which can be contrasted with a single, comprehensive baseline. The authors establish a zero-shot baseline by prompting models to judge causal hypotheses from natural-language conditional independence statements. They compare this baseline against a modular in-context causal discovery pipeline that decomposes the PC algorithm into distinct reasoning stages, with each stage's output being consumed by the next stage's prompt.
Experimental Evaluation
The empirical evaluation consists of three parts: benchmarking the zero-shot reasoning baselines and modular in-context pipeline against published Corr2Cause results, performing an inter-model analysis of reasoning LLMs to identify error-prone pipeline stages, and conducting a combined quantitative and qualitative failure analysis of conventional-model errors and the reasoning model's corrective mechanisms. (Figure 2) shows the efficiency trade-off on the Corr2Cause benchmark, plotting F1 scores against average token usage for both baseline and pipeline settings. The results validate that reasoning-specialist LLMs substantially outperform prior models in a pure zero-shot setting and that a carefully structured in-context pipeline can unlock further gains without external supervision or fine-tuning.
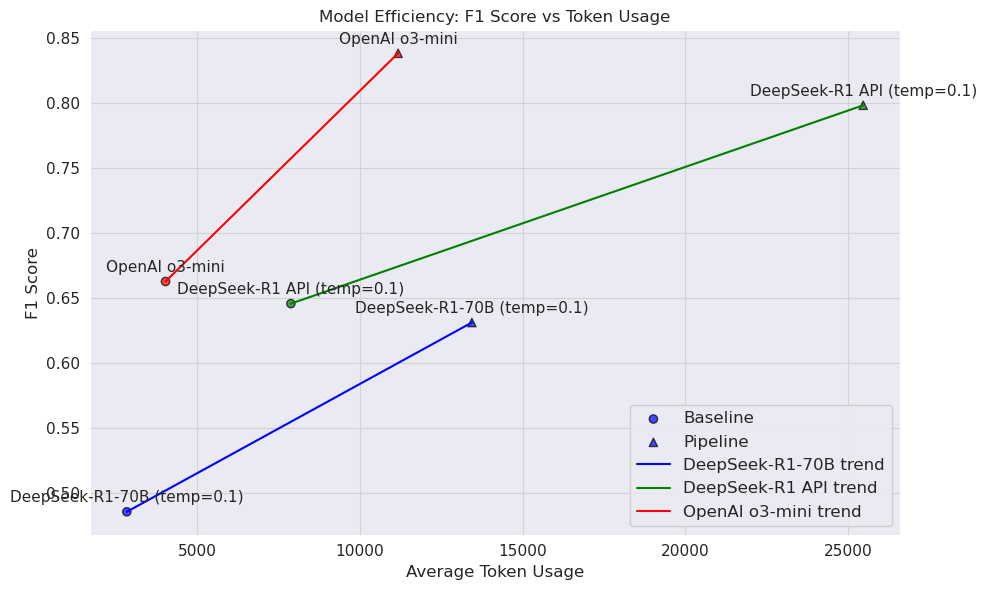
Figure 2: Efficiency trade-off on the Corr2Cause benchmark, demonstrating the correlation between increased token investment in the pipeline and F1 improvements.
The authors compared their approach with PC-SubQ [sgouritsa2024prompting], noting differences in modular design, quantitative performance, and focus on reasoning models. Their modular pipeline achieves an F1 score of 83.83% on CORR2CAUSE with OpenAI o3-mini, a nearly 18% improvement over the baseline reasoning model. In contrast, PC-SubQ reports substantially lower F1 scores.
Qualitative and Quantitative Analysis
A qualitative and quantitative failure analysis contrasts the performance of conventional models (LLaMA3.3-70B) and reasoning models (DeepSeek-R1-70B). (Figure 3) (left) compares the average number of independence tests of pair of variables that common models classify correctly versus those it misclassifies. (Figure 3) (right) shows the average error of the conventional model on instances where the reasoning model revisits k times in its reasoning trace. The reasoning model performs iterative self-checks, revisits each edge during reasoning trace micro-steps, and refines decisions in real time, underlying its qualitative advantage.
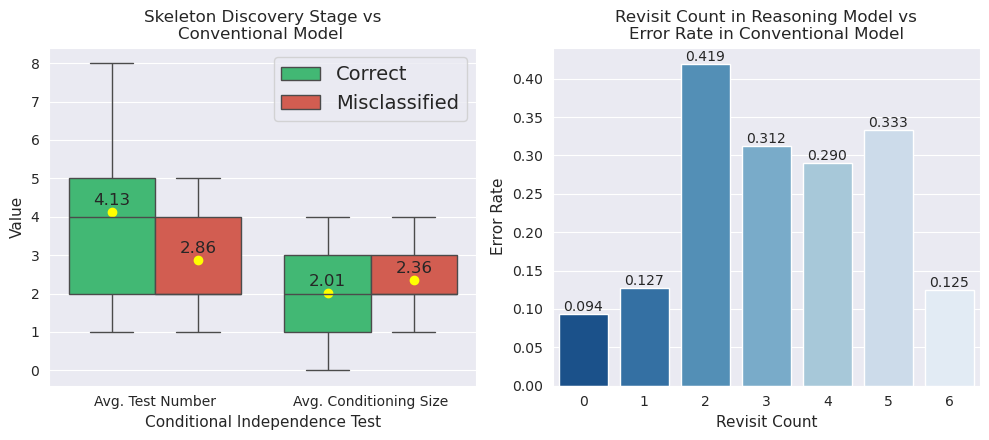
Figure 3: (Left) Boxplot of conditional independence sets metrics. (Right) Bars showing the fraction of edges misclassified by the common model among those the reasoning model revisited k times.
Implications and Future Directions
The modular in-context pipeline offers a blueprint for causal discovery, leveraging the strengths of modern reasoning models. The gains are attributed to the decomposition of the PC algorithm into separate stages, the production of rich intermediate artifacts, and the amplification of the model's native iterative enrichment of its reasoning traces. However, this comes at the cost of increased computation, as multiple sequential model requests and longer reasoning traces substantially raise token usage. Future work may focus on assessing robustness and effectiveness on other datasets.
Conclusion
The paper demonstrates that state-of-the-art reasoning models can surpass prior causal-discovery results on the Corr2Cause benchmark in zero-shot settings. The modular in-context pipeline achieves significant F1 improvements without fine-tuning, emphasizing the importance of structured reasoning processes in causal inference. While computational costs are a consideration, the framework provides a valuable approach for enhancing causal discovery through carefully designed prompt engineering and stage decomposition.