- The paper demonstrates a novel dual-system AI model that couples slow semantic reasoning with fast reactive control to enhance long-horizon embodied navigation.
- It leverages the Nav-CoT-110K dataset with 110K Chains-of-Thought trajectories to improve structured decision-making through supervised fine-tuning and reinforcement learning.
- Empirical results show superior navigation success and trajectory fidelity in diverse indoor scenarios with sub-100ms control latency.
Nav-R1: Reasoning and Navigation in Embodied Scenes
Introduction and Motivation
Nav-R1 introduces a unified embodied foundation model for reasoning, planning, dialogue, and navigation in 3D environments. The work addresses two persistent challenges in embodied AI: (1) incoherent and unstable reasoning traces that hinder generalization and semantic alignment, and (2) the difficulty of balancing long-horizon semantic reasoning with low-latency control for real-time navigation. Nav-R1 is designed to tightly couple multimodal perception, structured reasoning, and embodied control, enabling robust interaction and execution in complex, dynamic scenes.
Architecture and Fast-in-Slow Reasoning Paradigm
Nav-R1 employs a Fast-in-Slow dual-system architecture inspired by cognitive science, decoupling deliberate semantic reasoning (slow system) from rapid reactive control (fast system). The slow system aggregates egocentric RGB-D views, point cloud data, and language instructions to perform long-horizon semantic reasoning, producing latent features that encode scene semantics and global navigation goals. The fast system, operating at a higher frequency, fuses high-frequency multimodal inputs with the slow system's latent features to execute short-horizon actions with low latency.
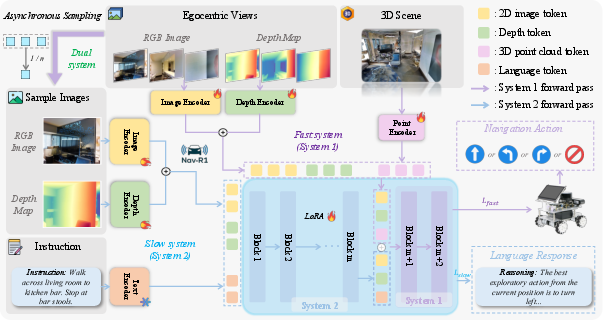
Figure 1: Architecture of Nav-R1, illustrating the Fast-in-Slow reasoning paradigm for coherent long-horizon reasoning and low-latency navigation.
Asynchronous coordination between the two systems ensures that global semantic consistency is maintained while enabling efficient real-time control. Empirical results show that a frequency ratio of $1\!:\!3$ between slow and fast systems achieves optimal trade-offs in semantic fidelity and responsiveness.
Nav-CoT-110K Dataset and CoT Data Engine
A key contribution is the construction of Nav-CoT-110K, a large-scale dataset of 110K step-by-step Chains-of-Thought (CoT) trajectories for embodied tasks. The CoT data engine synthesizes high-quality reasoning traces by prompting a strong VLM (Gemini 2.5 Pro) with egocentric observations, navigation instructions, candidate actions, and explicit output formatting. Outputs are filtered for logical consistency and action feasibility, resulting in a dataset that tightly couples perception, language, and action.
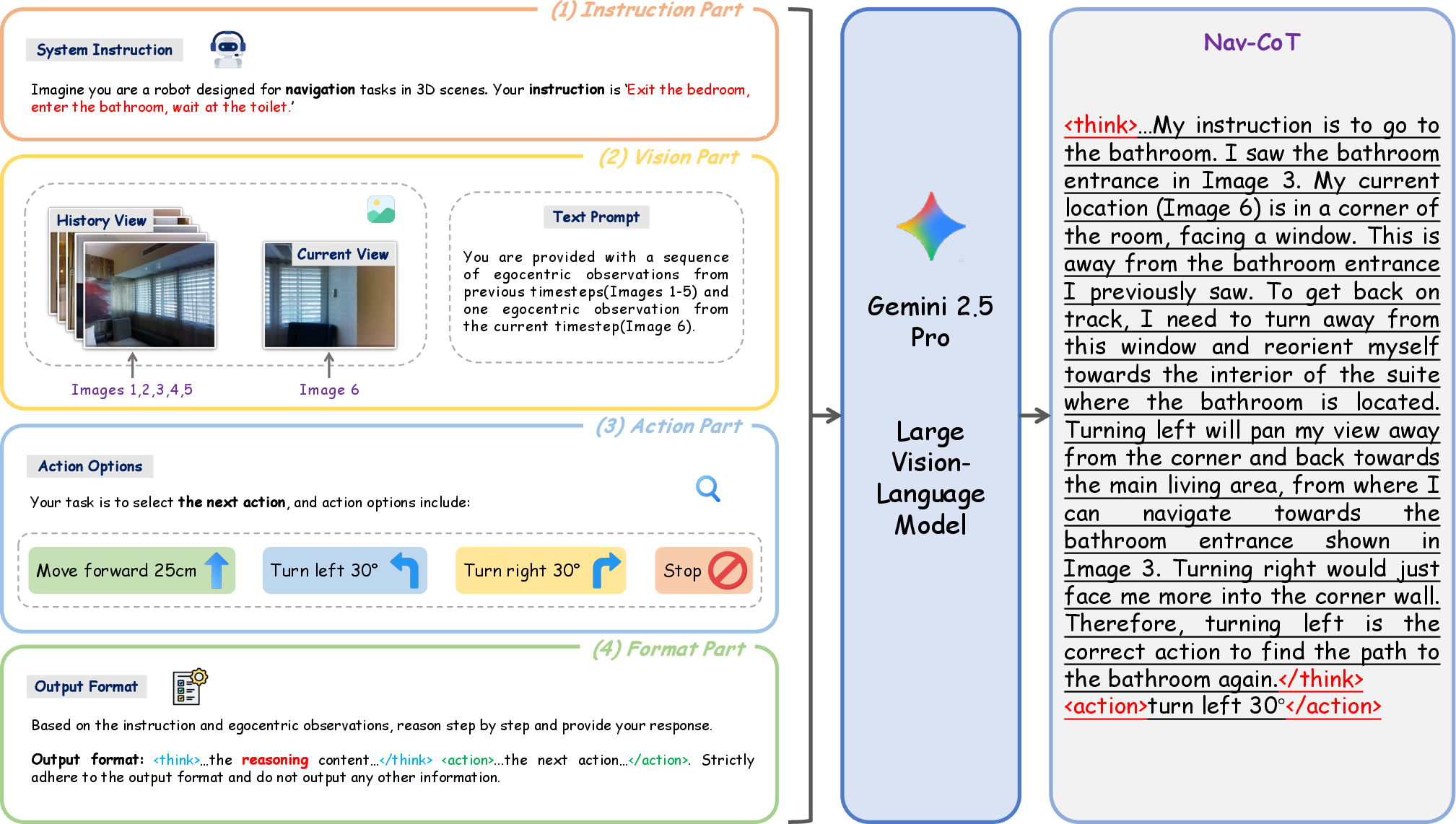
Figure 2: CoT Data Engine for generating Nav-CoT-110K, integrating instructions, visual inputs, action options, and output format for structured reasoning and decision-making.
This dataset is used for cold-start supervised fine-tuning, stabilizing subsequent RL optimization and equipping Nav-R1 with structured reasoning capabilities.
Reinforcement Learning with Multi-Dimensional Rewards
Nav-R1 leverages Group Relative Policy Optimization (GRPO) for reinforcement learning, introducing three complementary reward functions:
- Format Reward: Enforces strict adherence to the reasoning-decision template, ensuring outputs are machine-parseable and disentangled.
- Understanding Reward: Combines exact answer correctness with CLIP-based semantic alignment to prevent factual errors and irrelevant outputs.
- Navigation Reward: Optimizes trajectory fidelity and endpoint accuracy, integrating path and endpoint rewards for robust goal-reaching behavior.

Figure 3: RL Policy pipeline, showing multi-sample generation, reward computation (understanding, navigation, format), and policy update via GRPO with KL regularization.
Policy optimization is performed by sampling multiple candidate responses, computing normalized relative advantages, and maximizing the clipped GRPO objective with KL regularization against a frozen reference policy.
Real-World Deployment and Test-Time Efficiency
Nav-R1 is deployed on a WHEELTEC R550 mobile robot equipped with Jetson Orin Nano, LiDAR, and RGB-D camera. Due to limited onboard resources, inference is performed on a cloud server, with egocentric inputs streamed to the cloud and navigation commands returned for execution. This design enables real-time closed-loop control with sub-100ms latency, validated by high-speed WiFi transmission.
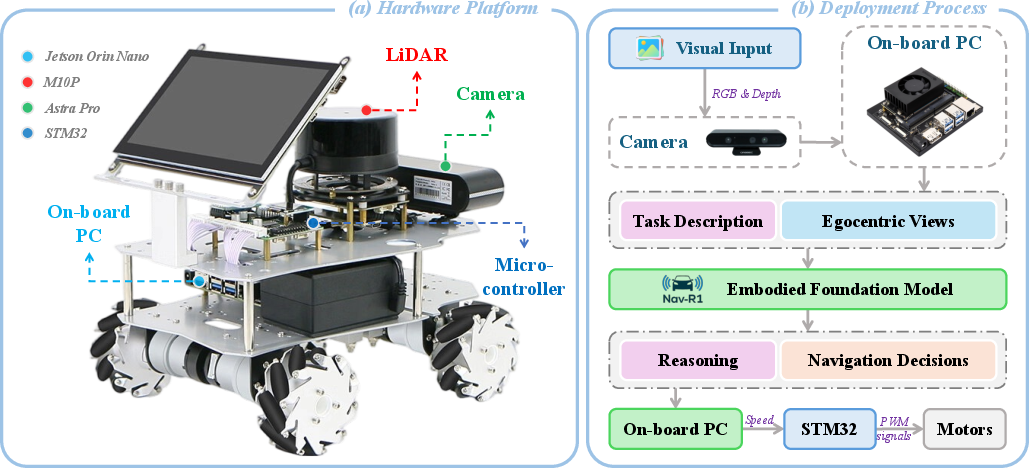
Figure 4: Real-world robot setup and deployment pipeline, detailing hardware components and cloud-assisted inference for embodied navigation.
Nav-R1 demonstrates robust performance across diverse indoor environments (meeting room, lounge, corridor), consistently outperforming strong baselines in navigation error and success rate.

Figure 5: Qualitative results from real-world deployment, showing BEV trajectories and ego-centric video frames in three indoor scenarios.
Experimental Results and Ablation Studies
Nav-R1 achieves strong results across embodied navigation, dialogue, reasoning, and planning benchmarks. On R2R-CE and RxR-CE, Nav-R1 outperforms all methods not relying on simulator pre-trained waypoint predictors, even when those methods use additional inputs. On HM3D-OVON, Nav-R1 achieves the highest success rate and SPL among zero-shot methods.
Ablation studies confirm the effectiveness of the dual-system design and the necessity of all three reward functions. Removing any reward or system component leads to significant performance degradation, highlighting the complementary nature of the architecture and training objectives.
Implementation Details
Nav-R1 is initialized from a pre-trained 3D-R1 backbone and fine-tuned on Nav-CoT-110K using supervised learning. RL fine-tuning with GRPO is performed with parameter-efficient LoRA adapters, reducing trainable parameters by $\sim$98\%. All experiments are conducted on 4$\times$NVIDIA H20 GPUs.
Limitations and Future Directions
Nav-R1's limitations include reliance on synthetic data derived from existing benchmarks, lack of integration of richer modalities (e.g., audio, tactile), and dependence on cloud inference for real-time deployment. Future work should focus on expanding data coverage, incorporating additional sensory modalities, improving on-board efficiency, and extending to longer-horizon and more diverse embodied tasks.
Conclusion
Nav-R1 presents a unified framework for embodied reasoning and navigation, integrating a Fast-in-Slow dual-system architecture, large-scale CoT supervision, and multi-dimensional RL rewards. The model achieves consistent improvements in navigation success, trajectory fidelity, and reasoning coherence, validated in both simulation and real-world deployment. The work establishes a robust foundation for future research in embodied AI, with promising directions in multimodal integration, efficient edge deployment, and generalization to complex real-world scenarios.

