- The paper introduces a unified visuomotor imitation framework that leverages consistency flow training to generate efficient robot manipulation policies.
- It employs an innovative DiT-X transformer architecture with Beta time sampling, addressing inference inefficiencies and generalization issues.
- Results demonstrate significant performance improvements on multi-task benchmarks and real-world platforms, achieving robust and efficient dexterous control.
ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training
Introduction and Motivation
ManiFlow presents a unified visuomotor imitation learning framework for general robot manipulation, targeting high-dimensional, dexterous action generation conditioned on multi-modal inputs (visual, language, proprioceptive). The method leverages flow matching with a continuous-time consistency training objective, enabling efficient and robust policy learning for complex manipulation tasks, including bimanual and humanoid scenarios. ManiFlow addresses key limitations of prior flow matching and diffusion-based policies, such as inference inefficiency, poor generalization, and inadequate multi-modal conditioning, by introducing architectural and algorithmic innovations.
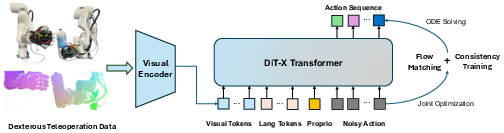
Figure 1: ManiFlow policy architecture processes 2D/3D visual, robot state, and language inputs, outputting action sequences via a DiT-X transformer and flow matching with consistency training.
Methodology
Flow Matching and Consistency Training
ManiFlow builds upon the flow matching paradigm, where the policy learns to predict the velocity from noise to data along a straight ODE path. The core loss is:
LFM(θ)=Ex0,x1∼D[∥vθ(xt,t)−(x1−x0)∥2]
To improve sample efficiency and enable few-step inference, ManiFlow incorporates a continuous-time consistency training objective. This enforces self-consistency along the ODE trajectory, allowing the model to generate high-quality actions in 1-2 inference steps without teacher distillation. The consistency loss is:
LCT(θ)=Et,Δt∼U[0,1][∥vθ(xt,t,Δt)−v~target∥2]
The training alternates between flow matching and consistency objectives, with EMA stabilization for target velocity estimation.
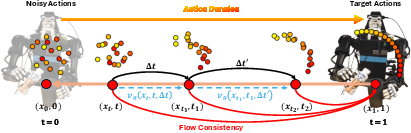
Figure 2: ManiFlow consistency training samples intermediate points along the flow path, enforcing self-consistency and accurate mapping to the target.
Time Space Sampling Strategies
ManiFlow systematically ablates timestep sampling strategies, demonstrating that Beta distribution sampling (emphasizing high-noise regime) yields superior performance for robotic control compared to uniform, logit-normal, mode, and cosine-mapped schedules. Continuous Δt sampling further improves consistency training efficacy.
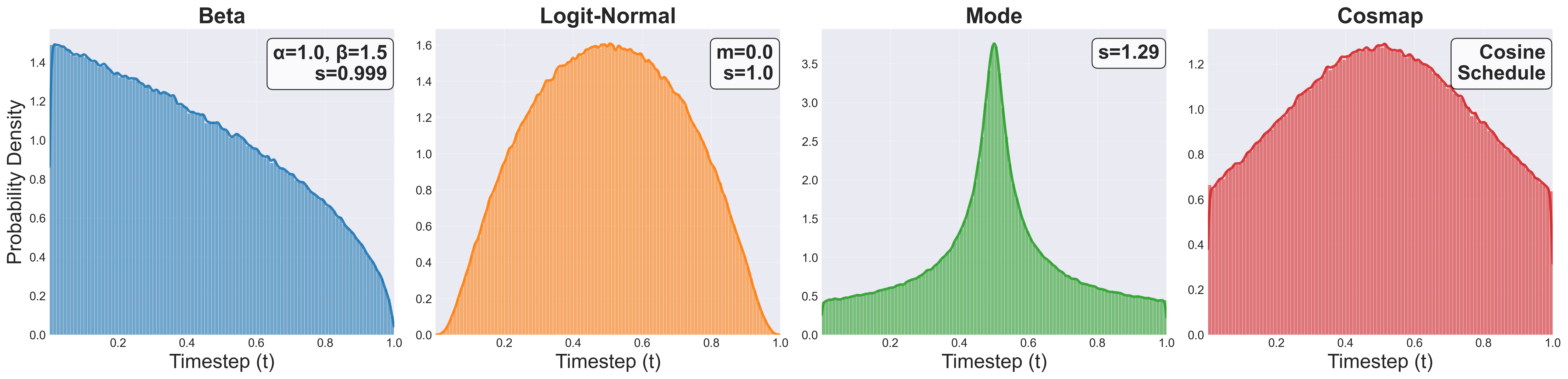
Figure 3: Comparison of timestep sampling strategies for flow matching, highlighting the empirical and theoretical distributions for Beta, logit-Normal, Mode, and Cosmap.
The DiT-X block extends the DiT and MDT architectures by introducing AdaLN-Zero conditioning to both self-attention and cross-attention layers. This enables adaptive, fine-grained feature modulation between action tokens and multi-modal inputs, crucial for handling low-dimensional control signals and high-dimensional perceptual/language features.
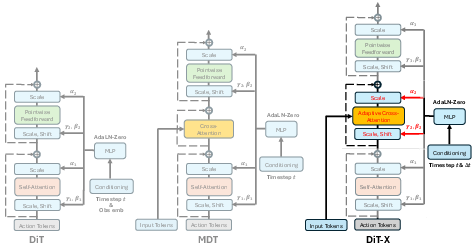
Figure 4: DiT-X block applies AdaLN-Zero conditioning to cross-attention, enabling adaptive feature interactions for multi-modal policy learning.
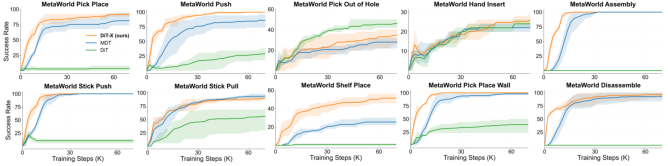
Figure 5: DiT-X achieves faster convergence and higher accuracy in language-conditioned multi-task learning compared to DiT and MDT baselines.
Perception and Multi-Modal Conditioning
ManiFlow supports both 2D image and 3D point cloud inputs. The 3D encoder eschews max pooling to preserve fine-grained geometric information, critical for dexterous manipulation. Empirical results show strong performance with sparse point clouds (128 points) in calibrated scenes and improved robustness with denser clouds (4096 points) in unstructured environments. Color augmentation is essential for generalization in real-world deployment.
Experimental Results
Simulation Benchmarks
ManiFlow is evaluated on Adroit, DexArt, RoboTwin, and MetaWorld, covering single-arm, bimanual, and language-conditioned multi-task scenarios. ManiFlow consistently outperforms diffusion and flow matching baselines:
Robustness and Generalization
ManiFlow demonstrates strong generalization to novel objects, backgrounds, and environmental perturbations, outperforming large-scale pre-trained models (π0) in domain randomized bimanual tasks.

Figure 7: Visualization of domain randomized evaluation on RoboTwin 2.0, including clutter, novel objects, lighting, and table height changes.
Real-World Experiments
ManiFlow is deployed on Franka, bimanual xArm, and Unitree H1 humanoid platforms, achieving 69.6% average success rate across 8 tasks—almost double that of DP3. ManiFlow excels in high-dexterity tasks (pouring, handover, sorting) and adapts to unseen objects and scene variations.
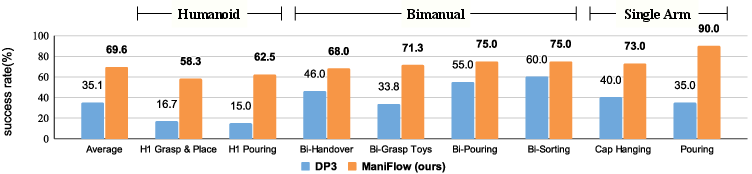

Figure 8: Real-robot results across three platforms, with ManiFlow nearly doubling DP3's performance and robust execution visualized in 3D point clouds.

Figure 9: ManiFlow maintains robustness under real-world perturbations, including viewpoint changes, novel objects, and distractors.
Ablations and Scaling
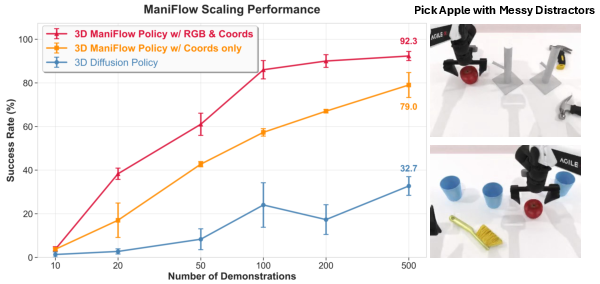
ManiFlow achieves high success rates with only 1-2 inference steps, compared to 10 steps required by diffusion/flow matching baselines. The DiT-X block and Beta time sampling are critical for performance. ManiFlow exhibits strong scaling behavior, leveraging larger datasets more effectively than prior models.
Implementation Considerations
- Computational Requirements: ManiFlow's DiT-X block introduces modest overhead but is offset by reduced inference steps and improved sample efficiency.
- Deployment: Supports both 2D and 3D visual modalities, with flexible action horizon and observation history. EMA stabilization is essential for consistency training.
- Limitations: Performance in contact-rich tasks is limited by lack of tactile sensing; future work should integrate tactile and VLM-based modalities.
Implications and Future Directions
ManiFlow demonstrates that consistency flow training and adaptive transformer architectures can substantially improve dexterous manipulation policy learning, enabling robust, efficient, and generalizable control from limited demonstrations. The approach is extensible to other domains (navigation, mobile manipulation) and can benefit from integration with reinforcement learning and additional sensory modalities.
Conclusion
ManiFlow advances the state-of-the-art in general robot manipulation by combining flow matching with continuous-time consistency training and a novel DiT-X transformer architecture. The method achieves strong empirical results across simulation and real-world benchmarks, particularly in challenging dexterous and bimanual tasks. ManiFlow's architectural and algorithmic innovations set a new standard for efficient, robust, and scalable policy learning in robotics.