- The paper presents 3DGPE, a novel encoder that replaces per-point MLPs with learned 3D Gaussian mixtures for efficient, explicit geometric embeddings.
- It employs natural gradient optimization and knowledge distillation from PointNet to stabilize training and achieve competitive accuracy.
- The architecture significantly reduces FLOPs, memory usage, and latency, making it ideal for real-time and resource-limited 3D perception tasks.
3D Gaussian Point Encoders: An Explicit 3D Geometry-Inspired Architecture for Efficient Point Cloud Processing
Introduction
3D point cloud processing remains foundational for robotics, autonomous vehicles, and 3D perception, with deep architectures such as PointNet defining the standard for permutation-invariant representations. Despite PointNet's success, its per-point embedding phase—built around large per-point MLPs—remains a critical computational bottleneck, particularly on low-power or real-time platforms. This paper presents the 3D Gaussian Point Encoder (3DGPE), an explicit, parameter-efficient embedding architecture leveraging mixtures of learned 3D Gaussians. Unlike recent implicit methods, 3DGPE directly encodes explicit geometric structure, and through advances in optimization and geometric filtering, achieves comparable accuracy to traditional methods with significantly greater efficiency.
3DGPE Architecture
3DGPE replaces PointNet’s implicit per-point MLP embedding with a two-stage process:
- Gaussian Basis Encoder computes the likelihood of each input 3D point under a set of learned anisotropic Gaussians.
- Gaussian Basis Mixer linearly combines these likelihoods, producing expressive per-point embeddings for each activation volume, which are subsequently aggregated via max-pooling.
This architecture is illustrated in Figure 1:
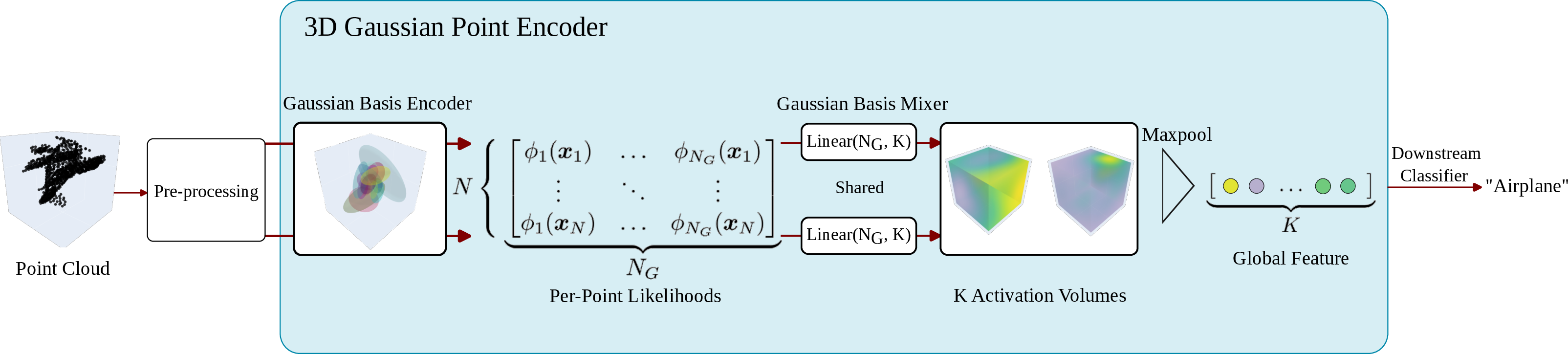
Figure 1: Schematic of the 3DGPE pipeline, from input pre-processing to max-pooling and classification.
Parameterizing the precision matrices via Cholesky decomposition ensures positive semi-definiteness, and using explicit mixtures allows the network to exploit the volumetric modeling capacity of Gaussians, yielding a lightweight, highly expressive descriptor.
Optimization Strategies
Direct end-to-end optimization of Gaussian parameters with standard optimizers, e.g., Adam, proved unstable and sub-optimal; two alternative strategies delivered robust solutions:
- Natural Gradient Optimization leverages Riemannian geometry, preconditioning parameter updates with either the Mahalanobis or Fisher Information metrics. For Gaussian means, updates involve pre-multiplication by the (inverse) covariance, directly capturing the local curvature of the parameter space.
- Knowledge Distillation from PointNet utilizes a frozen, pre-trained PointNet teacher as a target. 3DGPE is trained to minimize the L1 discrepancy in per-point embedding space, before fine-tuning task performance end-to-end.
A detailed illustration of the distillation setup is provided in Figure 2:
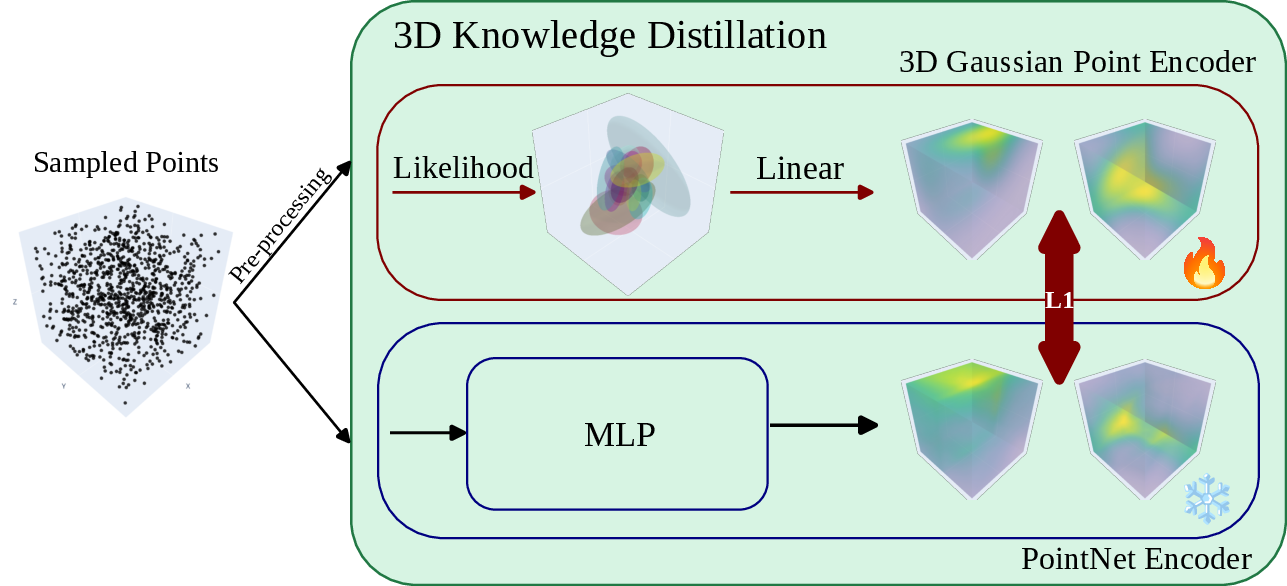
Figure 2: The explicit distillation procedure from PointNet to 3DGPE, aligning feature spaces pointwise.
Natural gradients significantly stabilized training even for low-dimensional Gaussian mixtures, while distillation proved necessary for matching the representational power of implicit MLP activations in challenging conditions (e.g., real-world ScanObjectNN data).
Computational Acceleration via Explicit Geometry
The explicit structure of 3DGPE enables computational geometry-based filtering, analogous to Gaussian Splatting in view synthesis. Most Gaussian-point pair likelihoods are negligible and can be pruned, reducing unnecessary FLOPs. Three principal heuristics are proposed:
- Distance Filtering: Only evaluate likelihoods within a Euclidean radius from each Gaussian's mean.
- Bounding-box Filtering: Use the minimal axis-aligned bounding box to prune unlikely pairs.
- Voxel Filtering: Precompute and cache maximal likelihood Gaussians per spatial voxel for fast list lookup.
These strategies, depicted in Figure 3, yield substantial FLOP and runtime reductions—up to 2.7× over PointNet.
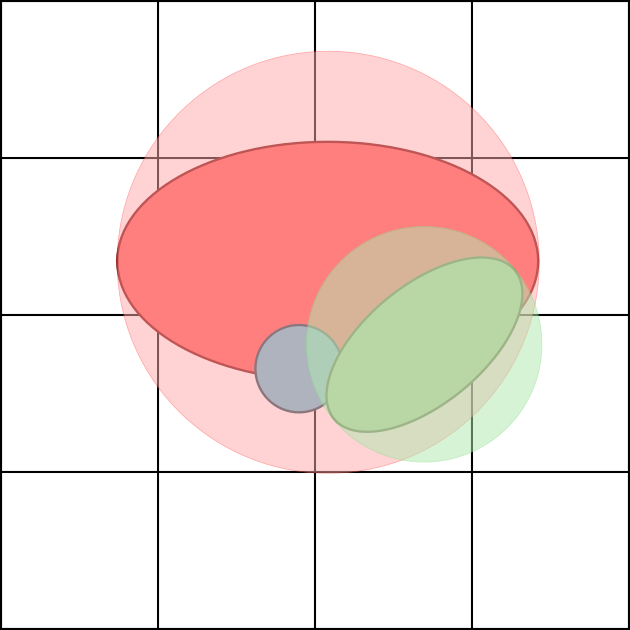
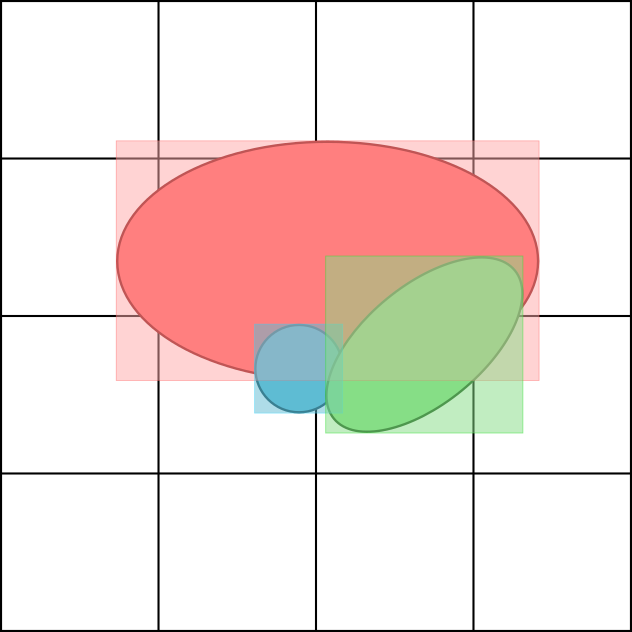
Figure 3: Visualization of three Gaussian-point filtering schemes: distance, bounding-box, and voxel-based pruning.
Empirical Evaluation
3DGPE was benchmarked on shape classification tasks on ModelNet40 and ScanObjectNN, integrated both as a PointNet-replacement encoder and as a patch embedding module in Mamba3D. Results demonstrated:
- Accuracy: 3DGPE matches or slightly outperforms PointNet on ModelNet40 (OA: 90.3% vs. 90.0%) and achieves statistically indistinguishable performance on ScanObjectNN.
- Efficiency: Compared to PointNet, 3DGPE achieves 2.7× faster throughput and 46% lower memory requirements. When used as a patch encoder in Mamba3D, throughput is increased by 1.27×, and both memory and FLOPs are halved.
- Latency: On ARM CPUs and mobile GPUs, 3DGPE substantially reduces inference time versus GPointNet and LUTI-MLP, whose FLOPs efficiency does not translate to wallclock speed due to unfavorable memory and access patterns.
Ablation and Analysis
Ablations reveal:
- Increasing the number of Gaussians, NG, beyond 32 yields diminishing returns in accuracy.
- Fixing covariance parameters, especially restricting to diagonal or identity, causes sharp performance drops, confirming the necessity of full Gaussian parameterization.
- Training with natural gradients or distillation yields higher accuracy and lower variance than with Adam or SOAP, for similar or lower model sizes.
Implications and Future Directions
The explicit, geometric design of 3DGPE facilitates modular integration with novel sequence models (e.g., Mamba3D), supports computational geometry-based filtering for performance optimization, and directly aligns with emerging trends in 3D view synthesis (e.g., 3D Gaussian Splatting vs. NeRF). In theory, such explicit encoders may generalize more robustly in settings where geometric priors or constraints are crucial.
Despite its advantages, 3DGPE's efficacy relies on advanced optimization methods. The approach may struggle when implicit representations are necessary, or when scaling to higher-dimensional input attributes, such as full semantic segmentation workflows.
Conclusion
The 3D Gaussian Point Encoder represents a shift toward explicit, parameter-efficient, and optimizable geometric embeddings for 3D point cloud analysis. It achieves the efficiency of lookup-based and Gaussian architectures while matching or exceeding the accuracy of PointNet, and is practically viable for deployment in real-time and resource-limited environments. Future directions include adaptation for tasks beyond classification, hierarchical scene understanding, and direct end-to-end optimization for complex detection or segmentation regimes.