- The paper introduces GPiCA, a hybrid model that fuses triangle meshes with anisotropic 3D Gaussians to render photorealistic head avatars efficiently.
- It employs joint neural training and a custom two-pass differentiable renderer, achieving high-quality reconstruction using only 16k Gaussians.
- Empirical results show improved memory efficiency and lower latency on mobile devices, setting a new benchmark for AR/VR avatar rendering.
Gaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering
Introduction and Motivation
Efficient and high-fidelity rendering of photorealistic head avatars is a persistent challenge, particularly under the compute and memory constraints inherent to mobile AR/VR devices. "Gaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering" (2512.15711) introduces Gaussian Pixel Codec Avatars (GPiCA), a novel architecture that tightly integrates a triangle mesh and anisotropic 3D Gaussians as complementary scene representations. The hybrid paradigm is specifically engineered to achieve photorealistic appearance for human head avatars at low computational cost, overcoming the inherent limitations of both mesh-only and 3D Gaussian-only approaches—namely, the mesh’s incapacity for volumetric phenomena (e.g., hair) and the memory/rate-performance trade-offs associated with 3D Gaussian splatting.
The motivation is clear: rendering realistic human avatars on edge devices, such as wireless VR headsets, requires adaptively optimizing representation capacity while strictly limiting render-time and memory footprint.
Hybrid Mesh-Gaussian Representation and Pipeline
GPiCA leverages the distinctive strengths of meshes and Gaussians. The mesh efficiently and compactly encodes the coarse facial surface geometry and texture, enabling high-speed, low-memory rendering for the core skin regions. Meanwhile, a set of anisotropic 3D Gaussians, placed relative to this mesh, captures volumetric and fine-detailed appearance in regions where meshes perform poorly (notably hair, beards, eyelashes). This division of representational labor is enforced and optimized via joint neural training.
At inference, given a latent code and view direction, the system decodes a per-frame mesh in UV space, a corresponding RGBA texture, and a sparse set of 3D Gaussian primitives localized in morphologically complex areas.
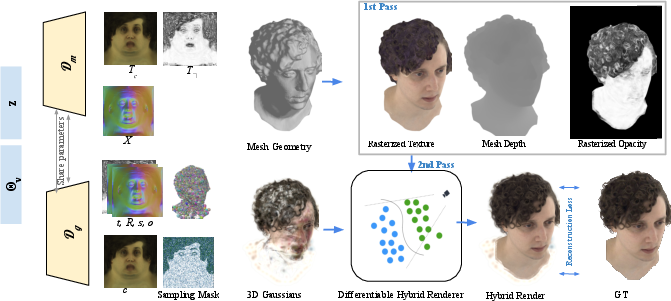
Figure 1: The GPiCA pipeline fuses mesh and Gaussian representations conditioned on a latent expression code, rasterizing and compositing their outputs in a custom two-pass differentiable renderer.
The rendering process is performed in two passes. First, the mesh is rasterized to generate per-pixel RGB, alpha, and depth—forming a semi-transparent basis layer. Next, the Gaussian primitives are composited in depth-aware, front-to-back order with the mesh results. The renderer accounts for Gaussians both in front of and behind the mesh, enabling correct volumetric effects without suffering the semi-transparency problems that undermine vanilla 3DGS on opaque regions.
The architecture revolves around a variational autoencoder: the encoder integrates coarse multi-view mesh tracking and unwrapped textures, producing a latent facial expression code. The decoder stack consists of two modules (both operating in the shared UV space): one for predicting mesh geometry and RGBA texture, and the other for parameterizing the 3D Gaussians (position, rotation, scale, opacity, color)—with explicit sharing of computational features. Placement of Gaussians is regularized to focus on non-surface areas, using semantic segmentation in UV space to allocate the sparse Gaussian budget to challenging regions such as hair.
The hybrid renderer composites colors as follows: accumulate Gaussians in front of the mesh, then the mesh’s own color/opacity, followed by background Gaussians, appropriately weighing each by per-splat and mesh transparencies.

Figure 3: Decomposition showing mesh (green) and Gaussian (blue) RGBA contributions, illustrating how volumetric regions are handled by Gaussians while the mesh manages the main surface.
The system is trained end-to-end with multi-view supervision, using MSE reconstruction loss, KL-regularization on the latent space, and explicit geometric regularization on Gaussian scale, proximity to the mesh, and mesh smoothness.
Empirical Evaluation
GPiCA’s empirical results demonstrate robust advantages on multiple fronts:
- Quality vs. Efficiency: With only 16,384 Gaussians, the hybrid model matches or surpasses baseline vanilla 3DGS models that require 4× more (65,536) Gaussians for comparable reconstruction quality (as measured by LPIPS, MAE, PSNR, and SSIM). The hybrid achieves LPIPS 0.33 with 16k Gaussians, outperforming mesh-only and matching—or exceeding—vanilla 3DGS at 65k splats.
- Rendering Performance: On a mobile Quest 3 headset GPU, the hybrid model maintains rendering times on the order of 10.9 ms (16k splats), whereas 65k vanilla 3DGS incurs 19.3 ms. Pure mesh rendering is fastest but of inferior quality for volumetric details.
- Ablation Studies: GPiCA’s use of a semi-transparent mesh (versus opaque mesh in prior hybrid techniques) directly enables more accurate volumetric modeling, especially in hair regions. Both uniform and hair-biased initialization of Gaussians were compared; biasing yields material improvements in target regions.
- Full-Body Scalability: In full-body settings, GPiCA with 16k Gaussians outperforms solely mesh-based and opaque hybrid baselines, with 16-fold fewer Gaussians than high-fidelity vanilla 3DGS.
Discussion and Implications
GPiCA’s hybrid mesh-Gaussian representation resolves two interrelated challenges in animatable head avatar rendering: the high memory/performance cost of pure 3DGS and the representational inadequacy of mesh-only models for volumetric phenomena. By design, it exploits mesh hardware rasterization for surface regions but seamlessly integrates volumetric effects for hair, beards, and similar features via 3D Gaussian splats, using a compute-constrained, two-pass differentiable renderer.
Strong quantitative and qualitative results across datasets, and direct runtime measurements on real mobile VR hardware, position the approach as a compelling path forward for low-latency, photorealistic avatar rendering in AR/VR telepresence and telecommunication.
Figure 4: Visualization of per-primitive contributions—top: learned mesh normals; middle: locations of learned Gaussians; bottom: final composed renderings.
Theoretically, the hybrid approach could generalize to other domains—full-body avatars, complex object reconstruction, or generalized scene rendering—by adaptively drawing on the strengths of geometric (mesh) and volumetric (Gaussian) representations, and guiding their interaction through joint training and region-based prioritization. Integration with real-time relighting or dynamic scene editing is feasible, given the differentiability and compactness of the learned representations.
Conclusion
Gaussian Pixel Codec Avatars (GPiCA) establish a unifying paradigm for efficient and expressive 3D head avatar rendering, leveraging the hardware-friendliness of meshes and the representational power of sparse, spatially-allocated Gaussians. The system achieves mobile-class rendering speeds and memory efficiency without sacrificing realism, particularly in volumetric regions. This hybrid approach sets a new benchmark for resource-adaptive avatar rendering and constitutes an essential building block for next-generation immersive telepresence systems (2512.15711).

