Plug-and-Play PDE Optimization for 3D Gaussian Splatting: Toward High-Quality Rendering and Reconstruction
Abstract: 3D Gaussian Splatting (3DGS) has revolutionized radiance field reconstruction by achieving high-quality novel view synthesis with fast rendering speed, introducing 3D Gaussian primitives to represent the scene. However, 3DGS encounters blurring and floaters when applied to complex scenes, caused by the reconstruction of redundant and ambiguous geometric structures. We attribute this issue to the unstable optimization of the Gaussians. To address this limitation, we present a plug-and-play PDE-based optimization method that overcomes the optimization constraints of 3DGS-based approaches in various tasks, such as novel view synthesis and surface reconstruction. Firstly, we theoretically derive that the 3DGS optimization procedure can be modeled as a PDE, and introduce a viscous term to ensure stable optimization. Secondly, we use the Material Point Method (MPM) to obtain a stable numerical solution of the PDE, which enhances both global and local constraints. Additionally, an effective Gaussian densification strategy and particle constraints are introduced to ensure fine-grained details. Extensive qualitative and quantitative experiments confirm that our method achieves state-of-the-art rendering and reconstruction quality.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making 3D scenes look sharper and more stable when we create new camera views from photos. It builds on a fast method called 3D Gaussian Splatting (3DGS), which represents a scene using many soft, colored blobs in 3D. While 3DGS is fast and can look great, it often gets blurry or shows little “floaters” (tiny fake bits) in tricky scenes. The authors propose a new, plug-and-play way to improve how 3DGS learns, so it avoids blur and floaters and produces cleaner, more accurate 3D renderings and reconstructions.
What questions does the paper ask?
The paper focuses on three simple questions:
- Why does 3DGS sometimes produce blur and floaters, especially in complex scenes?
- How can we make the training process of these tiny 3D blobs more stable, without throwing away useful information?
- Can a single improvement be plugged into many existing 3DGS-based methods to boost both rendering quality (how images look) and reconstruction quality (how accurate the 3D shape is)?
How does the method work?
Think of the method as teaching a crowd of “fireflies” (the 3D blobs) how to stand in the right places to match the real scene when viewed from different cameras. The problem is that the small fireflies move too quickly and unpredictably, causing messiness. The authors add rules that make their movement smoother and more coordinated.
Here are the key ideas, using everyday analogies:
- 3D Gaussian Splatting (3DGS): The scene is made of many soft 3D blobs (like translucent paint drops), each with a position, size, color, and transparency. When you “splat” them onto the camera screen and blend them, you get an image. Training means adjusting each blob so the rendered image matches the real photos.
- The instability problem: For very small blobs, the “move” signal (the position gradient) is much stronger than the other signals (like color or size). So they zip around too fast, causing blur and fake floating bits.
- Modeling training as a PDE (a rule of motion over time): A PDE (Partial Differential Equation) is a math rule that says how things change over time (like how water flows). The authors show that the usual 3DGS training steps are basically the same as following a PDE that updates each blob over time.
- Adding “viscosity” like honey: To stop blobs from jumping around, they add a viscosity term, similar to thickness in fluids. Imagine the blobs are moving through honey, not air, so sudden moves get smoothed out. This calms the training and keeps blobs from making wild jumps.
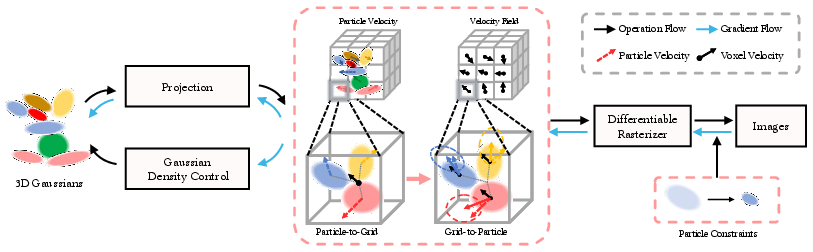
- Using the Material Point Method (MPM) to stabilize movement:
- Particles (the blobs themselves)
- A grid (like a 3D city map divided into small cubes)
With two steps: - Particle-to-Grid (P2G): Blobs share some of their extra motion with the grid cells they’re in. This stores a “local average movement” in each cell. - Grid-to-Particle (G2P): Blobs then get gentle guidance back from the grid, nudging their motion to be closer to the average of their neighbors. This is how viscosity is applied in practice.
- Extra rules to improve details:
- Scale loss: Encourages blobs not to become too big. Big blobs cover too much space and cause blur; small blobs capture details better.
- Confidence loss: Pushes transparency to be clearly “solid” or “not there,” avoiding half-transparent blobs that break the “particle” idea and cause haze.
- Smarter densification: When adding new blobs to fill in missing detail, they use motion alignment (comparing the blob’s motion with the grid’s motion) to decide where and when to add them, making this step more accurate.
Because this method changes the optimization process, not the rendering model itself, it is “plug-and-play”: you can drop it into many different 3DGS-style systems.
What did they find?
- Cleaner images with fewer artifacts: The method reduces blur and floaters, producing sharper edges and more faithful textures.
- Better 3D geometry: For surface reconstruction (turning the scene into a detailed 3D shape), it delivers more accurate and smoother surfaces.
- Works across many datasets and methods: The authors plugged their approach into several state-of-the-art 3DGS-based systems. In most cases, it improved standard quality scores for images (like PSNR, SSIM, LPIPS) and for 3D geometry (like Chamfer Distance and F1 score).
- Stable and efficient: The viscosity-based training is more stable. In many setups, it also reduced memory use or improved speed because it avoids bloated, redundant blobs.
Why this matters: Stability during training means fewer fake details and crisper, more trustworthy results. This makes 3DGS more practical for real applications.
Why is this important?
Better and more stable 3D scene representations help many areas:
- Virtual and augmented reality: More convincing scenes with fewer glitches.
- Games and movies: Faster, high-quality rendering of realistic environments.
- Robotics and mapping: More accurate 3D reconstructions to navigate and understand spaces.
Because the method can be added to existing systems without rewriting everything, it can quickly benefit lots of projects.
Limitations and future directions
- No rotation control yet: The current method doesn’t directly handle how blobs rotate. Adding rotation guidance could improve the results further.
- Filling big missing areas is hard: If the starting points are missing in some regions, it’s still difficult to move blobs in to fill those holes. Future work could improve how the system discovers and fills such gaps.
Takeaway
3D Gaussian Splatting is fast and promising, but it can be unstable, causing blur and floaters. This paper treats training like a fluid moving through honey: the added “viscosity” and grid guidance calm the blobs down, making them move smarter, not wilder. The result is sharper images and better 3D geometry, and the method can be plugged into many existing 3DGS systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed to guide future research.
- Theoretical rigor of the PDE formulation: clarify assumptions and provide a complete, verifiable derivation linking standard 3DGS optimization (which often uses Adam/learning-rate schedules/momentum) to the proposed continuous-time PDE; specify conditions under which Eq. (11) holds, including treatment of nonstationary gradients, occlusions, and depth ordering.
- Convergence and stability guarantees: establish formal bounds or proofs for stability and convergence of the viscous PDE discretization (with P2G/G2P), including how viscosity affects fixed points and whether the procedure remains a descent method on the original loss.
- Asymptotic-equivalence claim: rigorously test and prove the assertion that adding viscosity “does not change the solution as t → ∞,” especially in practical, discretized, noisy optimization where L ≠ 0 and early stopping is used.
- Interplay with common optimizers: characterize how the proposed PDEO interacts with Adam/AdamW, learning-rate schedules, gradient clipping, and weight decay; determine whether PDEO replaces, complements, or conflicts with these practices.
- Minimal baselines for fairness: benchmark PDEO against simpler, computationally cheaper alternatives (e.g., per-parameter damping of position updates, neighbor-averaged position updates, Laplacian smoothing in Gaussian space, momentum tuning, adaptive gradient clipping) to isolate the specific benefit of the MPM-based viscosity.
- Scope beyond position updates: evaluate whether viscosity should also be applied to other attributes (scale, opacity, rotation, SH/color) given the identified gradient imbalance; quantify gains from extending PDEO to these attributes.
- Rotation handling: integrate and evaluate particle rotation within the MPM/PDE framework (acknowledged limitation), including how voxel grids inform rotational updates and how rotation-translation coupling affects stability.
- Grid resolution and layout: systematically study sensitivity to voxel-grid resolution, extent, and placement (world-space parameterization, unbounded scenes), including memory/runtime scaling and artifacts due to grid alignment or boundary effects.
- Weighting and mass modeling: investigate principled weighting schemes for P2G/G2P (e.g., by opacity, projected area, confidence, or photometric error) instead of uniform averaging, aligning more closely with MPM’s mass/momentum conservation.
- Kernel choices in P2G/G2P: explore different interpolation kernels (e.g., linear/B-spline weights as in standard MPM/PIC/FLIP) and their impact on stability, smoothing strength, and bias versus the current per-voxel averaging.
- Incompressibility and PDE consistency: clarify the role of the incompressibility assumption (∇v = 0) stated in Eq. (12); determine whether and how it is enforced or whether the formulation is purely an analogy to Navier–Stokes.
- CFL-like constraints and step sizing: provide practical guidance on time-step/learning-rate choices to satisfy stability conditions analogous to CFL in PDE solvers, and quantify discretization error introduced by the optimizer step.
- Hyperparameter sensitivity and scheduling: characterize robustness and automatic tuning strategies for λ_g, λ_p, β, θ_p, and loss weights (ω_s, ω_t), including scene-dependent or per-iteration adaptive schedules.
- Densification criterion clarity: resolve the specification ambiguity in the velocity-aligned densification rule (angle vs. cosine thresholding) and provide sensitivity analysis for θ_p and frequency of densify operations.
- Confidence loss differentiability: the use of L_t with floor(1.99 o_i) is non-differentiable (and yields zero gradients a.e.); clarify whether opacity is before/after sigmoid and revise with a smooth, differentiable surrogate; evaluate training stability/efficacy under different surrogates.
- Scale loss side effects: quantify trade-offs between enforcing small scales (better detail capture) and increased susceptibility to floaters or aliasing; assess whether adaptive, view-dependent scale constraints are preferable.
- Depth-discontinuity awareness: analyze whether grid-based velocity mixing can misguide updates across depth edges, causing bleeding across occlusion boundaries; explore depth-aware or multi-layer grids to decouple foreground/background velocities.
- Initialization dependence and relocation: develop mechanisms that actively propose, relocate, or synthesize Gaussians in regions poorly covered by COLMAP (acknowledged limitation), e.g., via monocular priors, learned proposal fields, or global attraction forces.
- Scalability to large/unbounded scenes: evaluate multi-resolution or sparse grid structures (octrees, hash grids) and streaming strategies to keep grid costs bounded while preserving the benefits of viscosity.
- Runtime and memory breakdown: provide detailed profiling of training and rendering overhead attributable to PDEO (grid construction, P2G/G2P), and scaling laws with number of Gaussians and grid resolution; clarify whether reported FPS is training or inference.
- Generalization to challenging regimes: test robustness on few-shot, highly sparse, or noisy camera calibrations; dynamic or non-rigid scenes; severe lighting/viewpoint extrapolation; and cross-dataset generalization.
- Effect on the loss landscape and minima: empirically analyze whether viscosity changes which minima are reached (e.g., by late-phase ablations or homotopy schedules that anneal viscosity to zero) and how this impacts geometry vs. photometry trade-offs.
- Reproducibility specifics: document exact voxel-grid parameters (resolution, bounds, kernel), optimizer settings, and random seeds; release code to facilitate replication and controlled comparisons.
- Integration with recent 3DGS variants: explore compatibility and benefits with second-order or sampling-based training schemes (e.g., 3DGS², different rasterizers), and quantify additive versus redundant gains.
- Uncertainty and confidence modeling: move beyond hard confidence/opacity binarization toward calibrated uncertainty estimates that can inform viscosity strength, weighting, and densification decisions.
- Per-particle, spatially varying viscosity: study adaptive viscosity that depends on local confidence, gradient variance, visibility, or photometric residuals to avoid over-smoothing fine structures.
- Joint rendering–geometry objectives: disentangle how viscosity-driven updates affect photometric versus geometric metrics; investigate multi-objective scheduling that preserves edges while reducing floaters.
- Failure case analysis: systematically characterize scenes where PDEO underperforms (e.g., specular/transparent surfaces, highly repetitive textures) and diagnose whether issues stem from viscosity, densification, or loss design.
Collections
Sign up for free to add this paper to one or more collections.

