- The paper introduces a hierarchical autoregressive framework that replaces sequential token scanning with multi-scale latent streams.
- The methodology partitions token states into compressed chunks, achieving up to 10x memory reduction and 45x throughput improvement.
- Empirical results demonstrate over 1000x improvements in throughput-per-memory, highlighting its potential for memory-constrained LLM deployments.
PHOTON: Hierarchical Autoregressive Modeling for Lightspeed and Memory-Efficient Language Generation
Introduction and Motivation
Standard Transformer-based LMs are fundamentally limited by the horizontal, token-by-token scanning approach: every generation step sequentially attends to an ever-growing, flat history of token states. Inference in these models is bottlenecked by KV-cache reads and writes, especially as context windows and batch sizes scale upward in long-context, multi-query workloads. Despite numerous attempts at kernel-level and local attention optimizations, no prior architectural approach has effectively decoupled the exponential growth of KV-cache memory and memory traffic from sequence length during inference.
PHOTON addresses this by hierarchically organizing both representations and operations. Rather than relying on a single flat autoregressive state, PHOTON builds and maintains a vertical stack of latent streams at multiple granularities. A bottom-up encoder aggregates fine-grained token states into increasingly compressed latent units, while generation proceeds with a top-down decoder that locally reconstructs token-level detail from these coarse latent abstractions, strictly confining autoregressive attention to bounded chunks and decoupling compute/memory complexity from context length.
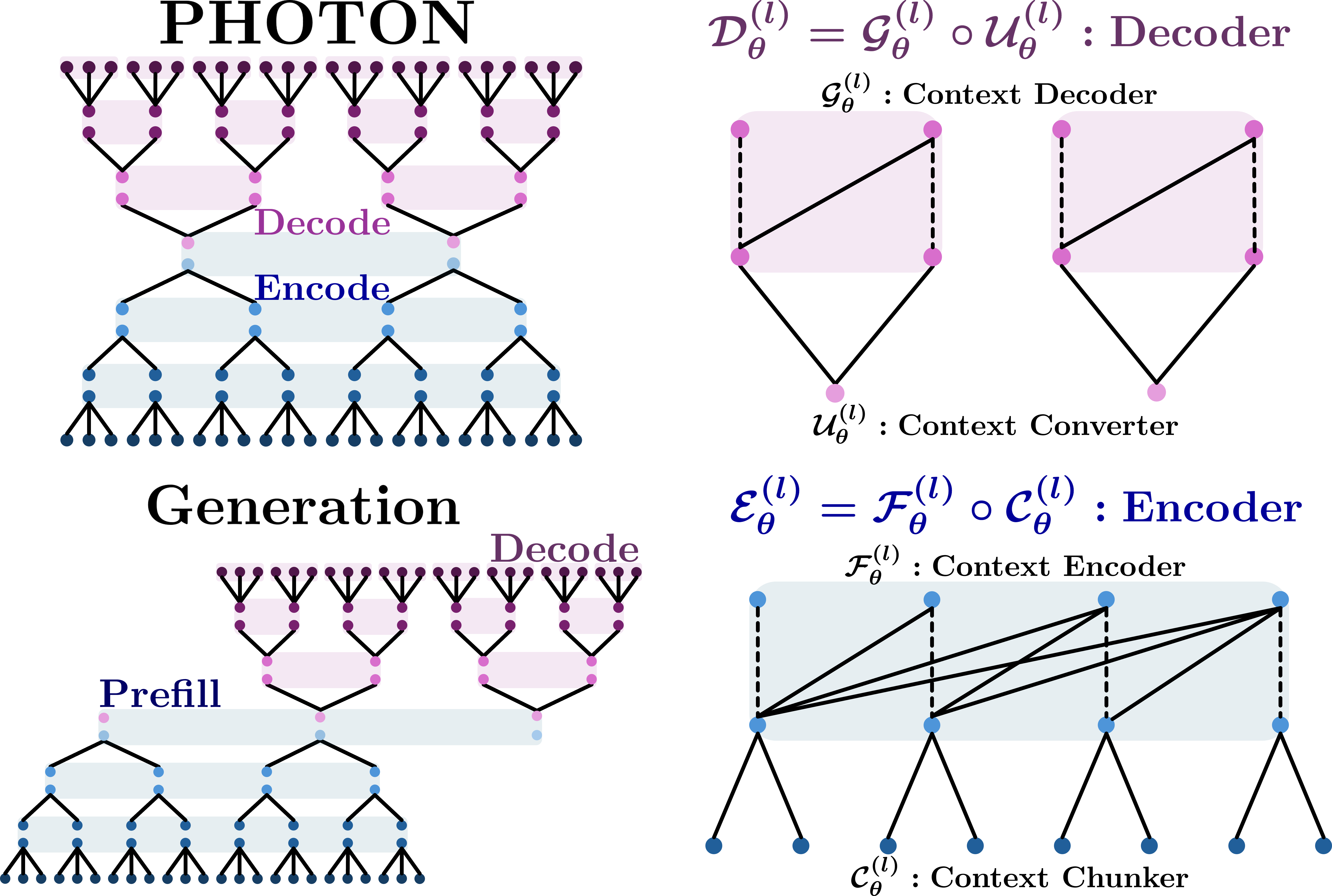
Figure 1: Overview of PHOTON's vertical hierarchy. The encoder progressively compresses token sequences, while the decoder reconstructs them locally, enabling parallel chunk-level generation and memory-efficient inference.
Model Architecture
PHOTON implements a multi-layer encoder–decoder hierarchy where each level l aggregates Cl contiguous states from the immediate lower level into coarser chunk-level latents. A standard Transformer block contextualizes these chunk representations autoregressively at each level, generating multi-scale latent abstractions.
On the generative path, each top-level chunk latent is expanded into conditioning vectors and then decoded into lower-level streams by a lightweight local Transformer with strictly chunk-local attention masks. This “vertical” information flow allows PHOTON to update only the necessary coarser latents as generation progresses, with fine-grained, parallelized decoding within each chunk, thus fundamentally reducing the amount and frequency of global KV-cache accesses during inference.
Training Objective
PHOTON is trained using standard autoregressive maximum likelihood but is stabilized and regularized by auxiliary objectives at each layer of the hierarchy. A recursive reconstruction loss enforces consistency between fine- and coarse-level encoder–decoder states. A next-context regularizer drives chunk-level latents to encode predictive, compressive summaries. All parameter updates are backpropagated through the hierarchical forward–backward stack, ensuring that each resolution in the model is aligned in both bottom-up and top-down directions.
Inference and KV-Cache Efficiency
The principal innovation of PHOTON is in inference-time efficiency. Unlike the vanilla Transformer—where both KV-cache footprint and traffic grow linearly with context length T—the multi-resolution representation in PHOTON enables:
- Global encoder/decoder layers operate on progressively compressed streams, with computational and memory costs scaling in O(∑l(T/C≤l)).
- Local decoders confine attention within chunks, yielding O(1) cost for each token within a chunk.
- Total KV-cache size and access frequency are reduced by several orders of magnitude, as the global state is updated only at coarser chunk boundaries.
Empirically this hierarchical access pattern decouples decode-time resource requirements from sequence length, resulting in significant throughput-per-memory (TPM) advancements.
Empirical Evaluation
PHOTON is evaluated against both vanilla and hierarchical blockwise Transformers—matched for parameter count and training FLOPs—across prefill-heavy and decode-heavy inference regimes. In the prefill-heavy (PF) regime, PHOTON reduces memory usage by approximately $8.9$–10× and increases throughput by $44$–45× compared to the vanilla baseline. In the decode-heavy (DE) regime, memory reduction and throughput gains of comparable magnitude are observed. These translate into TPM improvements of over three orders of magnitude (103×) relative to standard baselines.
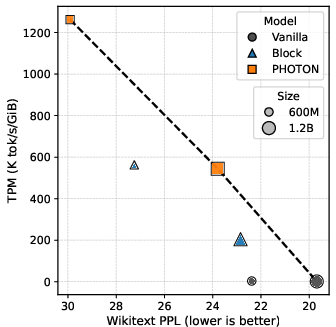
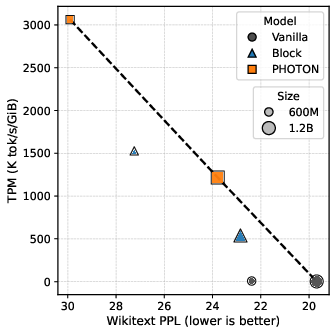
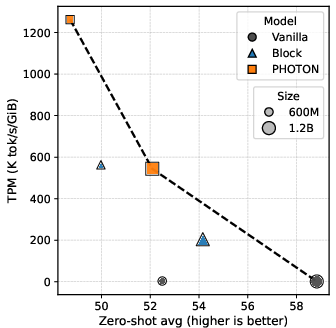
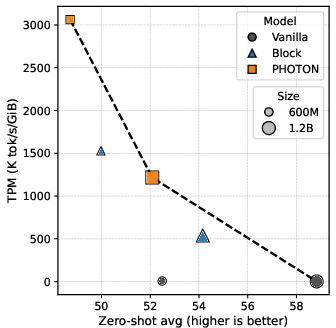
Figure 2: TPM vs. Wikitext PPL under prefill-heavy workloads. PHOTON attains higher TPM without substantial degradation in PPL.
Notably, PHOTON also dominates the Block Transformer baseline across all evaluated scales and regimes with respect to the TPM-quality Pareto frontier. For instance, the 600M PHOTON achieves TPM of 1262.58 vs. 3.24 (vanilla) and 562.73 (Block) in the PF regime, with only mild increases in Wikitext PPL (from 22.38 to 29.91). This operating regime is crucial for practical deployments where serving throughput per memory is the gating resource.
Relation to Prior Work
Earlier hierarchical or multi-scale Transformers, such as Funnel and Hourglass architectures, primarily focus on training efficiency and representation learning, with inference still dominated by horizontal, tokenwise autoregression. Meanwhile, Block Transformers and related global–local models decouple some compute across nested time axes but do not maintain persistent cross-level latent states. PHOTON extends these directions by making the hierarchy an inference-time primitive: state is maintained and updated at every resolution, and global context is accessed only when required for chunk-local generation.
Relative to sparse and dynamic token selection methods, which typically focus on reducing compute rather than KV-cache bandwidth, PHOTON reorients the design objectives squarely towards inference-time memory and traffic, a differentiator in bandwidth-constrained deployment settings.
Practical and Theoretical Implications
PHOTON’s results demonstrate the feasibility of substituting horizontal scanning with vertical, hierarchical context management, unlocking a new trade-off axis between throughput, memory consumption, and model quality. For LLM deployments constrained by memory bandwidth—such as those requiring long-context, multi-user, or edge-device inference—hierarchical stack architectures like PHOTON enable test-time scaling and parallelization otherwise unattainable by flat autoregressive baselines.
Theoretically, PHOTON implies that latent hierarchy in language generation can be exploited not only for better representations but as a mechanism for amortizing context memory and traffic, a direction so far underexplored in mainstream sequence modeling.
Limitations and Future Directions
The current study is restricted to two-level hierarchies, context windows up to 2048 tokens, and model sizes of up to 1.2B parameters. Full assessment of the scaling properties of PHOTON, especially its asymptotic advantage at larger contexts and model sizes, remains open. Richer ablations on chunk size, converter architecture, and auxiliary loss weighting are needed to understand the hierarchy’s optimal granularity and its effect on downstream generalization.
Future research should investigate extending the hierarchy to deeper stacks, evaluating in truly long-context settings (>10k tokens), and integrating with open-vocabulary or tokenizer-free domains. Hybridizing PHOTON-style hierarchies with system-level optimizations (e.g., paged KV mapping) may yield further practical gains.
Conclusion
PHOTON replaces the fundamental sequential tokenwise context scan of Transformers with an explicit, persistent, vertical hierarchy of latent streams. This rearchitecture yields dramatic reductions in KV-cache footprint and traffic, enabling orders-of-magnitude higher throughput-per-memory than existing models, particularly under prefill-heavy and decode-heavy serving workloads. The preserved controllability of the efficiency–quality frontier and scalable inference suggest that hierarchical autoregression is a robust direction for future LLM deployment and system design (2512.20687).