K2-Think: A Parameter-Efficient Reasoning System
Abstract: K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces K2-Think, an AI system that’s really good at solving hard problems, especially math, while staying small and fast. Even though it uses a “medium-size” model (32 billion parameters), it can match or beat much bigger models on tough tests. The big idea: smart training and clever test-time tricks can make a smaller model think like a much larger one.
What questions were the researchers trying to answer?
The team wanted to know:
- Can a smaller AI model reason as well as huge models if we train it the right way and give it smart tools at test time?
- Which steps during training and testing matter most for better reasoning (like planning ahead, trying multiple answers, or practicing with solutions)?
- Can we make this fast enough to be useful in real time?
- How safe and robust is the system when facing tricky or harmful prompts?
How did they build K2-Think?
They started with a public base model (Qwen2.5-32B) and added a sequence of improvements. Think of “parameters” as the model’s adjustable “brain knobs”—more knobs often help, but aren’t everything. K2-Think shows that training and strategy can matter more than just size.
Here are the six main pillars of their approach, with simple analogies:
- Long Chain-of-Thought Supervised Fine-Tuning (SFT): Like a teacher showing full worked-out solutions, step by step, so the student learns how to think, not just the final answer.
- Reinforcement Learning with Verifiable Rewards (RLVR): Like practicing with a workbook that has an answer key; the model gets a “reward” when its answer is correct, so it learns what truly works.
- Agentic Planning (“Plan-Before-You-Think”): Before solving, the model writes a mini-outline of what to do—like making a checklist before tackling a big homework problem.
- Test-time Scaling (Best-of-N sampling): The model writes several independent drafts and a judge picks the best one—like writing three short solutions and turning in the strongest.
- Speculative Decoding: The model “speaks” faster by tentatively guessing a few words ahead, then quickly checking itself—like talking fast but editing on the fly.
- Inference-optimized Hardware (Cerebras Wafer-Scale Engine): Running the model on a giant, special-purpose chip that keeps everything on hand, so it can answer much faster—like having all your notes open on one giant desk instead of searching through drawers every sentence.
A bit more on the key parts:
- Supervised Fine-Tuning (SFT): They trained the model on long, detailed solution steps (called “chain-of-thought”) from many subjects (math, coding, science, etc.). This teaches structure and clarity.
- RL with Verifiable Rewards: They focused on tasks where you can check correctness (math, code, logic, tables). If it solves a problem correctly, that’s a clear signal to learn from.
- Plan-Before-You-Think: An extra planning step turns the question into a short plan (important concepts + steps) before the model reasons. This keeps thinking focused.
- Best-of-3: For each hard question, the model tries three solutions separately. Another model compares them and picks the best. This gives a reliable boost without being too slow.
- Speed: Running on the Cerebras chip and using speculative decoding makes responses extremely fast (about 2,000 tokens—think “words”—per second), even with long step-by-step answers.
What did they find?
- Strong math performance with a smaller model:
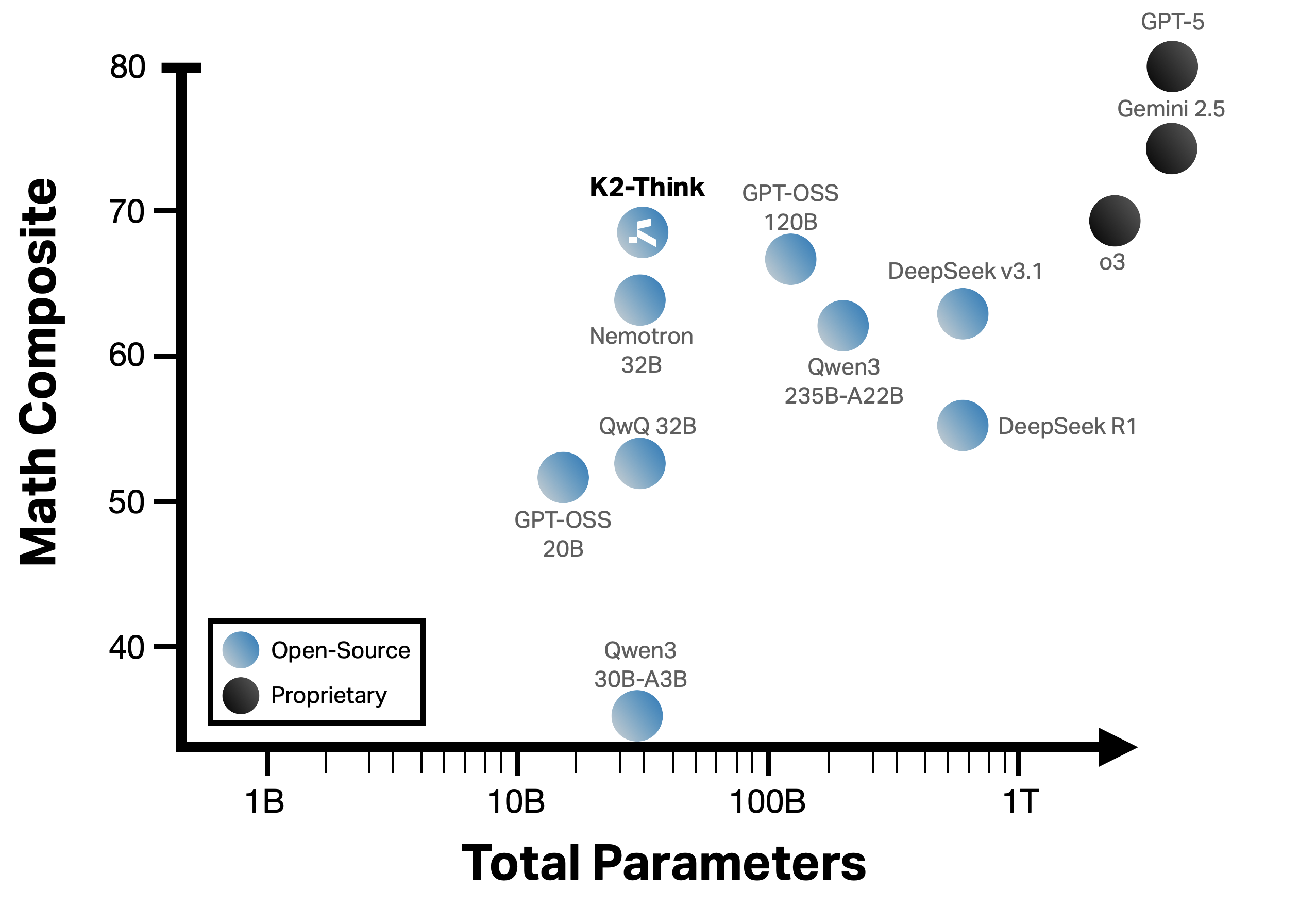
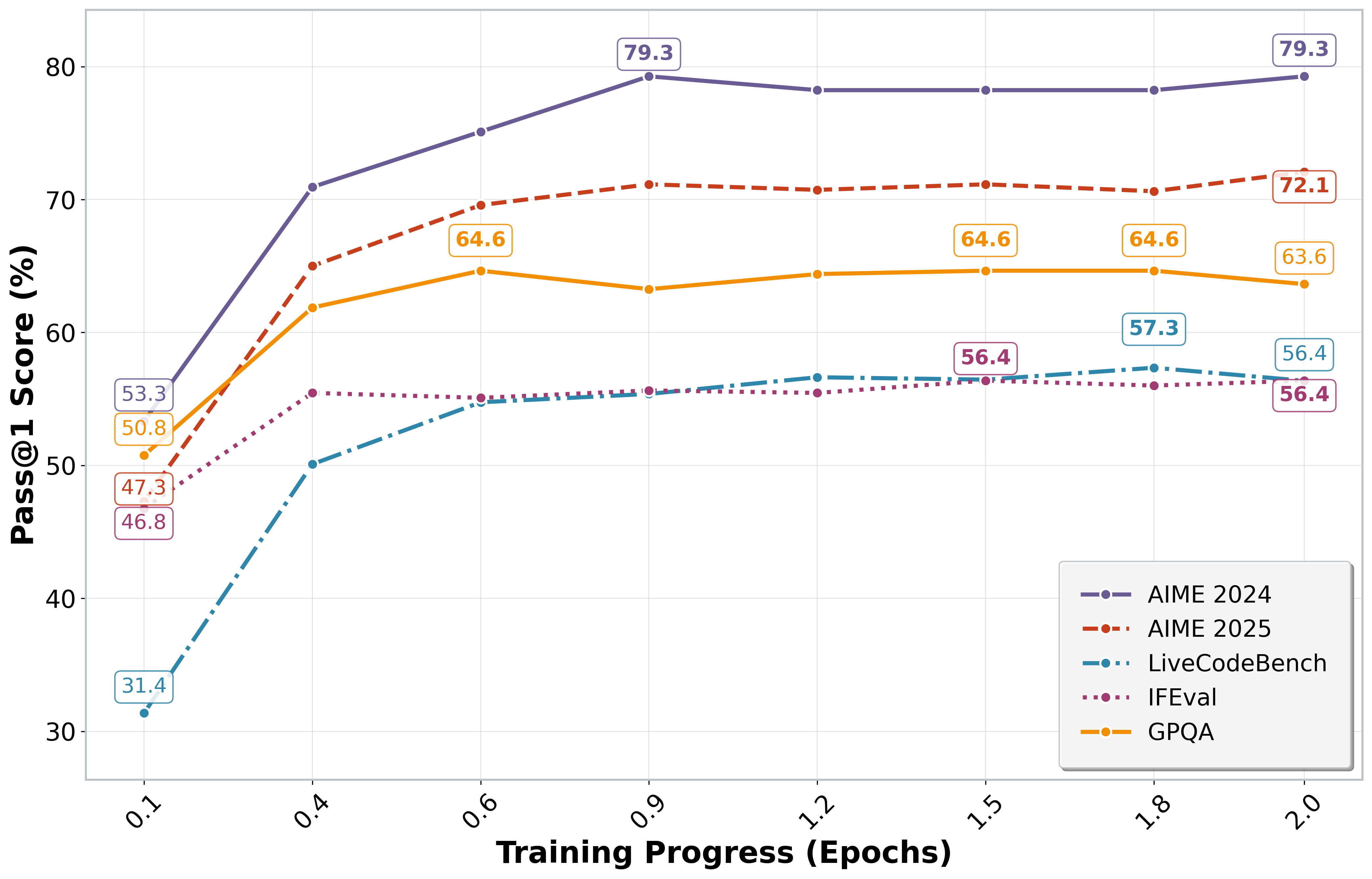
- On tough math contests (like AIME 2024/2025, HMMT 2025, and Omni-MATH-HARD), K2-Think’s overall math score (micro-average) is about 68%. It often matches or beats much larger open models (and comes close to some top commercial ones).
- It does especially well on the hardest set (Omni-MATH-HARD), showing it can handle deep reasoning, not just easy problems.
- Good results beyond math:
- Coding: Competitive on LiveCodeBench and SciCode.
- Science: Strong on GPQA-Diamond and decent on Humanity’s Last Exam.
- Which tricks helped the most:
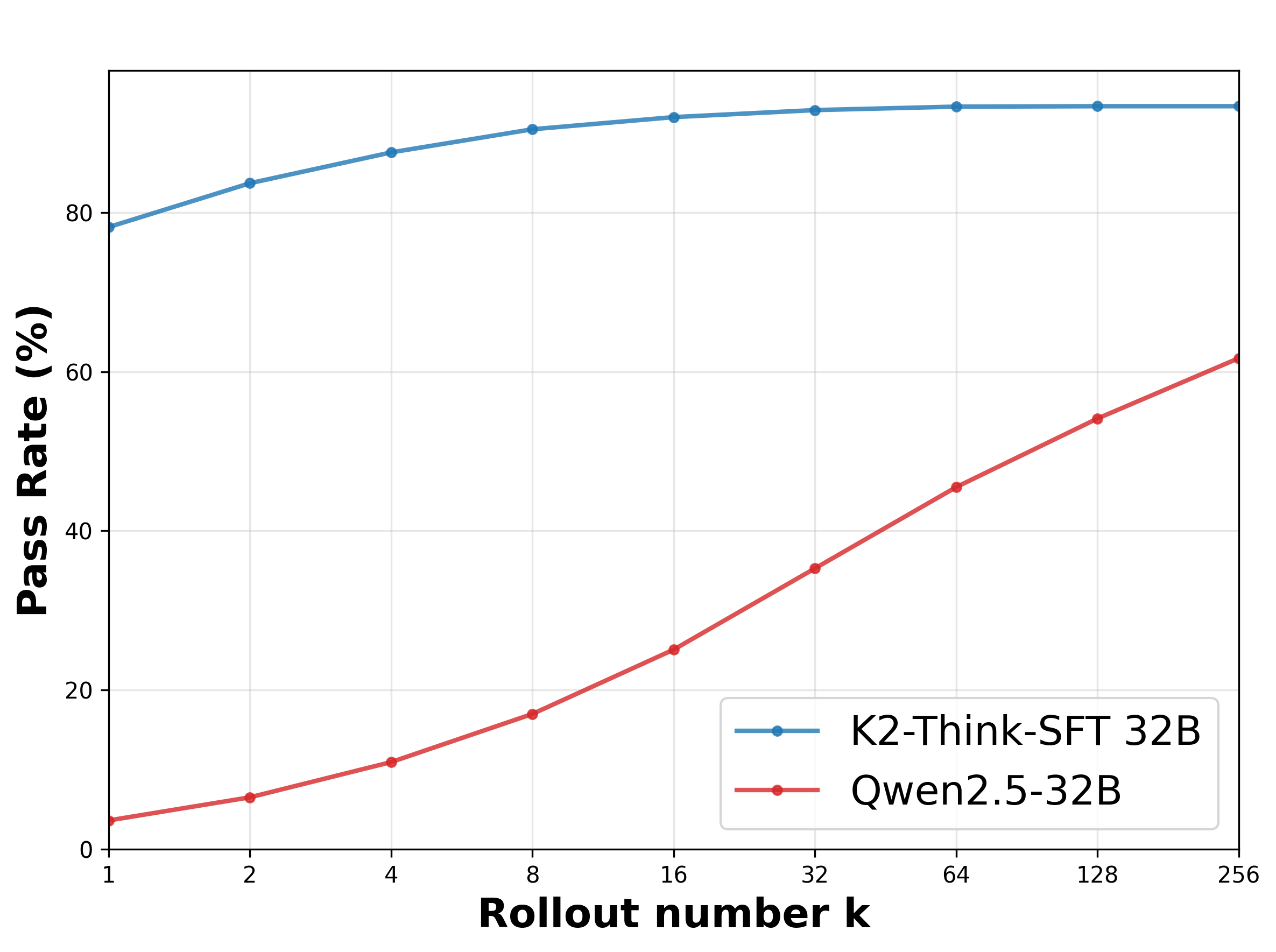
- Best-of-3 sampling gave the biggest improvement at test time.
- Adding planning (Plan-Before-You-Think) helped further—together they added roughly 4–6 percentage points on tough math benchmarks.
- Surprisingly, planning also made answers shorter on average (up to about 12% fewer tokens), because a good plan keeps the reasoning concise.
- Training insights:
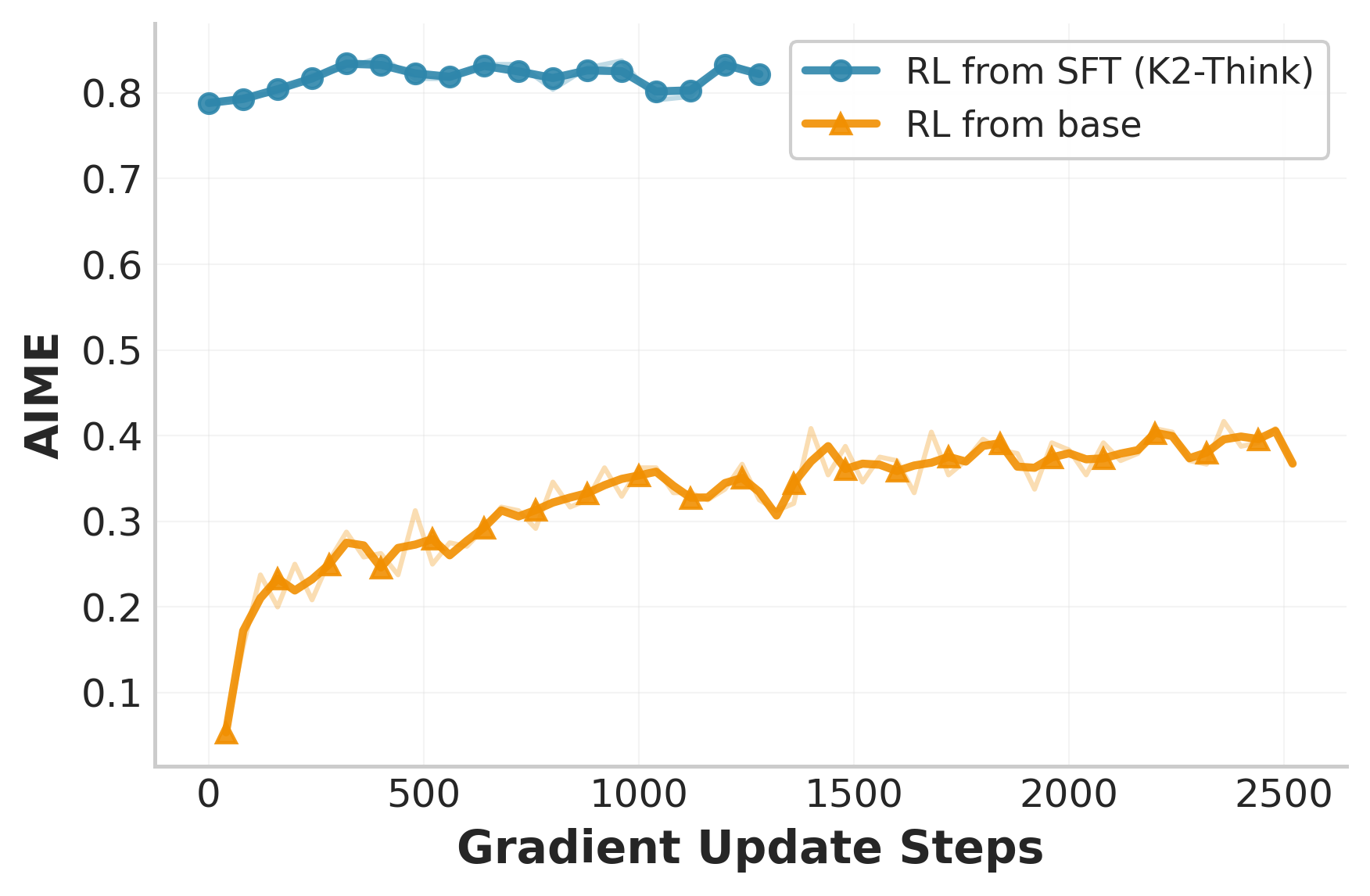
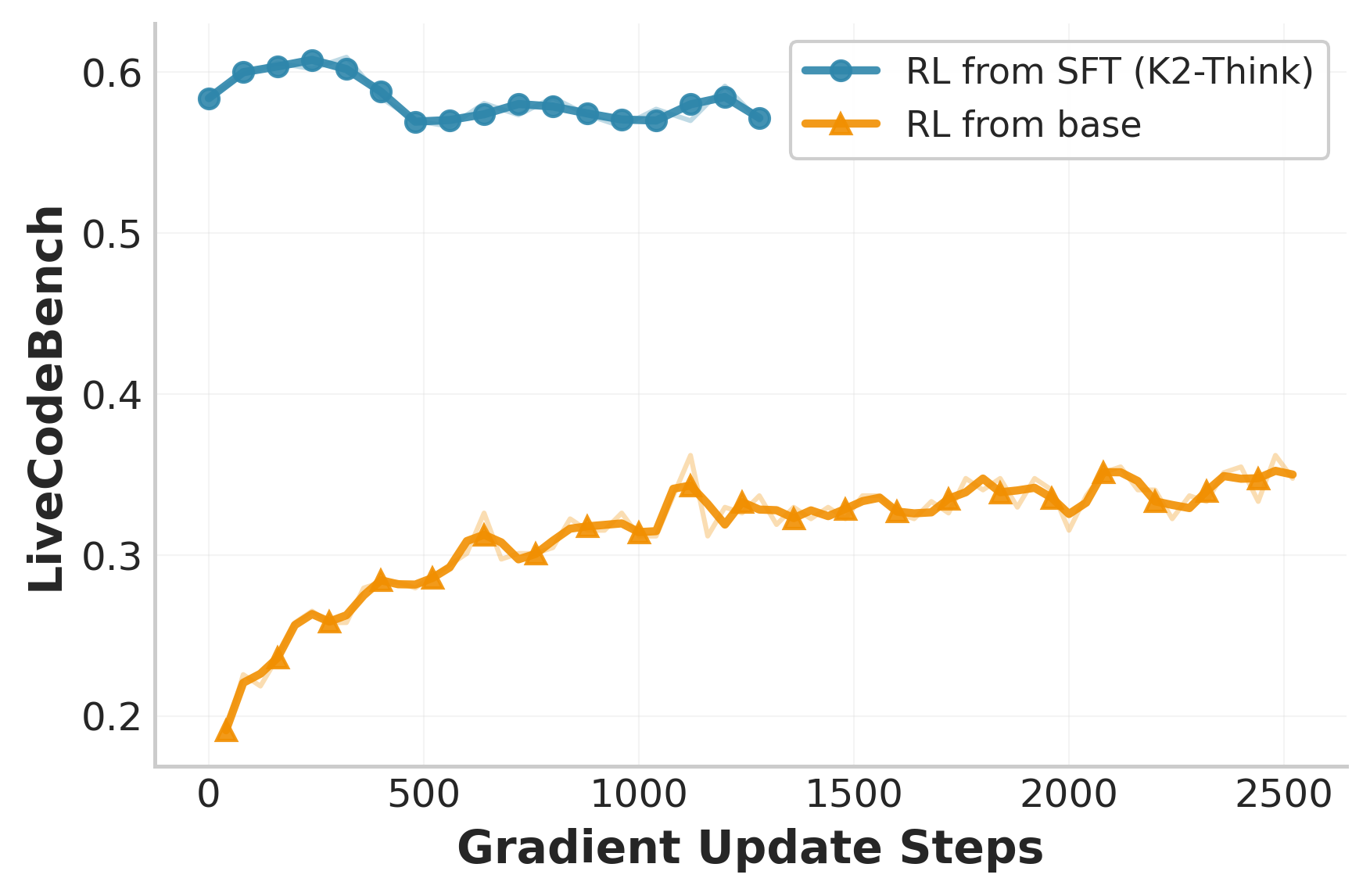
- Starting with SFT (teacher-style training) gives high starting performance, but then RL adds smaller gains (because the model is already good).
- Starting RL from the plain base model improves faster during RL, but the final level is lower than SFT+RL overall.
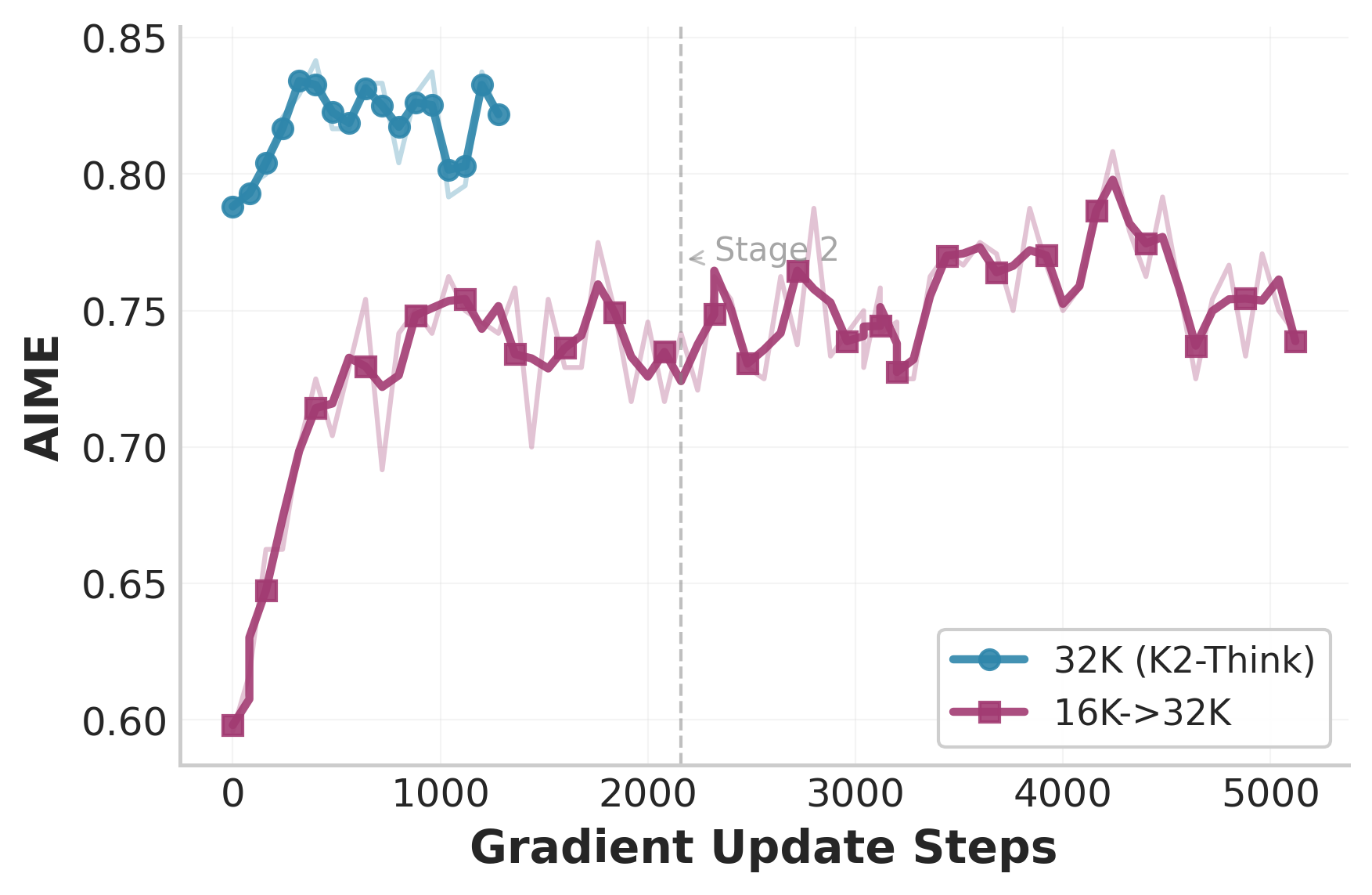
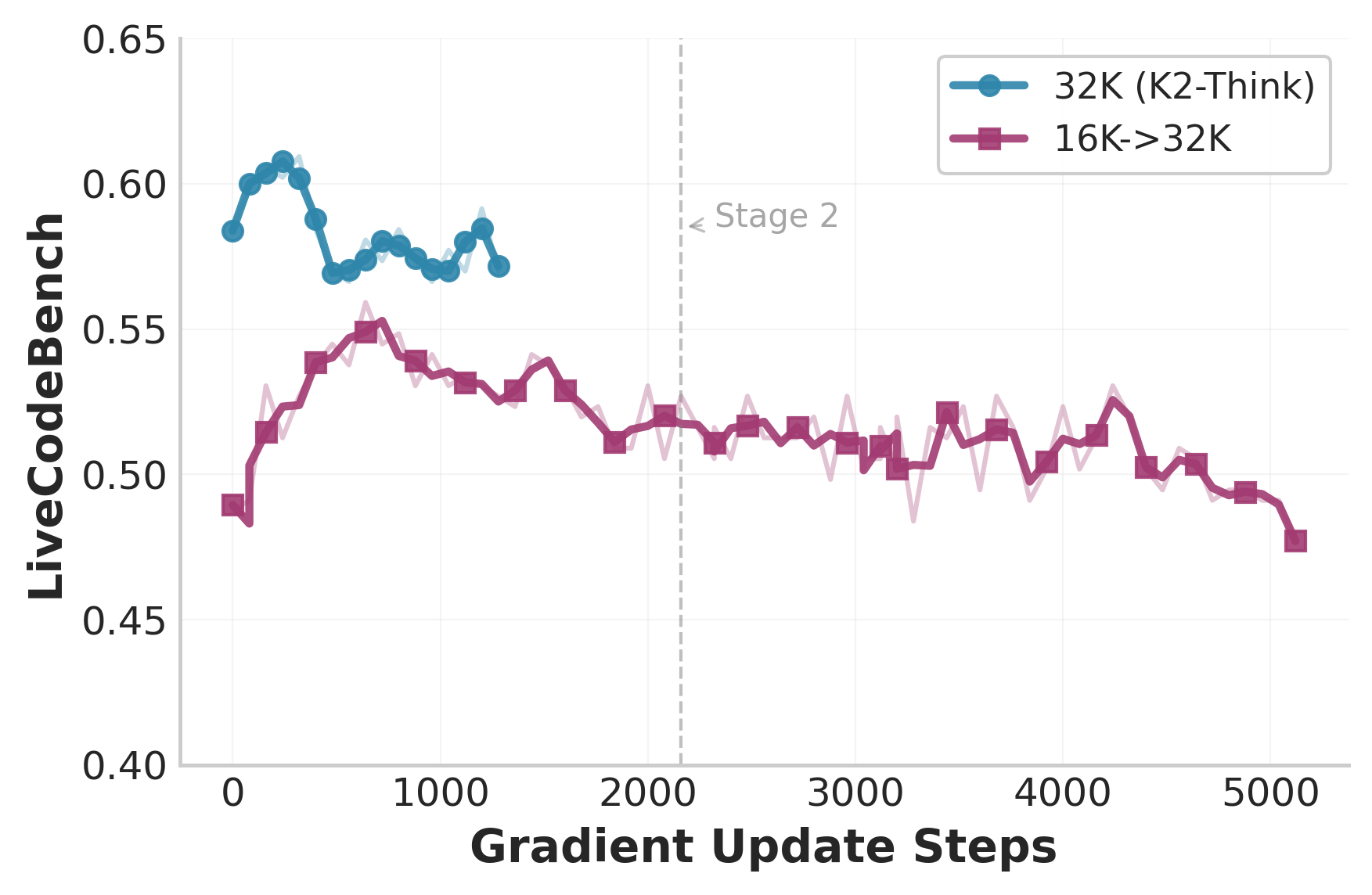
- Cutting the allowed answer length during RL (as a “curriculum”) hurt performance in their setup—going shorter first and then longer later did not recover the original quality.
- Speed and usability:
- With the Cerebras hardware, K2-Think can generate very long, step-by-step solutions in seconds rather than minutes. For example, a 32,000-token reasoning chain can finish in about 16 seconds instead of nearly 3 minutes on common GPUs.
- Safety checks:
- The team ran many safety tests (e.g., refusing harmful requests, staying safe over multi-turn chats, resisting prompt “jailbreaks,” and preventing info leaks).
- Results were strong in several areas (like refusing risky content and maintaining safe behavior across conversations), but there’s room to improve against certain jailbreak and cybersecurity-style attacks (like prompt extraction or assisting cyberattacks).
Why is this important?
- Smarter, not just bigger: K2-Think shows that smart training, planning, and testing strategies can make a medium-size model think like a much bigger one. This makes advanced reasoning more affordable and accessible.
- Practical speed: With new hardware and decoding tricks, long, step-by-step reasoning can be fast enough for real-time use—useful for tutoring, coding help, and science problems.
- Open and reproducible: It’s built on open datasets and released openly, so others can learn from it, improve it, and use it in research and products.
- Clear path forward: The component tests show what matters most (like BoN and planning), guiding future improvements.
Bottom line and future impact
K2-Think proves that you don’t need a gigantic model to get top-tier reasoning. With the right recipe—learning from full solutions, rewarding correct answers, planning ahead, trying multiple attempts, and running on fast hardware—a smaller model can compete at the frontier. This could make high-quality AI reasoning cheaper, faster, and easier to deploy in schools, research labs, and startups. As safety hardening continues, systems like K2-Think could become reliable assistants for advanced math, coding, and science—helping more people solve big problems, step by step.
Collections
Sign up for free to add this paper to one or more collections.

