- The paper presents Kimi K2's innovative Mixture-of-Experts architecture, demonstrating that increased sparsity reduces training and validation loss.
- It introduces the MuonClip optimizer with QK-Clip to stabilize training and prevent attention logit explosions without compromising performance.
- The integration of scalable training infrastructure, agentic data synthesis, and a unified RL framework achieves state-of-the-art results and robust safety.
Kimi K2: An Open-Source Trillion-Parameter MoE Model for Agentic Intelligence
Kimi K2 represents a significant advance in open-source LLMs, targeting agentic intelligence through a combination of architectural innovations, scalable training infrastructure, and a comprehensive post-training pipeline. This essay provides a technical analysis of the model’s design, training methodology, evaluation, and implications for future AI research.
Model Architecture and Pre-training Innovations
Kimi K2 is a 1.04T-parameter Mixture-of-Experts (MoE) transformer, with 32B activated parameters per forward pass. The architecture is based on multi-head latent attention (MLA), with 384 experts (8 active per token), 61 layers, and 64 attention heads. This design is informed by empirical scaling laws, which indicate that increased sparsity (i.e., more experts with a fixed number of active experts) yields improved performance at constant FLOPs, albeit with increased infrastructure complexity.
Sparsity Scaling Law: Controlled experiments demonstrate that, for a fixed number of activated parameters, increasing the total number of experts consistently reduces both training and validation loss. For example, at a validation loss of 1.5, sparsity 48 reduces FLOPs by up to 1.69× compared to sparsity 8, justifying the choice of 384 experts and 8-way activation.
Attention Head Trade-off: Doubling the number of attention heads (from 64 to 128) yields only marginal improvements (0.5–1.2% reduction in validation loss) but incurs significant inference overhead, especially for long-context applications. Kimi K2 opts for 64 heads to balance performance and efficiency.
Pre-training Data and Token Efficiency: The model is pre-trained on 15.5T curated tokens spanning web text, code, mathematics, and knowledge. To maximize token utility, Kimi K2 employs a synthetic rephrasing pipeline, including style- and perspective-diverse prompting, chunk-wise autoregressive rewriting, and fidelity verification. This approach increases effective data diversity without overfitting, as evidenced by improved SimpleQA accuracy with increased rephrasings.
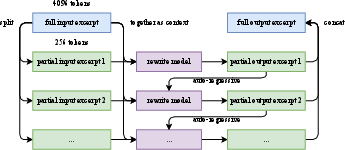
Figure 1: Auto-regressive chunk-wise rephrasing pipeline for long input excerpts, enabling scalable and diverse data augmentation.
MuonClip Optimizer and Training Stability
A central contribution is the MuonClip optimizer, which integrates the token-efficient Muon algorithm with a novel QK-Clip mechanism to address training instabilities, specifically the explosion of attention logits observed when scaling Muon to large models.
QK-Clip Mechanism: QK-Clip constrains the growth of attention logits by rescaling query and key projection weights post-update, based on the maximum observed logit per head. This per-head, per-layer intervention is minimally invasive and self-deactivates as training stabilizes.
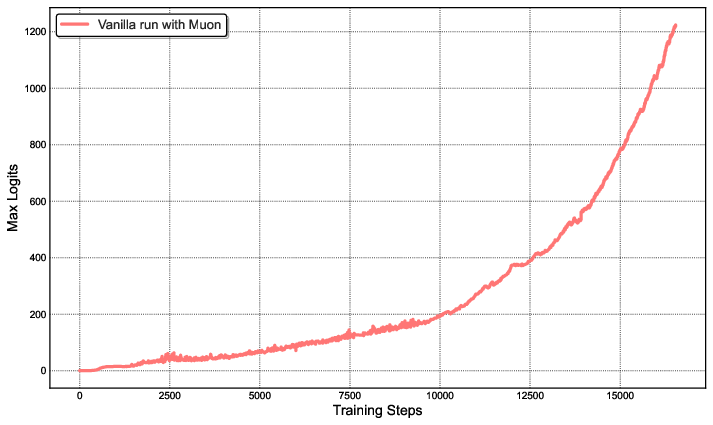
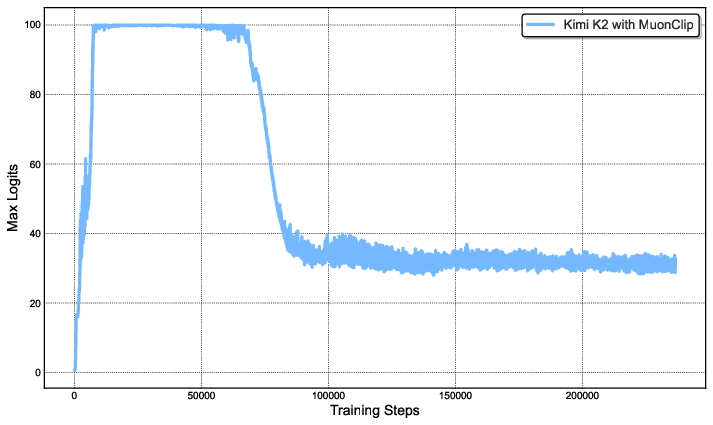
Figure 2: Left: Unconstrained Muon training leads to logit explosion (>1000). Right: QK-Clip caps logits at 100, with values decaying to a stable range after 30% of training steps.
Empirical results show that MuonClip eliminates loss spikes and divergence, enabling stable pre-training over 15.5T tokens. Small-scale ablations confirm that even aggressive QK-Clip thresholds do not impair convergence or downstream performance.
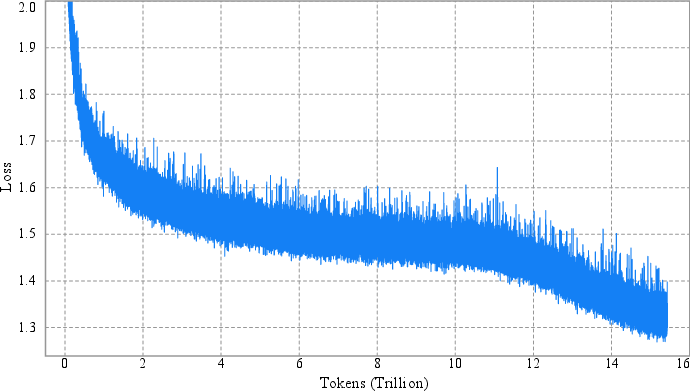
Figure 3: Per-step training loss curve of Kimi K2, showing no spikes throughout the entire training process.
Scalable Training Infrastructure
Kimi K2’s training leverages a heterogeneous cluster of NVIDIA H800 GPUs, employing a hybrid parallelism strategy: 16-way pipeline parallelism (PP), 16-way expert parallelism (EP), and ZeRO-1 data parallelism. This configuration supports flexible scaling across multiples of 32 nodes, with 6TB of GPU memory required for parameters and gradients.
Activation Memory Management: To fit activations within memory constraints, the system employs selective recomputation, FP8 storage for insensitive activations, and CPU offloading with a dedicated copy engine. These techniques ensure efficient utilization of GPU resources without compromising throughput.

Figure 4: Computation, communication, and offloading overlapped in different pipeline parallelism phases.
Post-Training: Agentic Data Synthesis and Reinforcement Learning
Large-Scale Agentic Data Synthesis
A key differentiator of Kimi K2 is its large-scale agentic data synthesis pipeline, which systematically generates tool-use demonstrations via both simulated and real-world environments. The pipeline comprises:
- Tool Spec Generation: Aggregates 3,000+ real MCP tools and 20,000+ synthetic tools, covering diverse domains.
- Agent and Task Generation: Synthesizes thousands of agents with varied toolsets and tasks, ensuring broad coverage.
- Trajectory Generation: Simulates multi-turn interactions with user personas and tool execution environments, introducing stochasticity and edge cases.
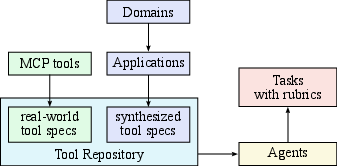
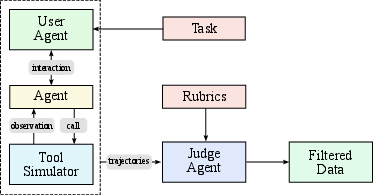
Figure 5: Synthesizing tool specs, agents, and tasks for large-scale agentic data generation.
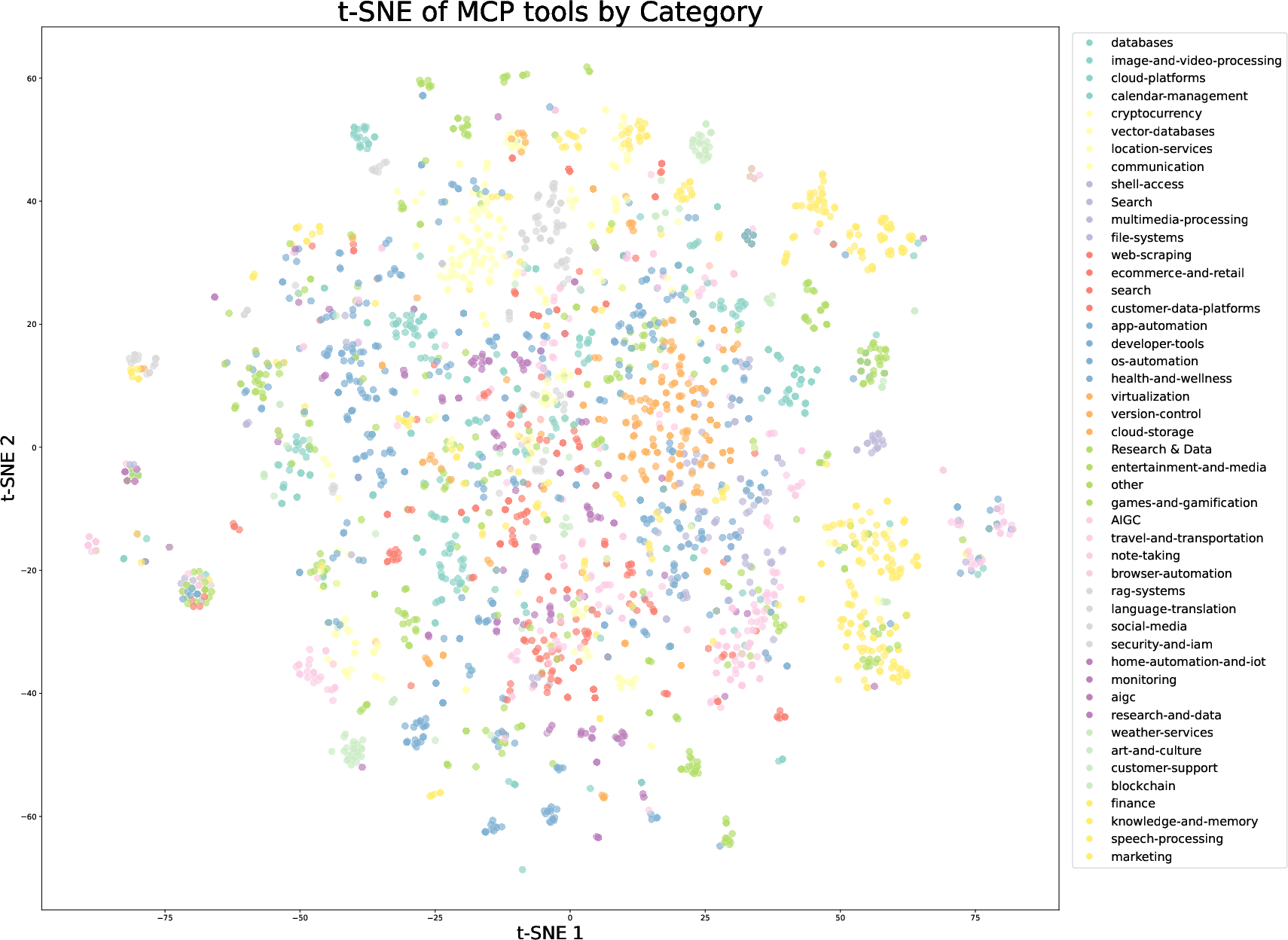
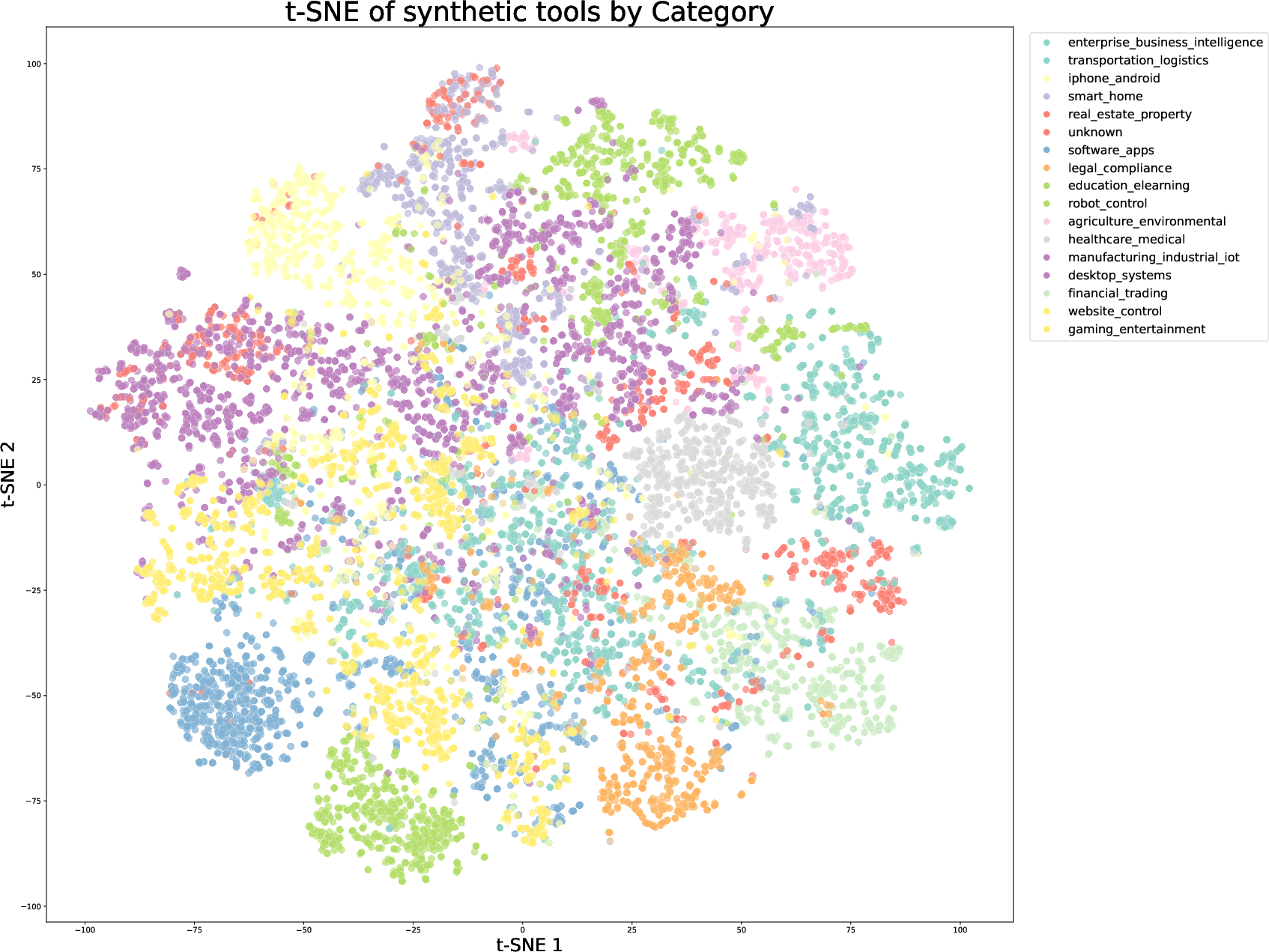
Figure 6: t-SNE visualization of real MCP tools, colored by their original source categories, demonstrating coverage and diversity.
Quality is ensured via LLM-based judges and rubric-based evaluation, with real execution sandboxes used for high-fidelity coding and software engineering tasks.
Reinforcement Learning with Verifiable and Self-Critique Rewards
Kimi K2’s post-training employs a unified RL framework combining verifiable rewards (RLVR) and self-critique rubric rewards. The RL infrastructure supports a wide range of tasks, including math, STEM, logical reasoning, instruction following, coding, and safety.
- Verifiable Rewards Gym: Tasks with objective metrics (e.g., math, code correctness) are evaluated via automated or LLM-based judges.
- Self-Critique Rubric Reward: For subjective tasks, the model performs pairwise comparisons of its own outputs, guided by a mixture of core, prescriptive, and human-annotated rubrics. The critic is continuously refined using verifiable signals, grounding subjective judgments in objective data.
The RL algorithm is based on policy optimization with per-sample token budget control, auxiliary PTX loss to prevent forgetting, and temperature decay for exploration-exploitation balance.
RL Infrastructure: A colocated architecture enables efficient engine switching and parameter updates, with a distributed checkpoint engine managing parameter state. The system achieves full parameter updates for the 1T model in under 30 seconds.
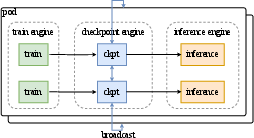
Figure 7: Parameter update utilizing a checkpoint engine, enabling efficient synchronization between training and inference engines.
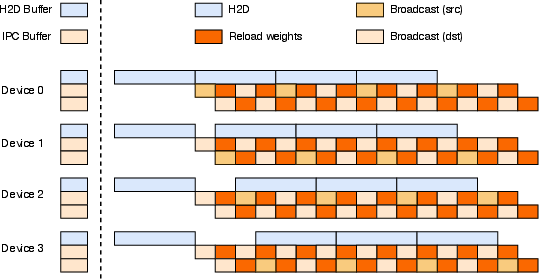
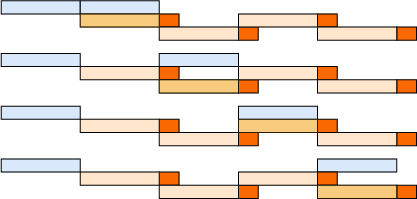
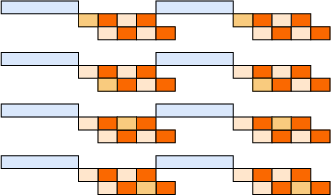
Figure 8: Theoretical perfect three-stage pipeline weight update for RL training.
Evaluation and Results
Main Results
Kimi K2-Instruct achieves state-of-the-art performance among open-source non-thinking models across a wide range of benchmarks:
- Agentic Tool Use: 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, 47.3 on SWE-Bench Multilingual.
- Coding and STEM: 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, 27.1 on OJBench.
- General Capabilities: 89.5 on MMLU, 92.7 on MMLU-Redux, 31.0 on SimpleQA.
- Long-Context and Factuality: 93.5 on DROP, 88.5 on FACTS Grounding, 98.9 on HHEM v2.1.
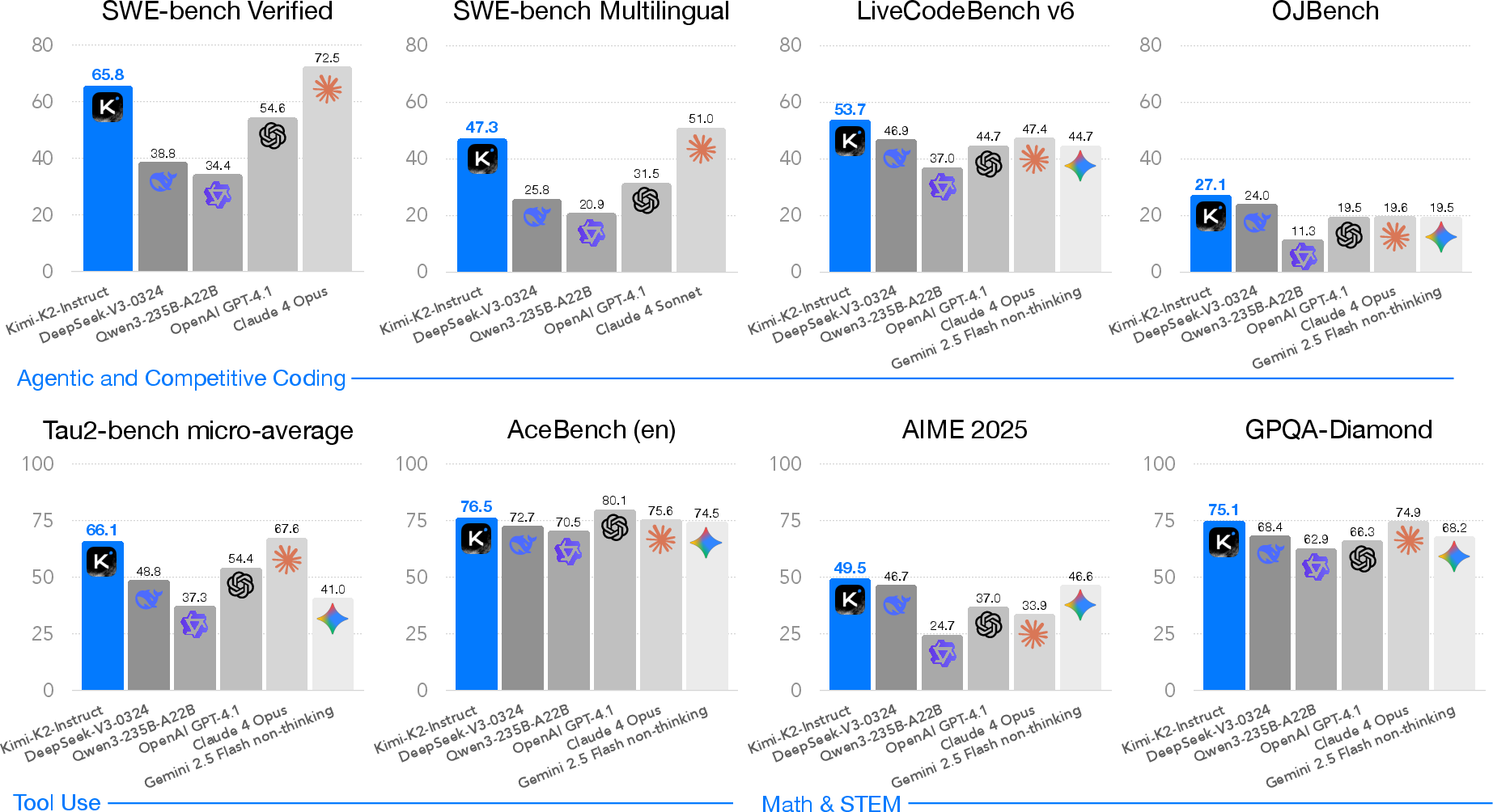
Figure 9: Kimi K2 main results, demonstrating state-of-the-art performance across agentic, coding, reasoning, and general benchmarks.
Safety Evaluation
Kimi K2 demonstrates robust safety across a range of adversarial scenarios, with high passing rates on harmful, criminal, misinformation, privacy, and security plugins under various attack strategies. However, performance on complex iterative jailbreaks and crescendo attacks indicates room for further improvement.
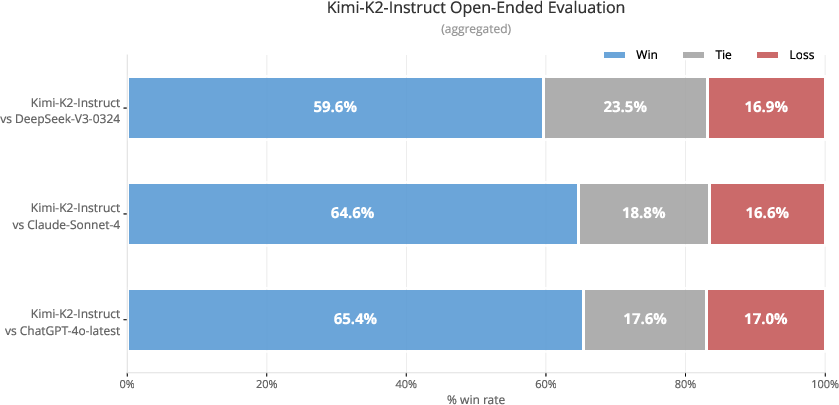
Figure 10: Chinese in-house benchmark evaluation, showing Kimi K2’s strong performance on open-ended Chinese tasks.
Training Stability
The MuonClip optimizer ensures stable training with no loss spikes, as evidenced by the smooth loss curve and controlled attention logits throughout pre-training.
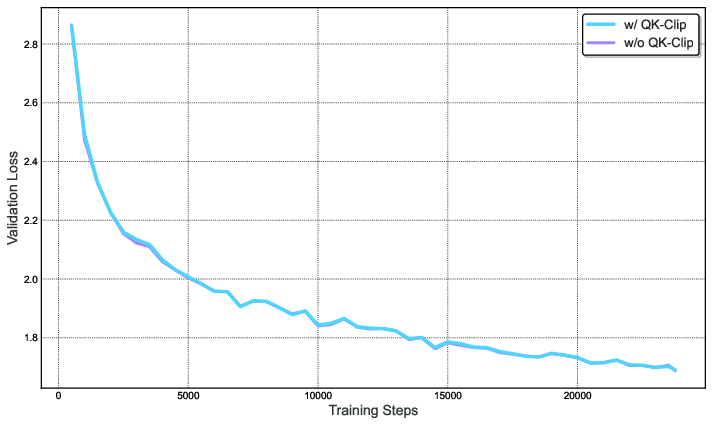
Figure 11: Applying QK-Clip to Muon in a small-scale setting with an aggressive threshold (τ=30) has negligible impact on loss, confirming the safety and effectiveness of the method.
Limitations
Despite its strengths, Kimi K2 exhibits limitations in hard reasoning tasks, handling of unclear tool definitions, and excessive token generation in some scenarios. Performance on complex software engineering tasks is improved under agentic coding frameworks rather than one-shot prompting. These areas are identified as targets for future improvement.
Implications and Future Directions
Kimi K2 establishes a new standard for open-source agentic LLMs, demonstrating that large-scale MoE architectures, when combined with token-efficient optimizers and scalable synthetic data pipelines, can rival or surpass proprietary models in agentic, coding, and reasoning tasks. The integration of verifiable and self-critique RL rewards provides a robust framework for aligning models with both objective and subjective human preferences.
Practical Implications:
- The open release of Kimi K2’s base and post-trained checkpoints enables broad adoption and further research in agentic intelligence, tool use, and software engineering.
- The MuonClip optimizer and QK-Clip mechanism offer practical solutions for stable, efficient training of ultra-large MoE models.
Theoretical Implications:
- The observed scaling laws for sparsity and attention heads inform future MoE model design.
- The hybrid RL framework suggests a path toward more generalizable and robust alignment strategies.
Future Work:
- Addressing limitations in reasoning and tool use, especially under ambiguous or adversarial conditions.
- Extending the agentic data synthesis pipeline to more diverse and realistic environments.
- Further optimizing safety and robustness against advanced attack strategies.
Conclusion
Kimi K2 demonstrates that open-source LLMs can achieve state-of-the-art agentic intelligence through architectural innovation, stable and efficient training, and comprehensive post-training pipelines. Its release provides a strong foundation for future research and deployment of agentic AI systems in real-world applications.