- The paper presents MiniMax-M1, a hybrid Mixture-of-Experts model with Lightning Attention that scales test-time compute for long-context reasoning.
- The methodology combines continual pretraining, supervised fine-tuning, and the novel CISPO algorithm to optimize reinforcement learning and mitigate token clipping issues.
- Empirical evaluations show state-of-the-art performance in coding, mathematical reasoning, and agentic tool use, making it suitable for complex real-world applications.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
The paper "MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention" (2506.13585) introduces MiniMax-M1, a large reasoning model (LRM) featuring a hybrid Mixture-of-Experts (MoE) architecture and Lightning Attention. This model supports a context length of 1 million tokens and demonstrates efficient scaling of test-time compute, achieving state-of-the-art performance in complex tasks such as software engineering and tool utilization. The release of MiniMax-M1 provides a strong foundation for developing next-generation LLM agents.
Architecture and Efficiency
MiniMax-M1 builds upon the MiniMax-Text-01 model, incorporating a hybrid MoE architecture with 456 billion parameters, of which 45.9 billion are activated per token. A key innovation is the integration of Lightning Attention, enabling efficient scaling to hundreds of thousands of tokens.
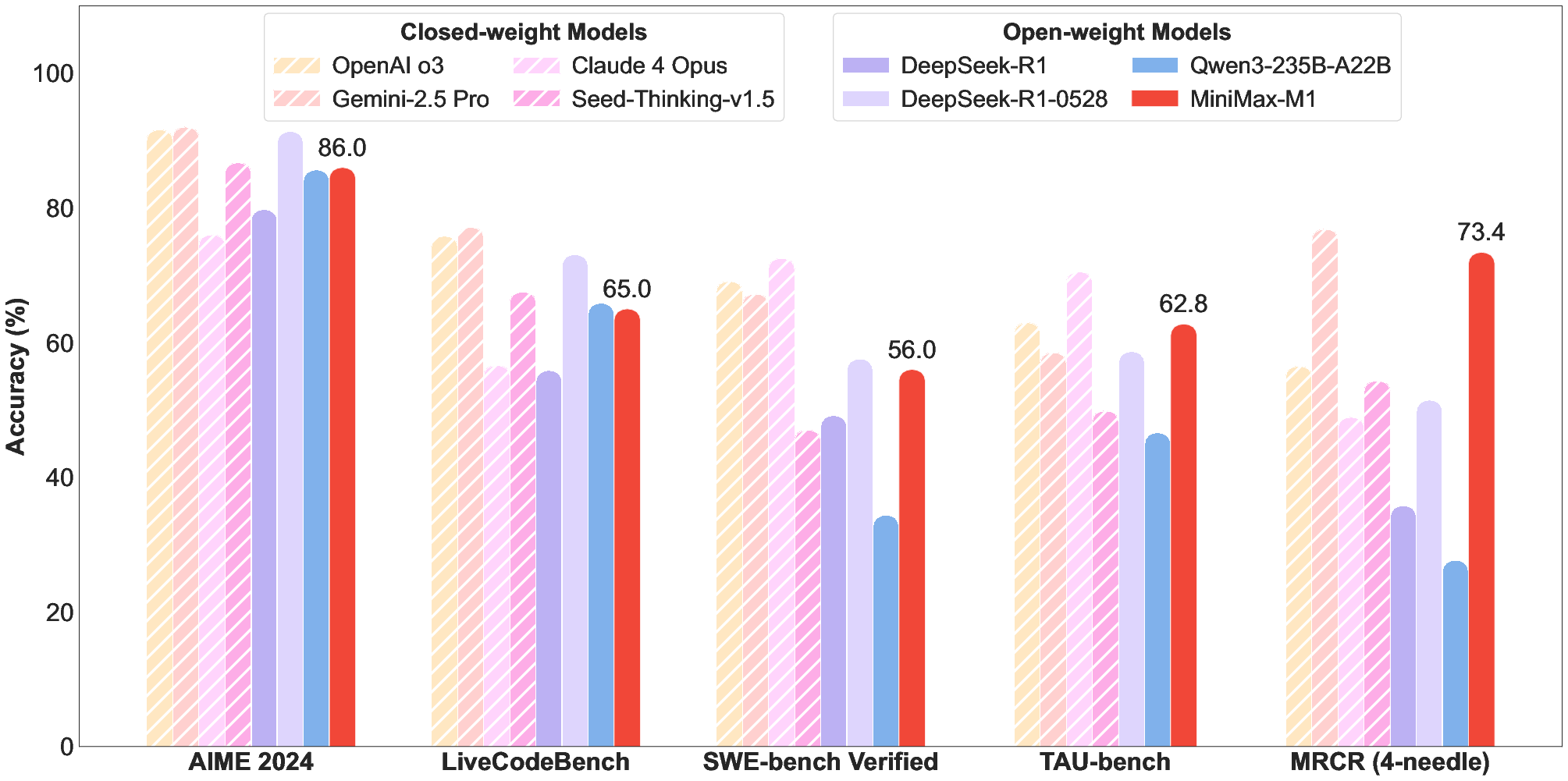
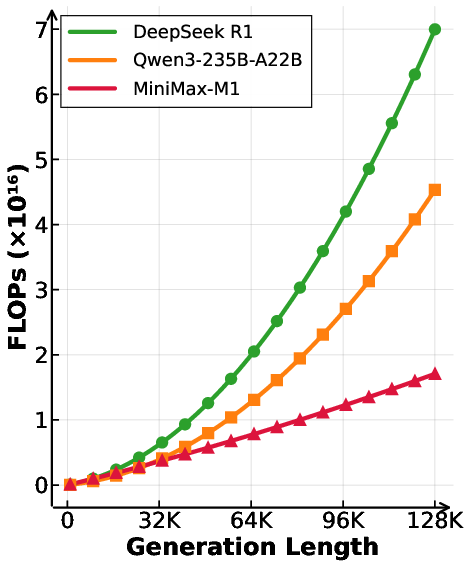
Figure 1: Left: Benchmark performance comparison of leading commercial and open-weight models across competition-level mathematics, coding, software engineering, agentic tool use, and long-context understanding tasks. We use the MiniMax-M1-80k model here for MiniMax-M1. Right: Theoretical inference FLOPs scaling with generation length (# tokens).
The architecture strategically alternates between transformer blocks with softmax attention and transnormer blocks with lightning attention. Specifically, every seven transnormer blocks are followed by a transformer block with softmax attention. This design enables M1 to consume significantly fewer FLOPs compared to models like DeepSeek R1, especially at longer generation lengths. The 1 million token context length represents an 8x increase over DeepSeek R1, facilitating complex, real-world tasks requiring extensive input and reasoning.
Training Methodology
The development of MiniMax-M1 involved three key stages: continual pretraining, supervised fine-tuning (SFT), and reinforcement learning (RL).
Continual Pretraining
MiniMax-Text-01 underwent continual pretraining on 7.5T tokens from a reasoning-intensive corpus. The data curation process emphasized high recall of mathematical and code-related data, with a focus on natural Question-Answer (QA) pairs and semantic deduplication. The training recipe involved adjusting the MoE auxiliary loss and adapting a parallel training strategy to support larger batch sizes. A smooth extension of context length across four stages, starting from 32K and extending to 1M tokens, mitigated gradient explosion issues.
Supervised Fine-Tuning
SFT was performed to instill reflection-based Chain-of-Thought (CoT) reasoning using high-quality examples. The curated data samples covered diverse domains, with math and coding samples accounting for approximately 60% of the data.
Reinforcement Learning
RL was employed to further enhance the reasoning capabilities of MiniMax-M1. The authors introduce CISPO (Clipped IS-weight Policy Optimization), a novel RL algorithm that clips importance sampling weights rather than token updates, enhancing RL efficiency.
CISPO Algorithm
The CISPO algorithm addresses issues associated with token clipping in traditional PPO/GRPO-based RL. The clipping operation in PPO/GRPO can inadvertently remove rare but crucial tokens associated with reflective behaviors, hindering the emergence of long CoT reasoning. CISPO mitigates this by clipping the importance sampling weight, r^i,t(θ), instead of clipping token updates, preserving gradient contributions from all tokens. The CISPO objective function is defined as:
$\mathcal{J}_{\text{CISPO}(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}(\cdot|q)} \
\left[
\frac{1}{\sum_{i=1}^G |o_i|} \sum_{i=1}^G \sum_{t=1}^{|o_i|}
sg(\hat{r}_{i,t}(\theta))\hat{A}_{i,t}\log \pi_\theta(o_{i,t} \mid q, o_{i,<t})
\right],$
where sg(⋅) is the stop-gradient operation, and A^i,t is the group relative advantage.
Empirical validation demonstrates that CISPO outperforms DAPO and GRPO in a zero-RL training setting, achieving superior performance on the AIME 2024 benchmark with fewer training steps.
RL Challenges and Solutions
The authors encountered unique challenges when scaling RL with the hybrid architecture of MiniMax-M1. One significant issue was a computational precision mismatch between training-mode and inference-mode kernels, leading to discrepancies in token probabilities. This was resolved by increasing the precision of the LM output head to FP32, improving the correlation between training and inference probabilities. Additional challenges included optimizer hyperparameter sensitivity and early truncation of pathological responses via repetition detection.
Diverse Data for Reinforcement Learning
The RL training data encompassed a diverse set of problems and environments, including both verifiable and non-verifiable tasks.
Reasoning-Intensive Tasks with Rule-Based Verification
Mathematical reasoning data was meticulously curated from public sources and mathematics competitions, with a focus on high-quality, competition-level problems. Logical reasoning data was synthesized using the SynLogic framework, spanning 41 distinct tasks. Competitive programming problems were collected from online judge platforms, with test cases generated using an LLM-based workflow. Software engineering environments were constructed from real-world GitHub repositories, with a containerized sandbox environment providing execution-based rewards.
General Domain Tasks with Model-Based Feedbacks
General domain tasks, such as question answering and creative writing, were incorporated using generative reward models (GenRMs) to provide feedback. To address length bias in GenRMs, the authors employed continuous online monitoring and recalibration during RL training.
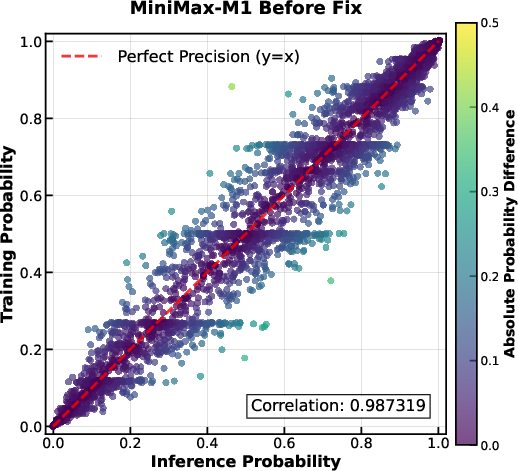
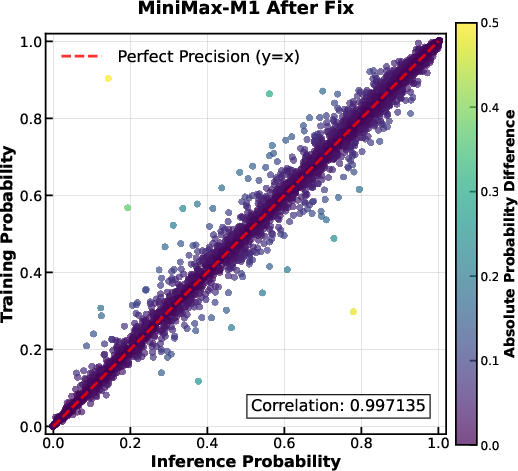
Figure 2: Probability of tokens in training-mode code vs. probability of tokens in inference-mode code. Each point in the figures represents an individual token. The Pearson correlation coefficient is indicated in the figures. Theoretically, the two probabilities should be identical, and all the tokens should be exactly on the diagonal line. {\bf Left: Correlation of the M1 model before our fix; {\bf Right:} Correlation of the M1 model after applying our fix of using FP32 precision for the LM output head.
The RL training process involved a carefully managed curriculum and dynamic weighting strategy, starting with reasoning-intensive tasks and gradually mixing in general domain tasks. This approach ensured refinement of verifiable skills while fostering broader generalization.
Scaling to Longer Thinking
The initial RL training was performed with an output length limit of 40K tokens, with subsequent scaling to 80K tokens using a staged window expansion strategy.
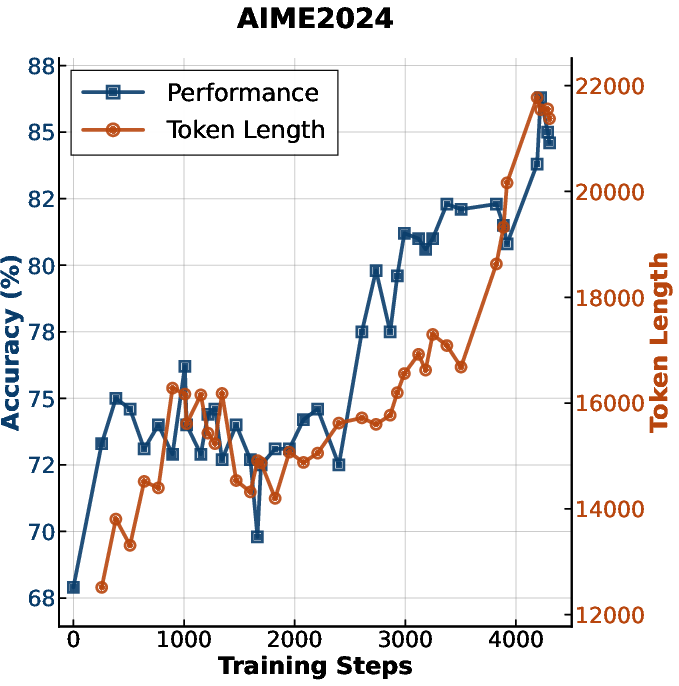
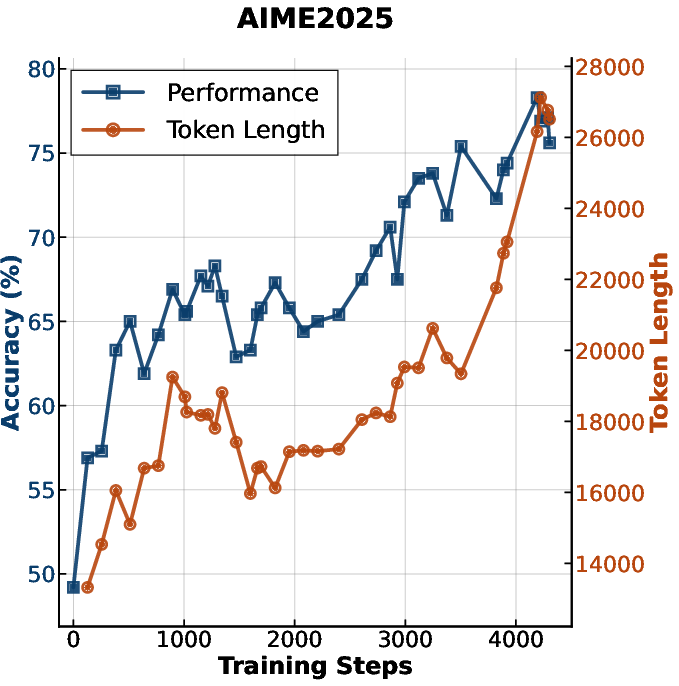
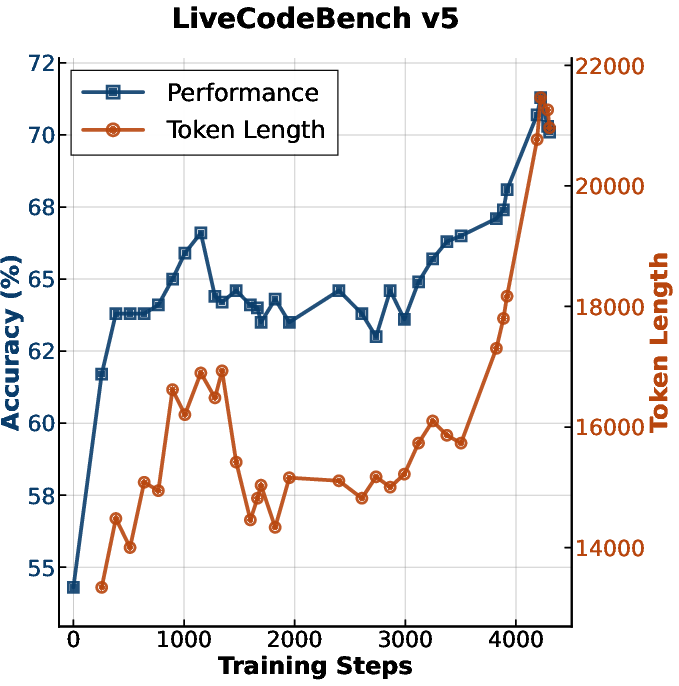
Figure 3: Accuracy and generation length versus RL training steps for MiniMax-M1.
The data distribution was adjusted to favor more challenging examples, with downsampling of synthetic reasoning data to prevent instability. The authors addressed training instability during scaling by detecting repetitive patterns, adopting combined sample-level loss and token-level normalization, and decreasing gradient clipping thresholds.
Evaluation and Results
The evaluation of MiniMax-M1 covered mathematics, general coding, software engineering, knowledge, long context, agentic tool use, factuality, and general assistant ability.
(Figure 4)
Figure 4: Comparison of GRPO, DAPO, and our proposed CISPO on AIME 2024, based on Qwen2.5-32B-base. CISPO outperforms both GRPO and DAPO in terms of performance at the same number of training steps, and achieves comparable performance to DAPO using 50% of the training steps.
The results demonstrate that MiniMax-M1 achieves state-of-the-art performance among open-weight models, particularly in complex scenarios such as software engineering, long context understanding, and agentic tool use. MiniMax-M1-80k consistently outperforms MiniMax-M1-40k, confirming the benefits of scaling test-time compute.
Conclusion
MiniMax-M1 represents a significant advancement in LLMs, offering a combination of efficient architecture, innovative training methodologies, and strong empirical performance. The release of MiniMax-M1 facilitates collaboration and further advancements in the field. Future work may explore the potential of efficient architectures in addressing real-world challenges, such as automating company workflows and conducting scientific research.

