- The paper introduces M1, a hybrid model that blends Mamba SSM layers with transformer distillation to achieve subquadratic inference and robust mathematical reasoning.
- It employs a three-stage training pipeline—cross-architecture distillation, supervised fine-tuning, and reinforcement learning—to boost accuracy and throughput, achieving up to 3x faster decoding.
- The study demonstrates that transferring reasoning skills from transformer teachers to RNN/SSM hybrids enables scalable test-time compute, benefiting applications like chain-of-thought and majority voting.
M1: A Hybrid Mamba Reasoning Model for Scalable Test-Time Compute
Motivation and Context
Transformer-based LLMs have driven advances in mathematical and programming reasoning, but their quadratic time and linear memory requirements severely inhibit scalability for long-context or high-batch inference—a regime increasingly central for state-of-the-art test-time techniques such as chain-of-thought, self-consistency, and majority voting. Hybrid linear RNN and SSM-based models (notably Mamba) offer subquadratic, memory-efficient generation, but their efficacy on high-precision reasoning tasks, especially when transferring capabilities from transformer “teacher” models, remains insufficiently explored.
Model Architecture and Training Pipeline
The paper presents M1, a hybrid reasoning model based on the Mamba architecture, targeting efficient, scalable inference for mathematical reasoning. M1 employs a three-stage training procedure: (1) cross-architecture distillation from a Llama3.2-3B-Instruct transformer into a Mamba hybrid (via “MambaInLlama” initialization and reverse KL divergence optimization), (2) supervised finetuning (SFT) on expansive mathematical datasets (OpenMathInstruct-2 followed by large-scale reasoning data from R1 model outputs), and (3) reinforcement learning optimization (GRPO, omitting KL penalty and including entropy bonus for policy diversity) tailored for large-scale long-sequence generation with efficient CUDA graphs.
The architectural configuration for the 3B parameter model comprises interleaved attention and Mamba SSM layers (with SSM state size 16; e.g., 6 attention layers among 28 total), maintaining substantial expressiveness typical of modern LLMs while reducing key-value cache memory overheads that bottleneck transformers during autoregressive decoding.
Empirical Evaluation
Extensive experiments were conducted on major math benchmarks (MATH500, AIME24, AIME25, AMC23, OlympiadBench), benchmarking both accuracy and speed relative to highly optimized transformers (DeepSeek-R1-Distill-Qwen-1.5B and Llama-3.2-3B). M1 achieves competitive accuracy: 82 on MATH500, 23 on AIME25, 28 on AIME24, and 47 on OlympiadBench. On most leaderboards, M1 matches or slightly outperforms DeepSeek-R1-Distill-Qwen-1.5B, with the exception of AIME24.
Inference Throughput and Latency
On practical throughput metrics, M1 exhibits over 3x speedup in inference latency compared to transformers of equivalent size (batch size 512, decoding length 4096), even when both utilize the state-of-the-art vLLM inference backend.
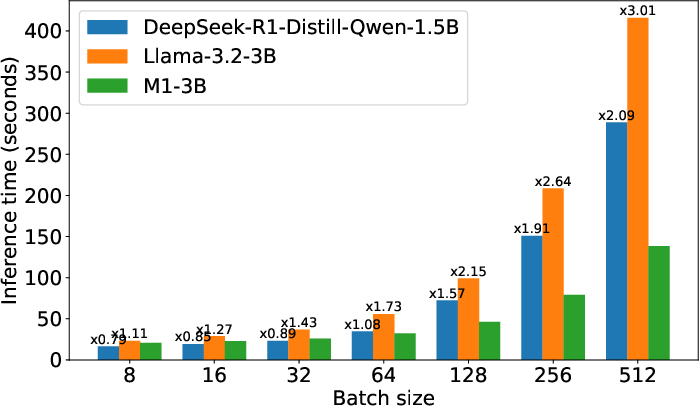
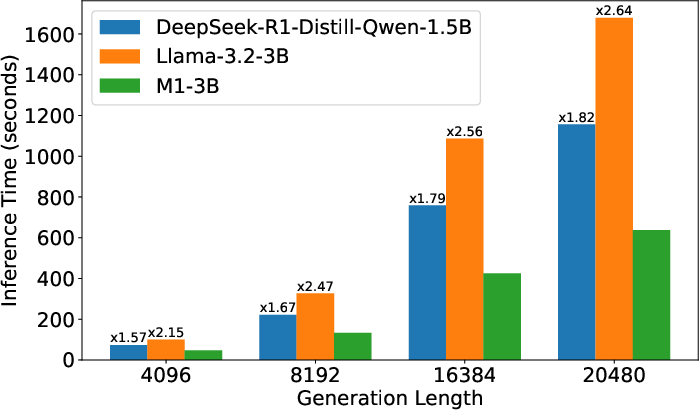
Figure 1: Left—Inference latency for prompt length 256, decoding length 4096; Right—Inference latency with batch size 128.
As batch size or sequence length increases, M1’s throughput advantage widens, with more than 2.6x faster generation for sequence lengths up to 32k. The model’s memory efficiency stems from minimized KV caching and the linear-time characteristics of the Mamba SSM layers, resulting in a decoding speedup that scales with increased batch size and context (reflecting the typical high-throughput needs of chain-of-thought and verification pipelines).
Test-Time Compute Scaling and Self-Consistency
Utilizing M1’s speed advantages, the study analyzes the benefits of scaling test-time compute under fixed resource constraints—a practical concern for production-grade deployment and research experimentation with majority voting, self-consistency sampling, and chain-of-thought scaling.
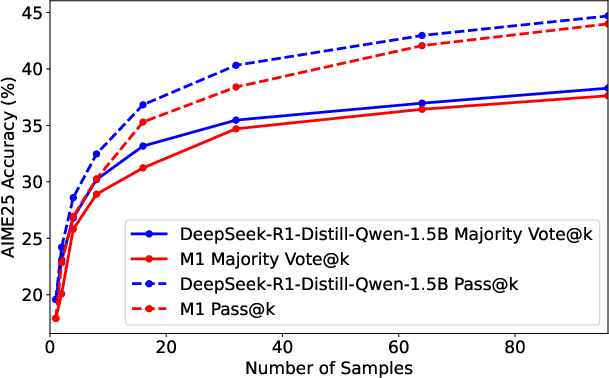
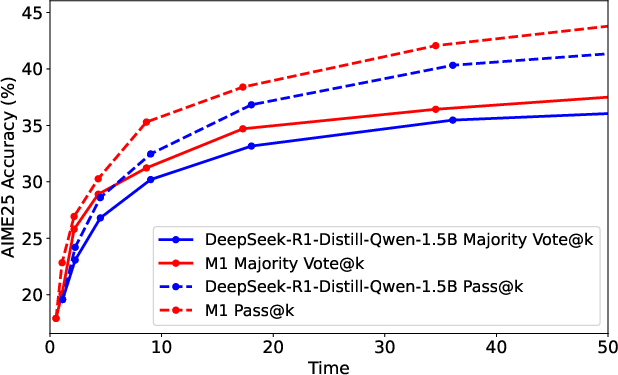
Figure 2: Left—Number of samples vs. AIME25 accuracy (pass@1 and majority voting); Right—Generation time (seconds) vs. AIME25 accuracy for M1 and DeepSeek-R1-Distill-Qwen-1.5B.
Given a fixed wall-clock time, M1 generates more samples or longer sequences than transformers, converting throughput gains into higher accuracy when utilizing self-consistency. For example, M1 achieves superior accuracy for the same generation time budget, outperforming a same-size transformer under majority voting with up to twice as many high-quality samples.
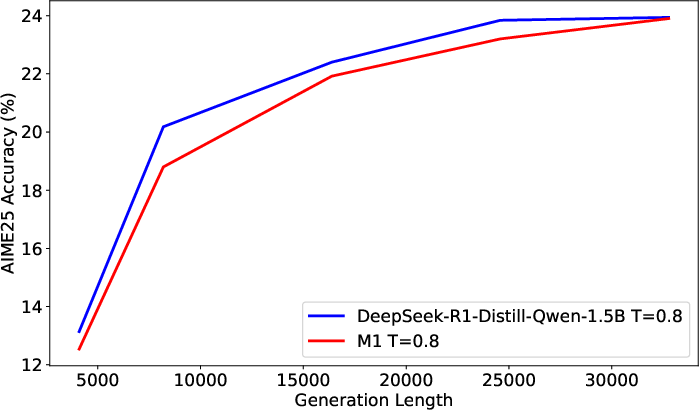
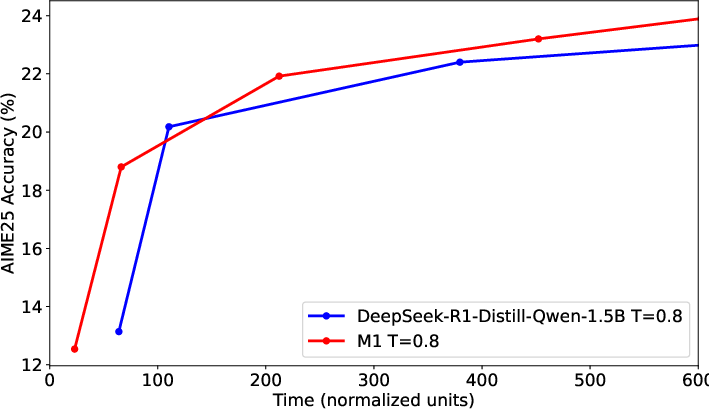
Figure 3: Left—Generation length vs. AIME25 accuracy; Right—Generation time (seconds) vs. AIME25 accuracy.
Both models improve with longer generations due to test-time compute scaling, but M1 consistently attains higher accuracy than transformers for the same time expenditure, particularly benefiting applications reliant on multiple rollouts or extended reasoning traces.
RL Training with Long Sequences
The model’s efficiency further enables RL training with much longer maximum generation lengths. Expanding the sequence length for GRPO training directly boosts pass@1 accuracy on AIME25. For instance, allowing 24k tokens raises accuracy to 23%, compared to sub-10% with 4k maximum length.
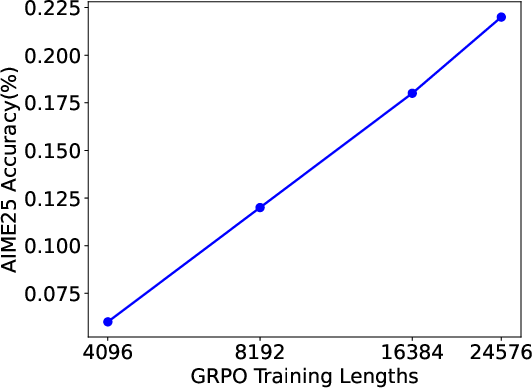
Figure 4: Pass@1 vs. maximum sequence length during GRPO training, illustrating improved performance with longer context.
The analysis highlights that each training stage (distillation, SFT on general math, SFT on reasoning traces, RL) provides incremental accuracy gains, with the transition to reasoning SFT and RL delivering the largest jumps.
Training Pipeline Insights
Attempts to directly distill reasoning skills from smaller transformer models with only reasoning-targeted SFT (10B tokens), skipping initial MATH SFT, yielded weak performance. The results substantiate the necessity of initial general mathematical capability, with reasoning-specific data providing a significant catalyst only for already well-aligned models.
Theoretical and Practical Implications
M1 demonstrates that linear RNN/SSM-based architectures, when properly initialized and finetuned via cross-architecture distillation, SFT, and RL, are viable alternatives to transformers for long-sequence, high-throughput reasoning. This suggests that core capabilities previously attributed to quadratic attention and full K/V caching can be transferred and fully realized in subquadratic architectures, at least within the regimes evaluated.
Practically, M1’s accelerated inference unlocks wider, more affordable test-time compute strategies, such as self-consistency and verification, in settings with limited hardware or energy constraints. For RL, the reduced generation bottleneck enables larger batch sizes and longer rollouts, which are empirically validated to increase downstream accuracy.
Theoretically, the results support an architectural decoupling of high-throughput reasoning ability from transformer-specific mechanisms, leaning into the emerging trend of hybrid or pure SSM-based models for efficient, scalable reasoning in LLMs.
Conclusion
M1 establishes linear RNN/SSM hybrids, particularly Mamba-based variants, as competitive platforms for reasoning-centric LLMs, achieving state-of-the-art accuracy in mathematical reasoning with substantially improved inference speed. The hybrid model’s speedup can be seamlessly capitalized for test-time compute scaling, providing accuracy gains under constant time and resource budgets, and accelerating RL training. The pipeline also demonstrates the importance of full-stage distillation and SFT strategies for robust cross-architecture transfer of reasoning capability. M1 paves the way for further research into even more efficient architectures, potentially integrating deeper hardware optimizations or more sophisticated hybridization regimes. Future directions may include further scaling, architectural exploration (such as alternative SSM layouts or finer-grained hybridism), and extending these findings to more diverse reasoning domains outside competitive mathematics.