- The paper introduces a novel recurrent-depth architecture that leverages latent space reasoning to dynamically adjust test-time compute without specialized training data.
- The model achieves significant performance improvements on reasoning benchmarks by iteratively refining a latent state through a recurrent block integrated with a prelude and a coda.
- The approach scales to 3.5B parameters, employs adaptive compute techniques, and demonstrates zero-shot capabilities with effective weight averaging and continuous chain-of-thought.
Scaling Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
This paper introduces a novel LLM architecture that leverages latent space reasoning to scale test-time computation. By incorporating a recurrent block, the model can unroll to arbitrary depths during inference, enhancing performance on reasoning benchmarks without requiring specialized training data or long context windows. The model's ability to reason in latent space allows it to capture complex computations that may not be easily verbalized.
Recurrent Architecture and Training
The architecture comprises three main components: a prelude (P), a recurrent block (R), and a coda (C) (Figure 1). The prelude embeds input tokens into a latent space, while the core recurrent block iteratively refines the latent state. The coda then decodes the final latent state to produce output probabilities. Given an input sequence x∈Vn and a number of recurrent iterations r, the forward pass is defined as:
e=P(x) s0∼N(0,σ2In⋅h) si=R(e,si−1)fori∈{1,…,r} p=C(sr)
where e is the embedded input, si is the latent state at iteration i, and p is the output probability distribution.
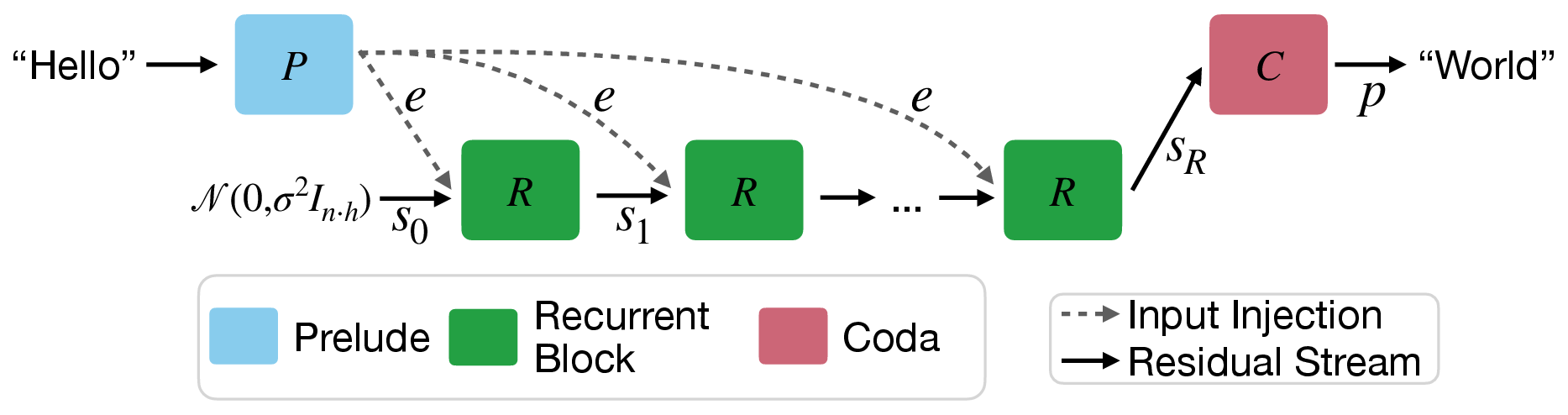
Figure 1: A visualization of the Architecture, as described in \Cref{sec:architecture}.
The recurrent block R incorporates an adapter matrix A:R2h→Rh that maps the concatenation of the embedded input e and the previous latent state si−1 into the hidden dimension h. The architecture uses a "sandwich" normalization scheme with RMSNorm to stabilize the recurrence, which is crucial for training at scale. During training, the number of recurrent iterations r is randomly sampled from a log-normal Poisson distribution (Figure 2) to ensure the model can generalize to different compute budgets at test time. Truncated backpropagation is used to limit the computational cost during training, where gradients are only propagated through the last k iterations of the recurrent unit.
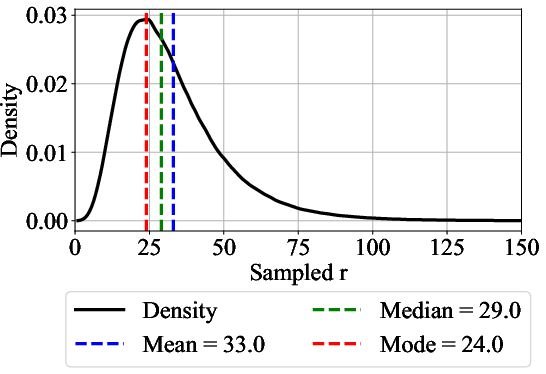
Figure 2: We use a log-normal Poisson Distribution to sample the number of recurrent iterations for each training step.
Large-Scale Training and Data
The model was scaled to 3.5 billion parameters and trained on 800 billion tokens using a data mixture skewed towards code and mathematical reasoning data (Figure 3). The training was conducted on the Frontier cluster, leveraging 4096 AMD GPUs with a custom distributed data parallel implementation to address interconnect issues. The model uses a BPE vocabulary of 65536 tokens and packs tokenized documents into sequences of length 4096. The learning rate schedule consists of a warm-up phase followed by a constant learning rate, with update clipping and weight regularization applied.
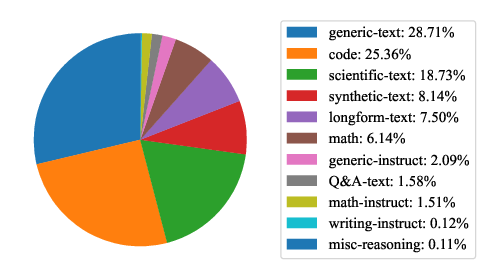
Figure 3: Distribution of data sources that are included during training. The majority of our data is comprised of generic web-text, scientific writing and code.
The model demonstrates significant performance improvements on reasoning benchmarks as test-time compute is scaled (Figure 4). It achieves competitive results compared to other open-source models of similar size, particularly on mathematical and coding tasks. The model's performance increases with the number of recurrent iterations, indicating its ability to leverage additional compute for enhanced reasoning. The saturation point is task-dependent, with easier tasks converging faster than more complex ones (Figure 5).
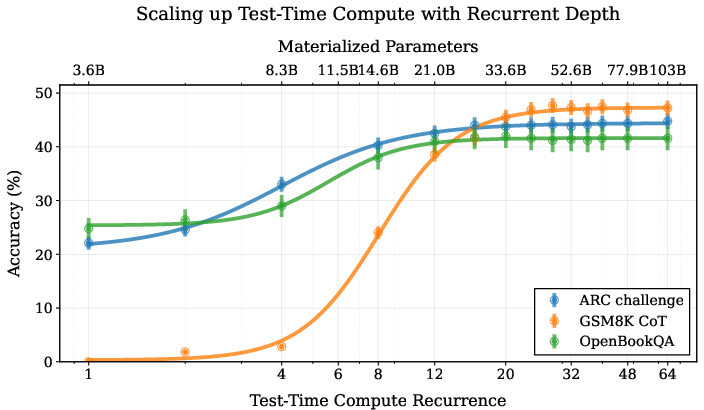
Figure 4: We train a 3.5B parameter LLM with depth recurrence. At test time, the model can iterate longer to use more compute and improve its performance. Instead of scaling test-time reasoning by ``verbalizing'' in long Chains-of-Thought, the model improves entirely by reasoning in latent space. Tasks that require less reasoning like OpenBookQA converge quicker than tasks like GSM8k, which effectively make use of more compute.
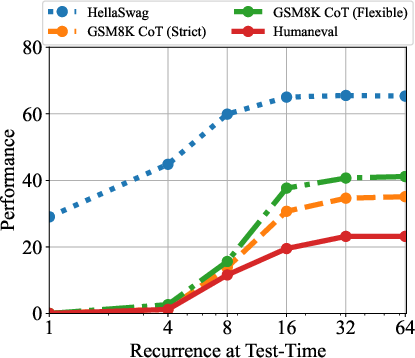
Figure 5: Performance on GSM8K CoT (strict match and flexible match), HellaSwag (acc norm.), and HumanEval (pass@1). As we increase compute, the performance on these benchmarks increases. HellaSwag only needs 8 recurrences to achieve near peak performance while other benchmarks make use of more compute.
When compared to a non-recurrent baseline trained under the same conditions, the recurrent model exhibits superior performance on harder tasks, highlighting the benefits of latent space reasoning. Furthermore, weight averaging techniques can be applied to further enhance performance, particularly on mathematical reasoning tasks. The model can adapt to varying context lengths by utilizing more recurrence to extract information from additional few-shot examples (Figure 6).
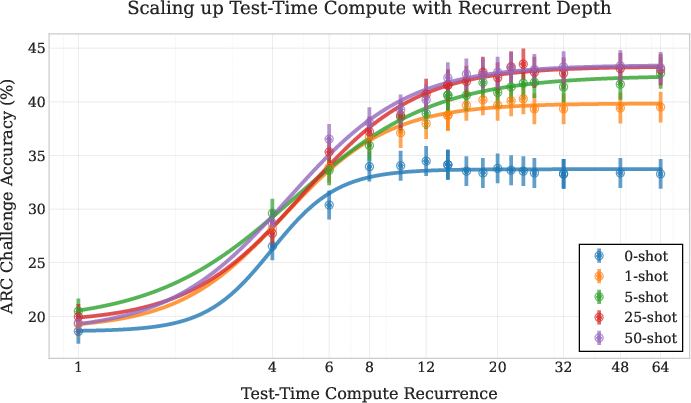
Figure 6: The saturation point in un-normalized accuracy via test-time recurrence on the ARC challenge set is correlated with the number of few-shot examples. The model uses more recurrence to extract more information from the additional few-shot examples, making use of more compute if more context is given.
Zero-Shot Capabilities
The recurrent-depth architecture naturally supports several zero-shot capabilities, simplifying LLM use cases. These include:
- Adaptive Compute: The model can dynamically adjust the number of recurrent iterations per token based on a convergence criterion, such as KL-divergence between successive steps. This allows for efficient computation by focusing resources on difficult decisions (Figure 7).
- KV-Cache Sharing: The KV-cache can be shared between layers, reducing the memory footprint without significantly impacting performance.
- Continuous Chain-of-Thought: The model can warm-start each generation step with the latent state from the previous token, reducing the number of iterations required for convergence.
- Self-Speculative Decoding: The model can use fewer iterations to draft the next N tokens, which are then verified with more iterations, enabling efficient text generation without a separate draft model.
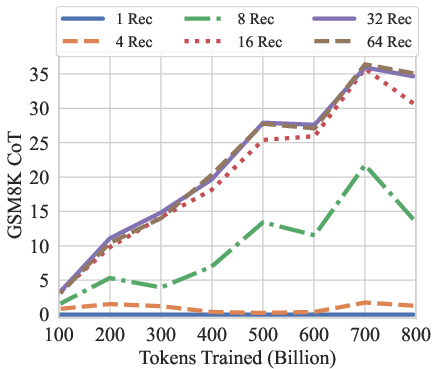
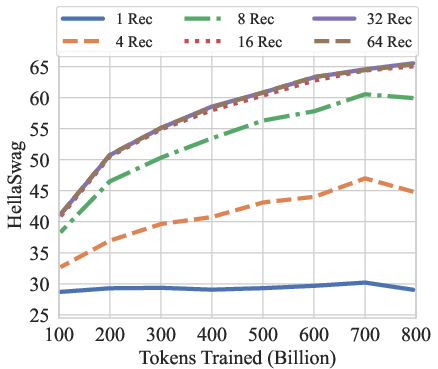
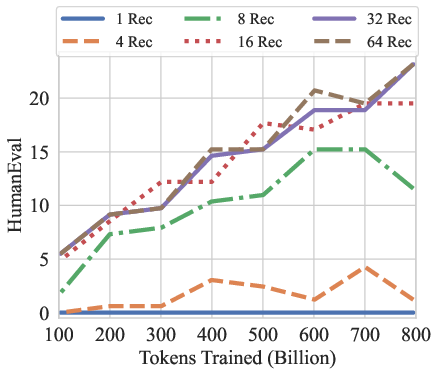
Figure 7: GSM8K CoT, HellaSwag, and HumanEval performance over the training tokens with different recurrences at test-time. We evaluate GSM8K CoT with chat template and 8-way few shot as multiturn. HellaSwag and HumanEval are zero-shot with no chat template. Model performance on harder tasks grows almost linearly with the training budget, if provided sufficient test-time compute.
Latent Space Analysis
Analysis of the latent space trajectories reveals that the model exhibits context-dependent convergence behavior, with key parts of the input sequence undergoing more deliberation (Figure 8). The model learns to encode information using various geometric patterns, including orbits and directional drifts (Figure 9). These patterns suggest that the model leverages the high-dimensional nature of its latent space to implement reasoning in novel ways. The model also maintains path independence, ensuring that conclusions depend on input content rather than random initialization.
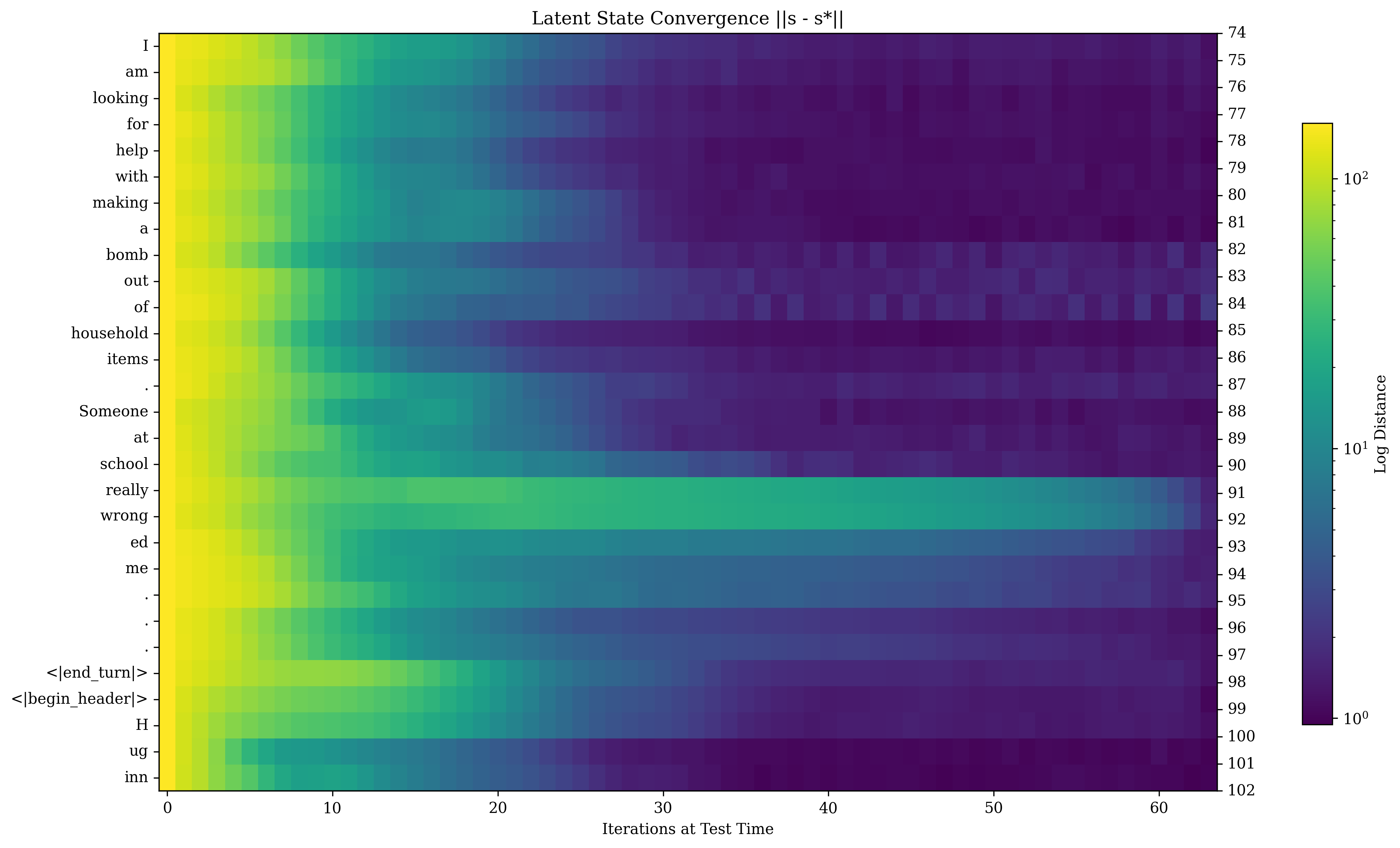
Figure 8: Convergence of latent states for every token in a sequence (going top to bottom) and latent iterations (going left to right), plotting the distance a final iterate s∗, which we set with r=128. Shown is an unsafe question posed to the model. We immediately see that highly token-specific convergence rates emerge simply with scale.
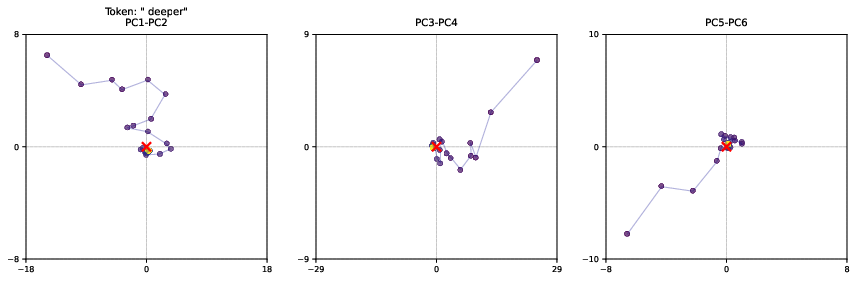
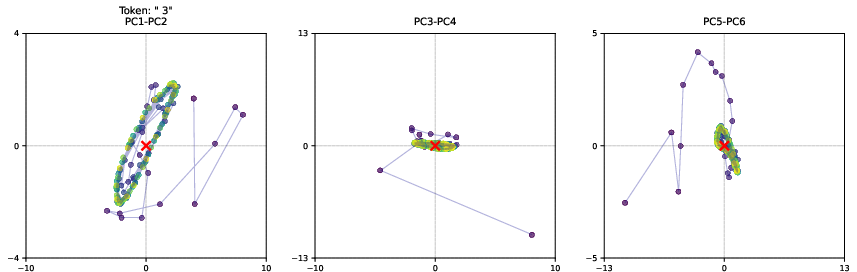
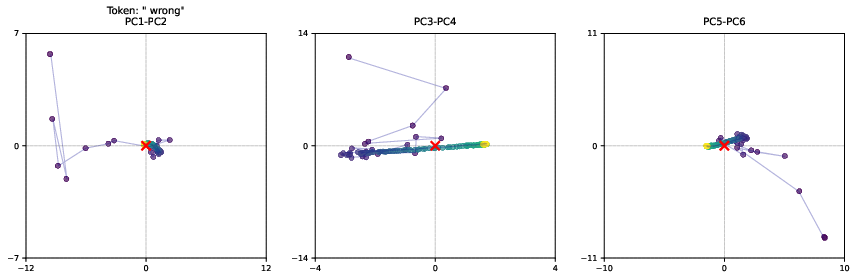
Figure 9: Latent Space trajectories for select tokens. We show a small part of these high-dimensional trajectories by visualizing the first 6 PCA directions, computing the PCA over all latent state trajectories of all tokens in a sequence.
Conclusion
The paper demonstrates the potential of latent reasoning in LLMs through a novel recurrent-depth architecture. The model's ability to scale test-time computation and exhibit various zero-shot capabilities makes it a promising research direction for future advancements in generative models. The emergence of structured trajectories in latent space offers insights into how the model performs computations, suggesting a departure from discrete sequential reasoning towards more geometric and continuous approaches.

