- The paper demonstrates a novel two-phase training pipeline with a cold-start chain-of-thought phase followed by domain-parallel reinforcement learning.
- It leverages a 560B-parameter sparse MoE architecture that averages 27B active parameters per inference for efficient, scalable performance.
- It achieves state-of-the-art results in reasoning, coding, and formal theorem proving while ensuring safety and efficiency across diverse benchmarks.
LongCat-Flash-Thinking: A 560B-Parameter Open-Source MoE Reasoning Model
Overview
LongCat-Flash-Thinking is a 560B-parameter Mixture-of-Experts (MoE) LLM designed for advanced reasoning, formal theorem proving, coding, and agentic tool use. The model is distinguished by a two-phase training pipeline: a cold-start curriculum focused on long Chain-of-Thought (CoT) reasoning, followed by a large-scale, domain-parallel reinforcement learning (RL) regime. The RL phase is powered by the DORA (Dynamic ORchestration for Asynchronous rollout) system, enabling efficient, stable, and scalable training across tens of thousands of accelerators. The model achieves state-of-the-art results among open-source models on a wide array of reasoning benchmarks, with notable efficiency in agentic reasoning and formal proof generation.
Model Architecture and Training Pipeline
LongCat-Flash-Thinking is built on a sparse MoE backbone, leveraging zero-computation experts and shortcut-connected expert parallelism for computational efficiency. The model averages 27B active parameters per inference, despite a total parameter count of 560B, enabling high throughput and memory efficiency.
The training pipeline consists of:
- Long CoT Cold-Start Training:
- Mid-training: Curriculum learning on reasoning-intensive STEM and coding data, with careful data mixing to avoid degradation of generalist capabilities.
- Supervised Fine-Tuning (SFT): Targeted exposure to formal reasoning (e.g., theorem proving) and agentic tool use, with rigorous data curation and quality control.
- Large-Scale RL with Domain-Parallelism:
Data Curation and Reasoning Enhancement
The cold-start phase addresses the scarcity of explicit long CoT patterns in pre-training corpora by constructing a curriculum of multi-step, competition-level STEM and coding problems. Data quality is ensured via LLM-as-a-Judge filtering, model-based voting, and difficulty stratification. For formal reasoning, an autoformalizer translates natural language problems into formal statements, which are then verified and iteratively expanded via expert iteration. Agentic reasoning data is curated using a dual-path evaluation pipeline to select queries that genuinely require tool use, with solution trajectories synthesized and validated for logical completeness and tool integration.
Reinforcement Learning Infrastructure and Algorithmic Innovations
DORA System
The DORA system is a distributed, asynchronous RL framework that addresses the inefficiencies of synchronous RL in long-context, reasoning-heavy tasks. Key features include:
- Streaming Rollout: Multiple policy versions are maintained, allowing responses to be generated and processed as soon as they complete, eliminating batch blocking by long-tail samples.
- Elastic Colocation: RL roles (generation, training, reward computation) are dynamically assigned to devices, minimizing idle time and maximizing hardware utilization.
- KV-Cache Reuse and Load Balancing: Efficient management of KV-caches and dynamic resource redistribution further reduce overhead.
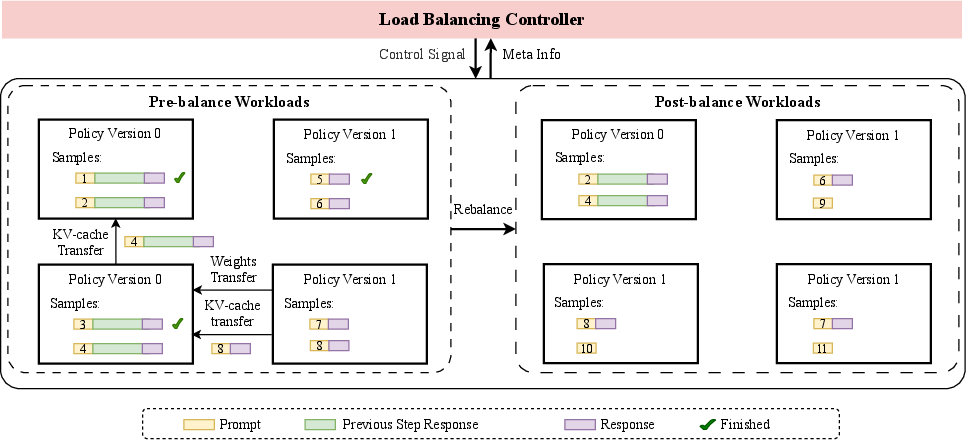
Figure 2: The workflow of Load Balancing. The Load Balancing Controller monitors the load on each device, and when predefined thresholds are met, it initiates resource redistribution, including weight transfer and KV-cache transfer.
RL Algorithmic Modifications
The RL phase employs a modified Group Relative Policy Optimization (GRPO) objective, with several critical adjustments for stability and efficiency:
- Token-Level Loss: Replaces sample-level loss to improve stability and mitigate length bias.
- Triplet Clipping: Separate clipping bounds for positive and negative advantages to control variance, especially important for sparse MoE routing.
- Truncated Importance Sampling: Mitigates distribution mismatch between inference and training engines.
- Staleness Control and Data Reuse: Promotes sample efficiency while maintaining policy freshness.
The reward system is domain-adaptive: discriminative reward models for non-verifiable tasks, generative reward models with reasoning for STEM, and sandbox-based evaluation for code.
Domain-Parallel RL and Model Fusion
Domain-mixed RL was found to induce negative transfer due to distributional shifts in response characteristics. The domain-parallel approach trains separate expert models for STEM, code, and agentic domains, which are then merged using normalization, dropout, and parameter erasure strategies to minimize interference. A final general RL phase ensures broad alignment and safety.
Empirical Results
LongCat-Flash-Thinking demonstrates strong performance across a comprehensive suite of benchmarks:
- Mathematical Reasoning: 99.2% on MATH-500, 93.3% on AIME-24, 83.7% on HMMT-25.
- Coding: 79.4% on LiveCodeBench, 40.7% on OJBench.
- Agentic Tool Use: 67.5% on τ2-Bench-Airline, 64.5% reduction in average token consumption on AIME-25 (from 19,653 to 6,965) without loss of accuracy.
- Formal Theorem Proving: 67.6% pass@1 on MiniF2F-Test, outperforming the next best open-source model by 18%.
- Safety: Best-in-class refusal rates on harmful, criminal, and misinformation queries.
System and Scaling Considerations
The DORA system achieves over 3x speedup compared to synchronous RL on 560B-parameter models, scaling efficiently to tens of thousands of accelerators. Engineering optimizations include graph-level compilation for MoE parallelism, bidirectional streaming RPC, and efficient load balancing. The system is robust to the numerical inconsistencies between inference and training engines, and supports high-throughput, long-context rollouts.
Implications and Future Directions
LongCat-Flash-Thinking establishes a new standard for open-source reasoning models, particularly in formal mathematics, coding, and agentic tool use. The domain-parallel RL and model fusion methodology provides a template for future large-scale, multi-domain LLM training. The DORA system demonstrates that asynchronous, streaming RL is viable and efficient at industrial scale, with implications for both research and production deployments.
The model's efficiency in agentic reasoning—achieving substantial token savings without accuracy loss—suggests that hybrid approaches combining LLM reasoning with external tool use will be increasingly important. The formal reasoning pipeline, leveraging autoformalization and expert iteration, points toward scalable methods for instilling formal verification capabilities in LLMs.
Open-sourcing LongCat-Flash-Thinking is likely to accelerate research in high-quality data curation, scalable RL, and agentic AI systems. Future work may explore more granular expert routing, further improvements in model fusion, and tighter integration of formal verification and tool use within LLMs.
Conclusion
LongCat-Flash-Thinking demonstrates that a carefully engineered MoE LLM, trained via a domain-parallel, RL-centric pipeline and supported by a robust asynchronous infrastructure, can achieve state-of-the-art reasoning performance with high efficiency. The model's architecture, training methodology, and system design collectively advance the state of open-source reasoning models and provide a foundation for further research in scalable, agentic, and formally capable AI systems.