- The paper introduces SSL4RL, which leverages self-supervised tasks as intrinsic rewards in RL to enhance visual-language reasoning.
- It repurposes classical tasks like rotation prediction, jigsaw puzzles, and contrastive learning to generate dense, verifiable rewards without extensive labeled data.
- The approach achieves significant improvements on benchmarks such as a 9% boost on MMBench and 8% on SEED-Bench, demonstrating its scalability and versatility.
SSL4RL: Leveraging Self-supervised Learning for Visual-Language Reasoning
Introduction
The paper "SSL4RL: Revisiting Self-supervised Learning as Intrinsic Reward for Visual-Language Reasoning" introduces a novel approach to integrating self-supervised learning tasks into the reinforcement learning paradigm for improving vision-LLMs (VLMs). The key innovation lies in using self-supervised learning (SSL) tasks as a scalable and verifiable source of rewards, addressing the challenge of aligning behavior in models that integrate visual and linguistic inputs. This framework, named SSL4RL, aims to reinforce visual grounding and reasoning without relying heavily on labeled data or human preferences, which are often scarce or biased.
SSL4RL Framework
SSL4RL repurposes traditional SSL tasks to generate reward signals suitable for RL optimization. The SSL tasks serve as a basis for formulating RL objectives, where the data perturbation defines trajectories, and the correctness of predictions against ground-truth targets provides dense reward signals. This approach eliminates the need for external verifiers, making it particularly attractive for domains where such verifiers aren't feasible.
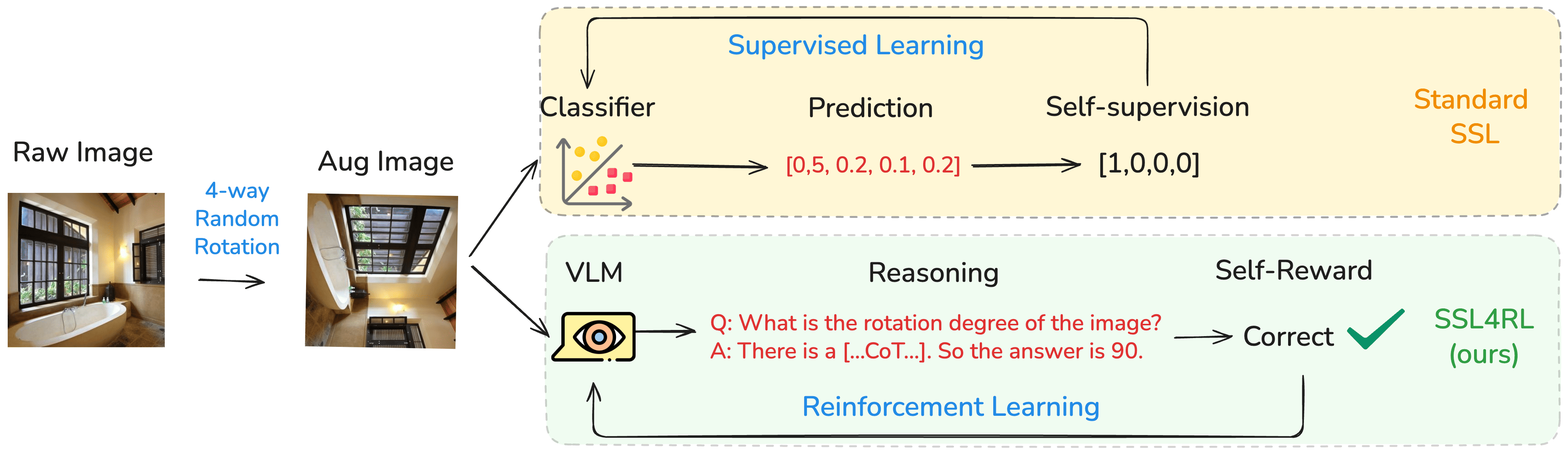
Figure 1: Overview of the SSL4RL framework. A corruption function transforms an input into a context--target pair. The model conditions on the context, generates predictions, and receives a verifiable reward by comparing against the target. The reward is then used to optimize the model via Reinforcement Learning (RL).
Self-supervised Tasks in SSL4RL
The paper considers several classical SSL tasks, reimagining them as RL problems within the SSL4RL framework:
- Rotation Prediction: Involves predicting the degree of rotation applied to an image, offering a straightforward yet effective task for model training.
- Jigsaw Puzzle: The model must unscramble image parts shuffled into a grid, encouraging detailed spatial reasoning.
- Contrastive Learning: Aims to ensure that transformed versions of an image are recognized as similar, promoting semantic understanding.
- Position Prediction: The task is to determine the original location of a cropped image patch, which supports contextual and spatial awareness.
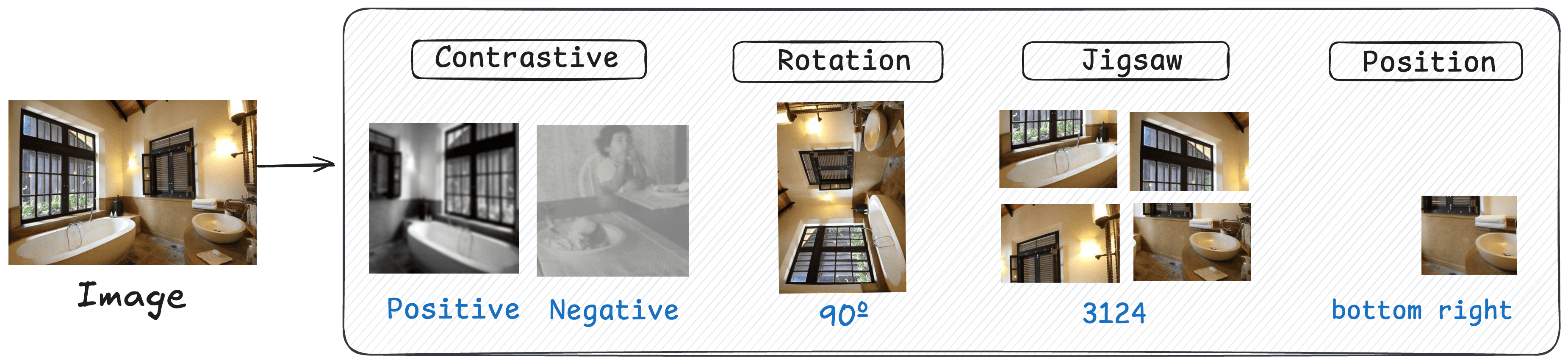
Figure 2: Four SSL4RL tasks considered in our study. Rotation: An image is rotated by a predefined angle, and the task is to predict this angle. Jigsaw: After dividing an image into a grid and permuting the patches, the goal is to predict the correct permutation index. Contrastive: Two augmented views are generated from an image, and the objective is to identify whether two given views originate from the same source image. Position: Given an image and a single patch cropped from it, the task is to predict the patch's original spatial position.
Experimental Evaluation
Experimental results validate the efficacy of SSL4RL across various benchmarks. The framework significantly enhances performance on vision-centric tasks like ImageNet classification, as well as multimodal reasoning benchmarks such as MMBench and SEED-Bench. Notably, the framework achieves an average improvement of approximately 9% on MMBench and 8% on SEED-Bench compared to baseline models without SSL4RL integration.
The scalability of SSL4RL to larger models is also explored, noting that while improvements persist, they are less pronounced as model capacity increases. This suggests a need for more complex SSL tasks to fully exploit the capabilities of larger architectures.
Trade-offs and Observations
One key finding is that the choice of SSL task critically impacts downstream performance. Tasks aligned with the inherent demands of the target domain, like Position and Rotation, often provide the most substantial benefits. Additionally, the difficulty of SSL tasks must be finely tuned to avoid overfitting or under-challenging the model, particularly as model size increases.
Another observation from the ablation studies is the non-additive nature of combining multiple SSL tasks. A naive combination yields no cumulative benefits, highlighting potential conflicts in learning objectives and the importance of careful task selection and integration.
Generalization Beyond Visual Data
The framework's adaptability is demonstrated by extending SSL4RL concepts to graph learning tasks, where similar improvements are observed. This generalization underscores the potential for applying SSL4RL across diverse data modalities, leveraging the holistic structural understanding it promotes.
Conclusion
SSL4RL emerges as a promising strategy for enhancing vision-LLMs by harnessing the strengths of self-supervised learning within an RL framework. This approach not only improves model performance without extensive human labeling but also paves the way for safer and more robust AI systems capable of deeper visual understanding. Future work will likely focus on evolving SSL tasks that dynamically scale with model capacity and domain-specific challenges, continuing to bridge the gap between perception and reasoning in AI systems.

