- The paper presents a novel framework integrating LLMs and VLMs with reinforcement learning, enhancing decision-making through well-defined agent, planner, and reward roles.
- It compares parametric and non-parametric methods for agent behavior, alongside comprehensive and incremental planning strategies that optimize task performance.
- The study demonstrates improved sample efficiency and interpretability, offering a promising pathway for more robust and scalable real-world RL applications.
The Evolving Landscape of LLM- and VLM-Integrated Reinforcement Learning
The integration of LLMs and Vision-LLMs (VLMs) with Reinforcement Learning (RL) represents a significant development in the field of machine learning, aiming to enhance RL by leveraging these models' capabilities in understanding and generating natural language and processing multimodal information.
Introduction
Reinforcement Learning (RL) is a cornerstone of machine learning focused on training autonomous agents to make decisions via trial-and-error interactions with their environment, represented as Markov Decision Processes (MDPs). Despite breakthroughs in domains like games and robotics, RL faces challenges such as sample inefficiency, poor generalization, and limited real-world applicability. LLMs, renowned for their prowess in natural language processing, and Vision-LLMs (VLMs) are increasingly popular for their capabilities in meaningfully connecting language and visual data. When integrated into RL systems, these foundation models (FM) offer promising enhancements: semantic understanding from LLMs and robust perception from VLMs, improving efficiency and interpretability in RL.
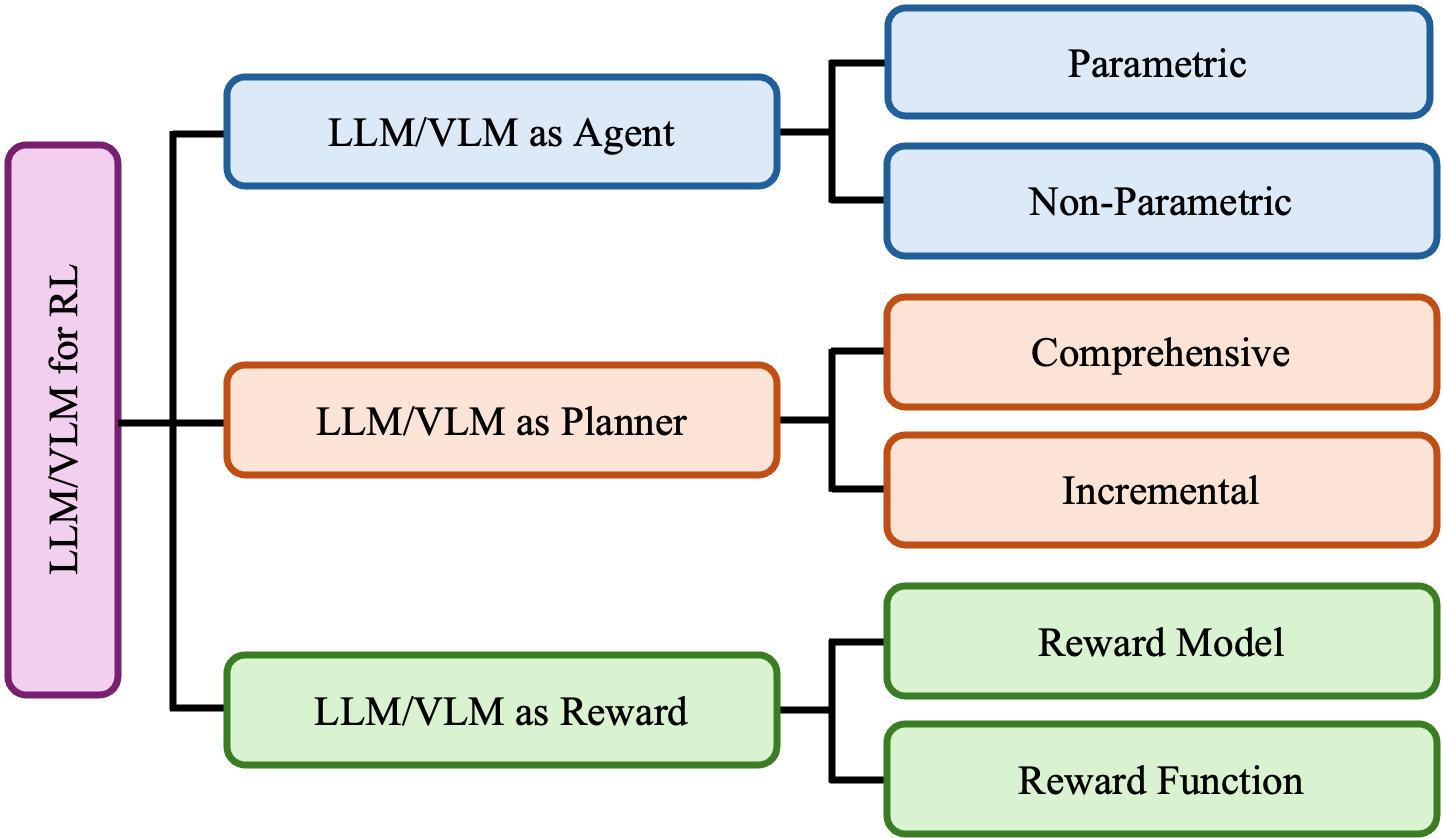
Figure 1: A taxonomy for LLM- and vlm-assisted rl.
Recent research categorizes the integration of LLMs and VLMs into RL under three roles: Agent, Planner, and Reward, where each plays crucial parts in boosting RL's capabilities by addressing specific challenges.
LLM/VLM as Agent
When LLMs and VLMs act as agents, they leverage their understanding and reasoning capabilities to make informed decisions within RL environments. Two approaches dominate: parametric and non-parametric.
Parametric Agents
Parametric agents fine-tune LLMs and VLMs to perform specific tasks by adapting their parameters through reinforcement learning methods like policy optimization and value-based approaches. These agents improve adaptability to and performance in complex dynamic environments by leveraging the deep learning architectures of LLMs for detailed and contextual data processing.
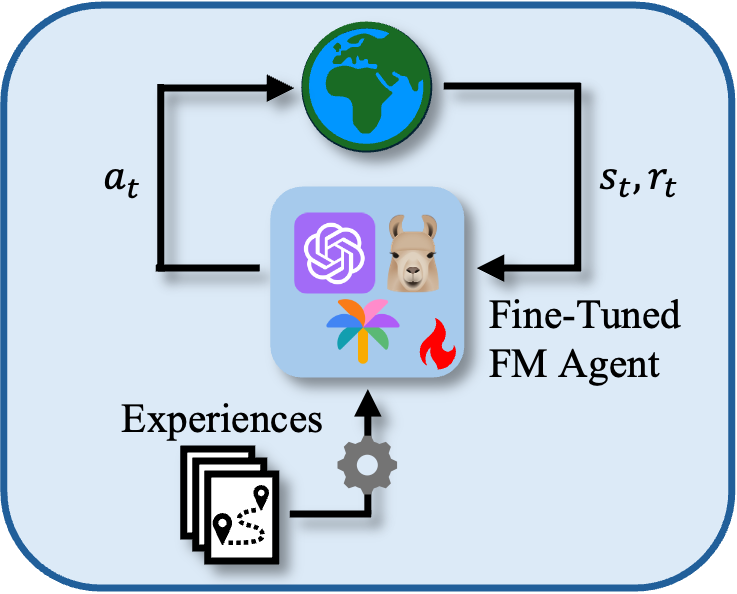
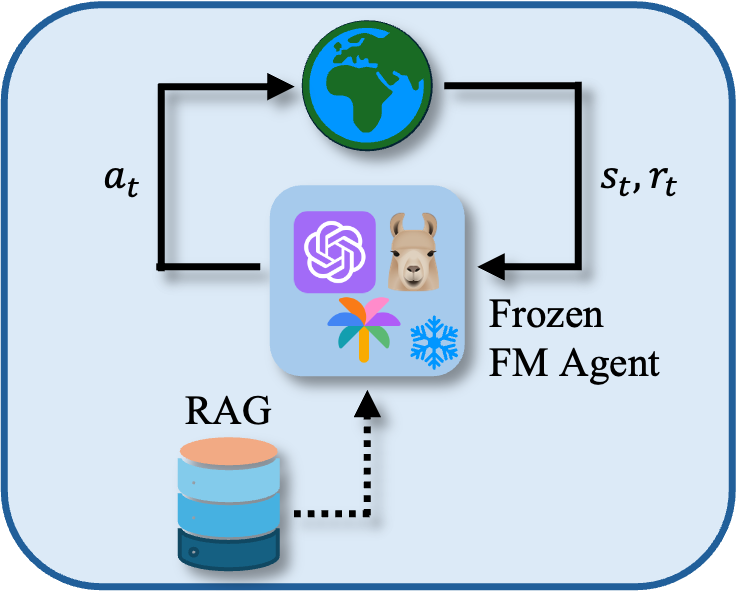
Figure 2: Parametric approach in LLM/VLM as agents, detailing tuning for specific task adaptation.
Non-parametric Agents
Non-parametric agents utilize external datasets and prompt engineering without altering model parameters, relying on the inherent power of LLMs for decision-making. This approach enhances generalization and reasoning capacity, allowing models to perform well across varied tasks without the computational overhead of deep parameter tuning.
LLM/VLM as Planner
LLMs and VLMs can decompose complex RL tasks into manageable sub-goals, serving as planners by utilizing their generative capabilities.
Comprehensive Planning
Comprehensive planning entails generating full sequences of sub-goals pre-action, leveraging extensive model knowledge to optimize task completion strategies.
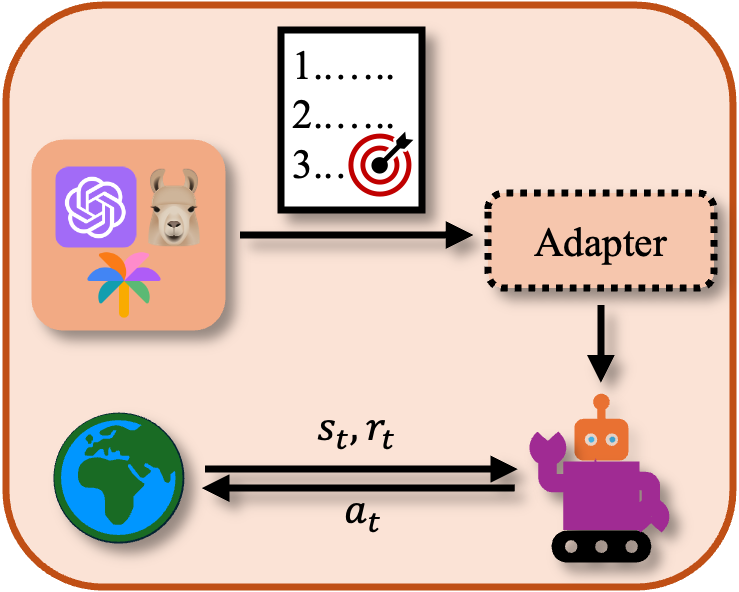
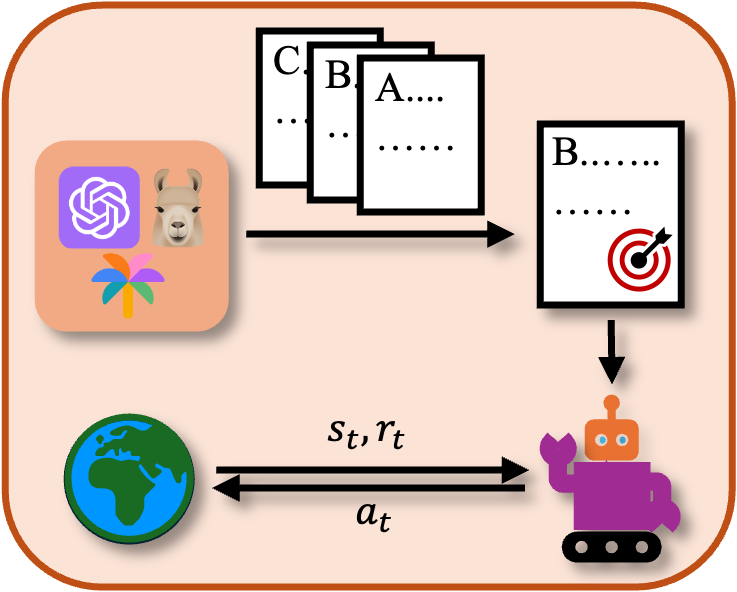
Figure 3: Comprehensive Planning approach leveraging LLM/VLMs for detailed task subdivision.
Incremental Planning
In contrast, incremental planning involves step-by-step, adaptable goal setting, enhancing decision-making flexibility though potentially incurring greater computational costs due to frequent model queries during execution.
LLM/VLM as Reward
Using LLMs and VLMs for automated reward function design alleviates one of RL's significant challenges by enabling models to autonomously interpret and transform linguistic and visual task descriptions into scalar rewards.
Reward Function
These models generate interpretable reward functions from textual prompts, iteratively refined for better alignment with task objectives. This approach promotes efficient and scalable reward specification, often matching or exceeding manually crafted designs in effectiveness.
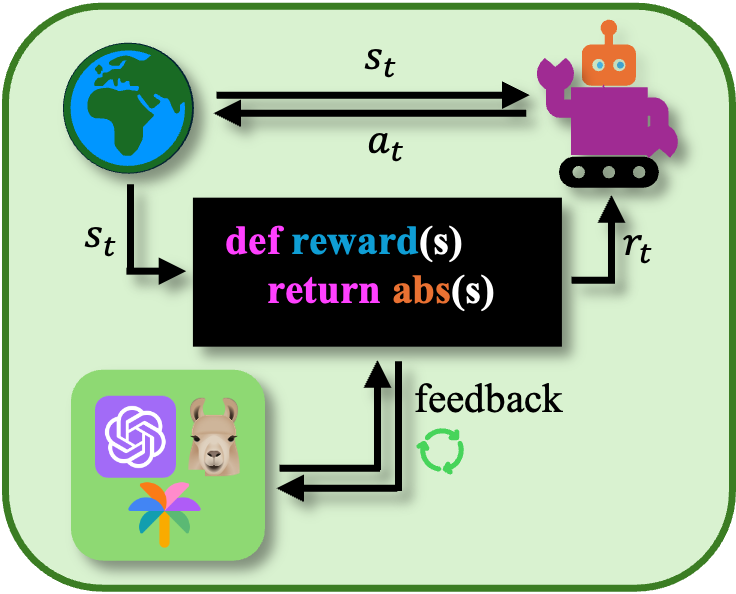
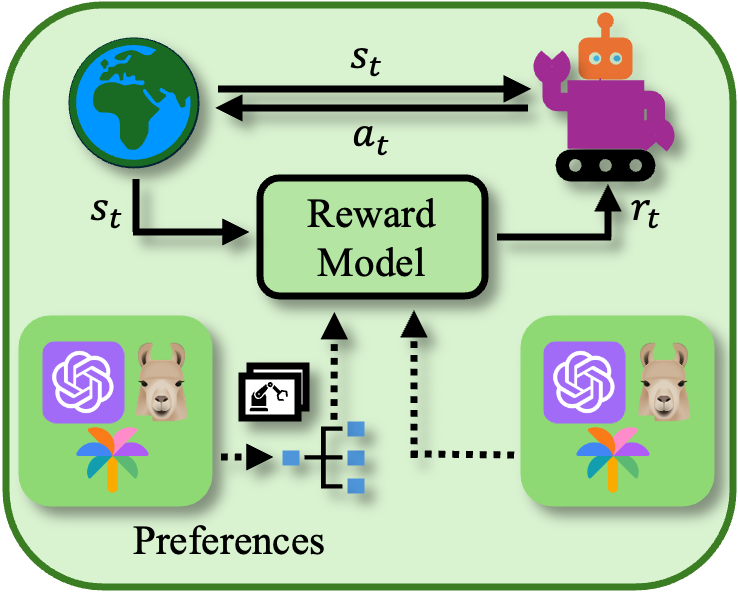
Figure 4: Reward Function generation process illustrating LLM/VLM capabilities in automated reward design.
Reward Model
Reward models are learned via LLM/VLM guidance, utilizing these models to interpret human feedback on agent behaviors and integrate diverse input modalities for more nuanced reward specification, mitigating ambiguity in complex visual tasks.
Conclusion
The integration of LLMs and VLMs into RL catalyzes a transformative enhancement of RL's scope and efficacy, addressing long-standing challenges and fostering more sophisticated, efficient, and adaptable learning systems. Future development should focus on grounding models more effectively in diverse real-world tasks, mitigating inherent biases, and advancing multimodal representation capabilities. These integrations have the potential to substantially refine and challenge our understanding of AI systems' capabilities, setting the stage for future explorations in AI research and application.