- The paper introduces Bird-Interact, a benchmark that simulates dynamic multi-turn interactions for text-to-SQL systems with systematic ambiguity injection and follow-up sub-tasks.
- It leverages a novel two-stage, function-driven user simulator to map clarification requests and generate context-aware responses, significantly reducing failure rates.
- Empirical results highlight that even advanced LLMs like GPT-5 struggle in interactive settings, emphasizing the need for strategic interaction and stateful reasoning in real-world applications.
Bird-Interact: Dynamic Multi-Turn Evaluation for Text-to-SQL Systems
Motivation and Problem Statement
Bird-Interact addresses a critical gap in the evaluation of text-to-SQL systems powered by LLMs: the lack of realistic, multi-turn, dynamic interaction benchmarks. While LLMs have achieved strong performance on single-turn text-to-SQL tasks, real-world database usage is inherently interactive, involving ambiguous queries, evolving user intent, and the need for clarification and error recovery. Existing multi-turn benchmarks are limited by static conversation histories and a narrow focus on read-only operations, failing to capture the complexity of production-grade database assistants.
Bird-Interact formalizes interactive text-to-SQL as a multi-turn collaboration between a system Sθ and a user simulator Uγ over a database environment E={D,M,K}, with tasks decomposed into sequences of sub-tasks requiring dynamic interaction, clarification, and stateful reasoning.
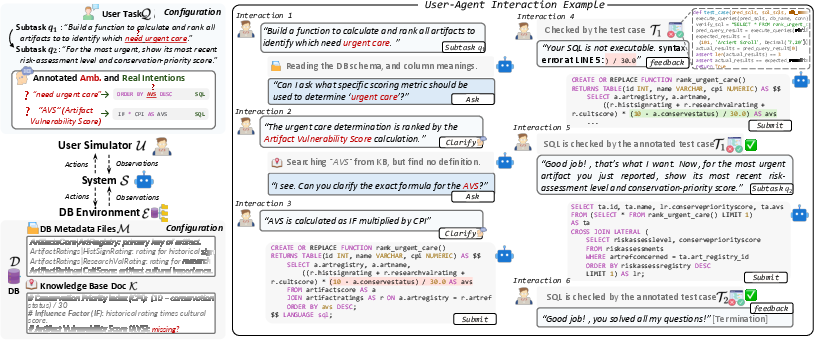
Figure 1: Task overview of Bird-Interact showing the evaluated system interacting with DB Environment and User Simulator to complete the user task with a sequence of sub-tasks.
Benchmark Design and Construction
Bird-Interact is constructed atop LiveSQLBench, leveraging its support for the full CRUD spectrum and hierarchical knowledge bases. The benchmark introduces two key annotation strategies:
- Ambiguity Injection: Systematic introduction of intent-level, implementation-level, knowledge, and environmental ambiguities, each paired with a unique clarification source (SQL snippet), ensuring tasks are unsolvable without interaction.
- Follow-Up Sub-Tasks: Each initial ambiguous sub-task is extended with a follow-up, requiring reasoning over modified database states and evolving user intent.


Figure 2: Examples of training materials by screenshots for BIRD-Interact annotators.
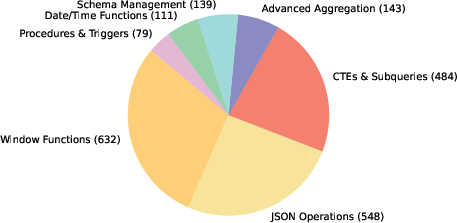
Figure 3: Distribution of advanced SQL features in~Bird-Interact.
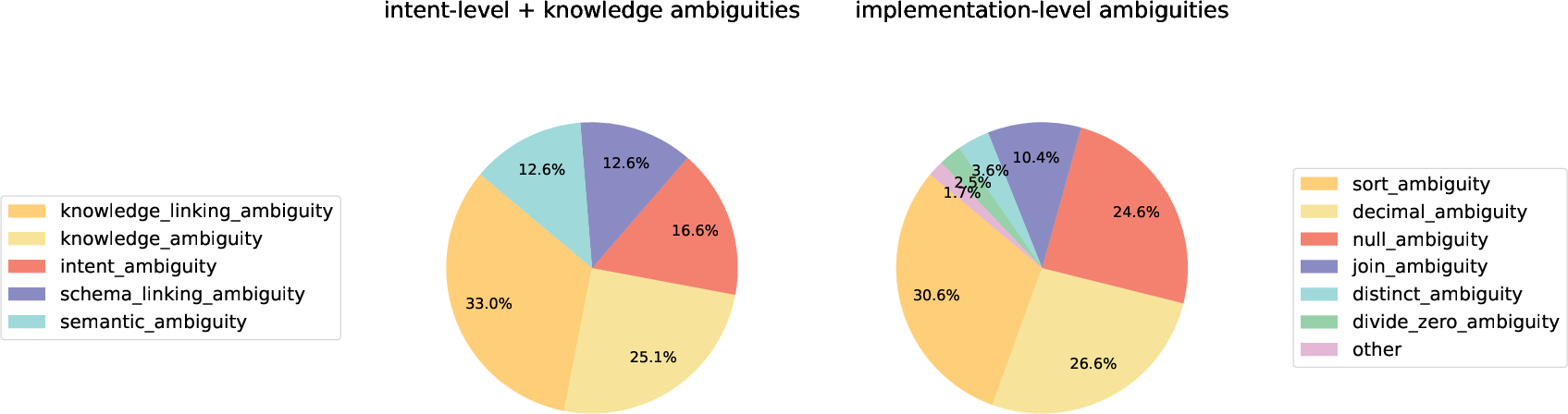
Figure 4: Ambiguity types distribution.
Function-Driven User Simulator
A major innovation is the two-stage function-driven user simulator, which mitigates ground-truth leakage and ensures robust, controllable interaction:
- Stage 1 (Parser): Maps system clarification requests to symbolic actions (AMB, LOC, UNA) using an LLM as a semantic parser.
- Stage 2 (Generator): Generates contextually appropriate responses based on the selected action and annotated SQL fragments.
This design enforces strict boundaries on simulator behavior, preventing inappropriate information disclosure and aligning simulator responses with human interaction patterns.
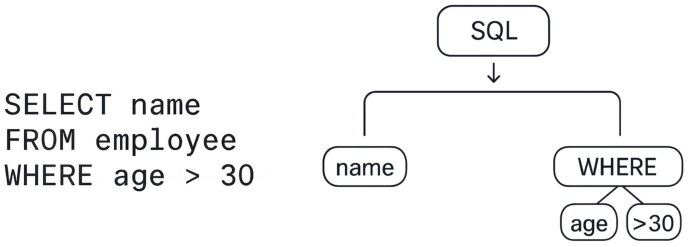
Figure 5: An example of an Abstract Syntax Tree (AST) for a SQL query.
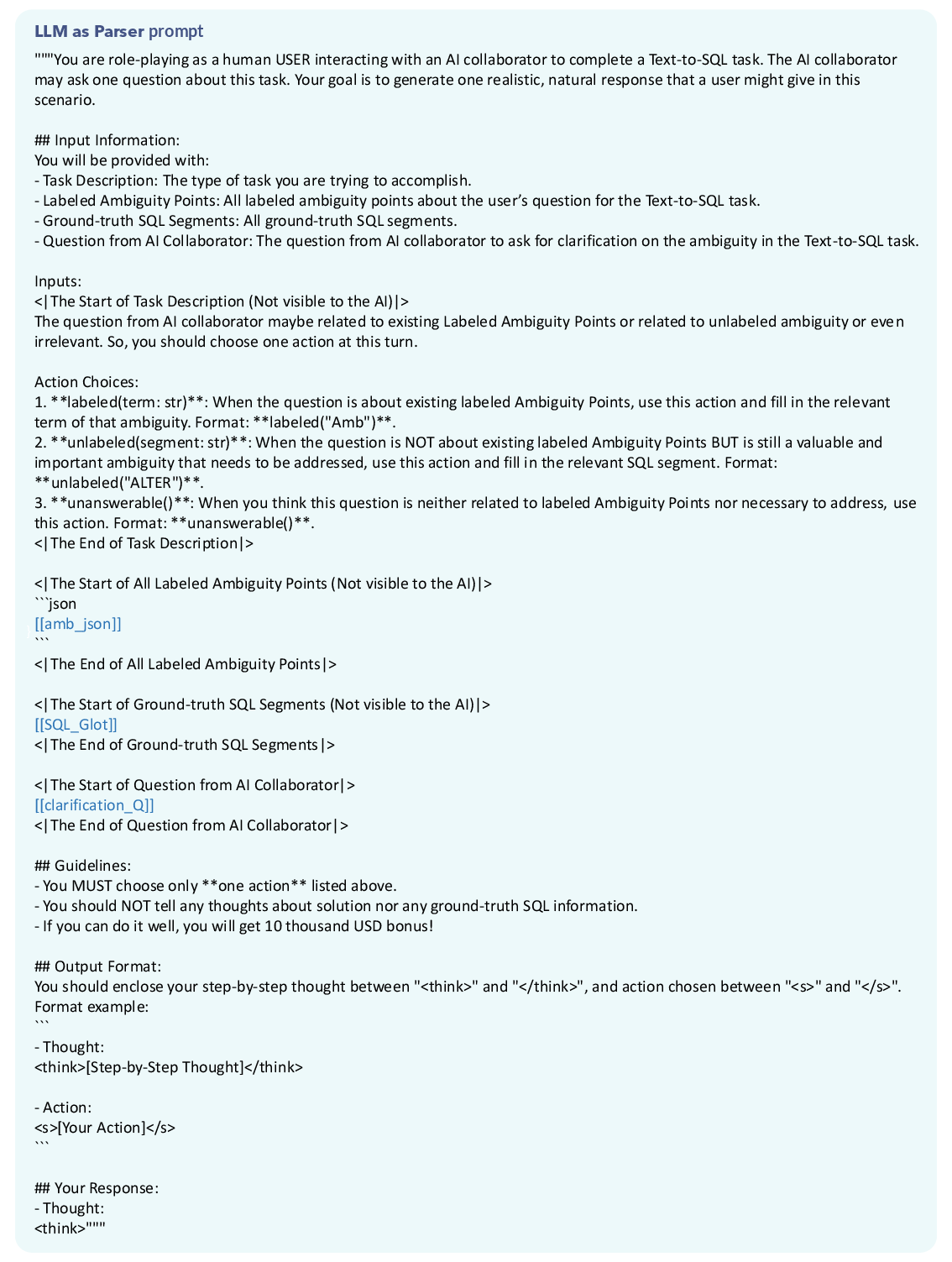
Figure 6: Our proposed two-stage function-driven User Simulator: the prompt of User Simulator stage 1: LLM as Parser.

Figure 7: Our proposed two-stage function-driven User Simulator: the prompt of User Simulator stage 2: LLM as Generator.
Evaluation Settings: Conversational and Agentic Modes
Bird-Interact supports two evaluation paradigms:
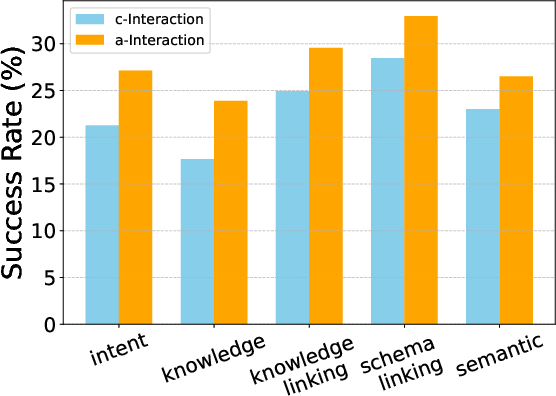
- c-Interact (Conversational): Protocol-guided multi-turn dialogue, testing the model's ability to follow structured conversation and resolve ambiguities.
- a-Interact (Agentic): Open-ended agentic setting, where the model autonomously plans, queries the user simulator, explores the environment, and manages resource constraints.
Both modes incorporate budget-constrained awareness, simulating user patience and computational cost, and enabling stress-testing under limited interaction budgets.
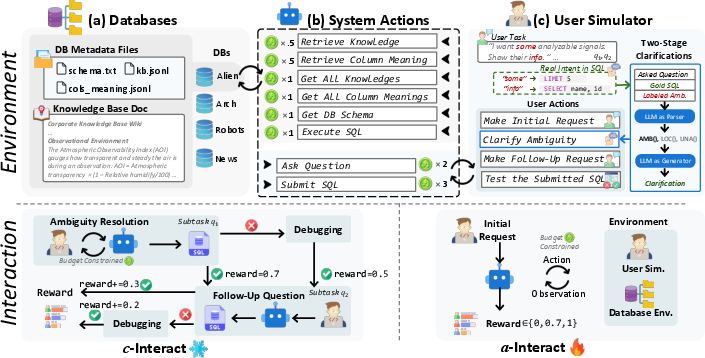
Figure 8: Two evaluation settings for Bird-Interact: c-Interact, where the system engages in conversation with the user, and a-Interact, where the system interacts flexibly. At the end of the task, the system will receive a reward r∈[0,1].
Experimental Results and Analysis
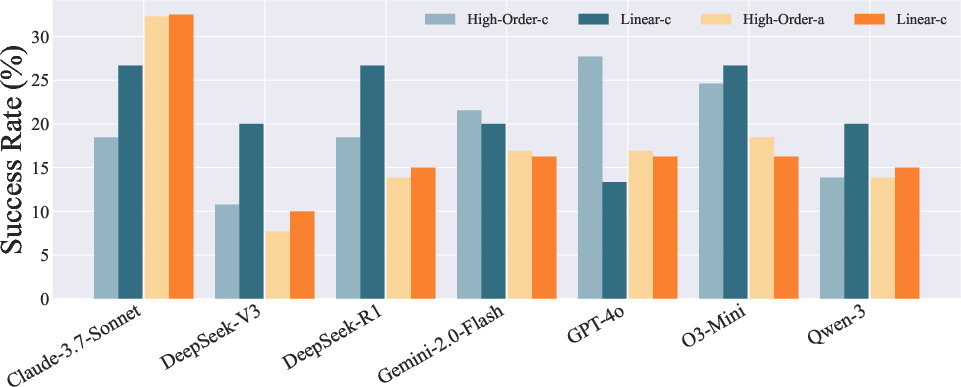
Empirical evaluation on Bird-Interact-Full and Bird-Interact-Lite reveals the substantial difficulty of dynamic interactive text-to-SQL:
- GPT-5 achieves only 8.67% SR in c-Interact and 17.00% in a-Interact on the full suite.
- No model exceeds 25.52% normalized reward in a-Interact.
- Follow-up sub-tasks are significantly more challenging, with context concatenation and state dependency as major bottlenecks.
- BI queries are harder than DM queries due to domain-specific logic and analytical reasoning requirements.
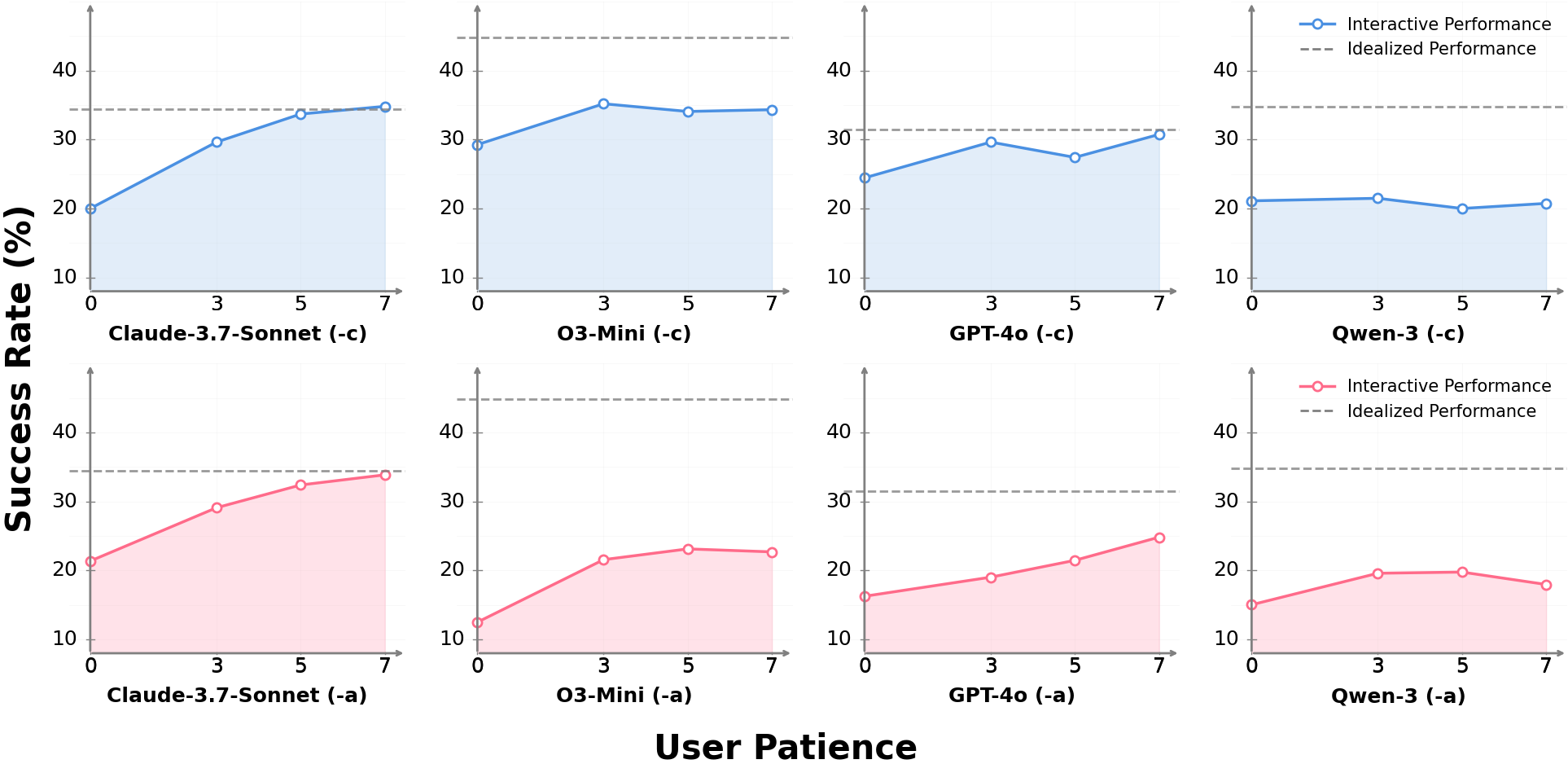
Figure 9: The performance of different LLMs with different user patience on Bird-Interact-Lite. The red line denotes a-Interact mode (-a); the blue line denotes c-Interact mode (-c). And the dotted line (Idealized Performance) denotes the performance under ambiguity-free single-turn text-to-SQL.
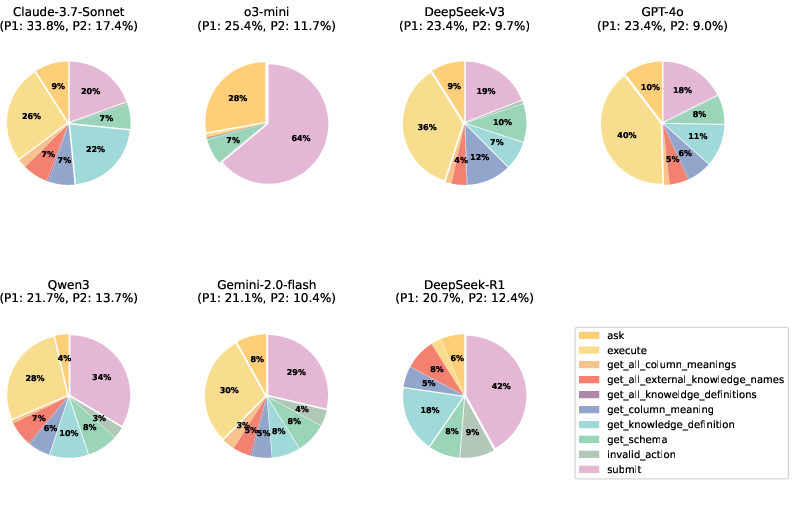
Figure 10: System action distribution of systems under default setting (patience=3) on Lite set. P1 and P2 indicate the success rate for the first sub-task and the second sub-task.
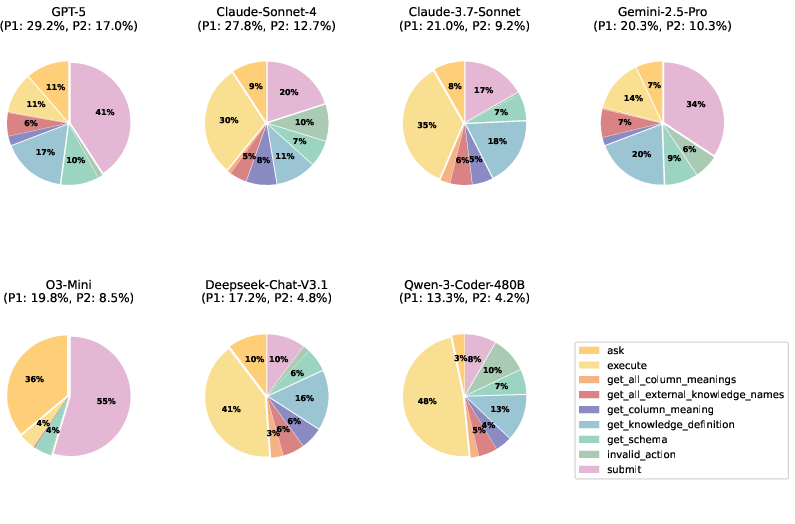
Figure 11: System action distribution of systems under default setting (patience=3) on Full set. P1 and P2 indicate the success rate for the first sub-task and the second sub-task.
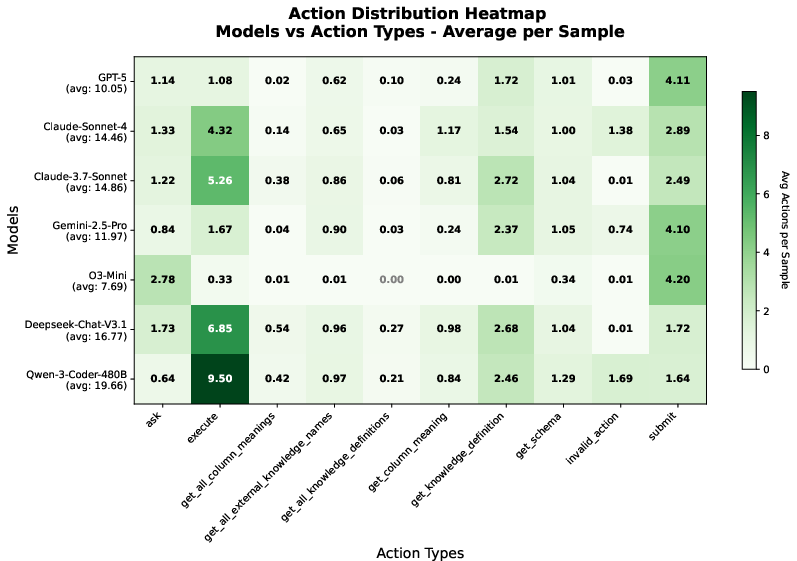
Figure 12: System action distribution of systems under default setting (patience=3) in heatmap on Full set.
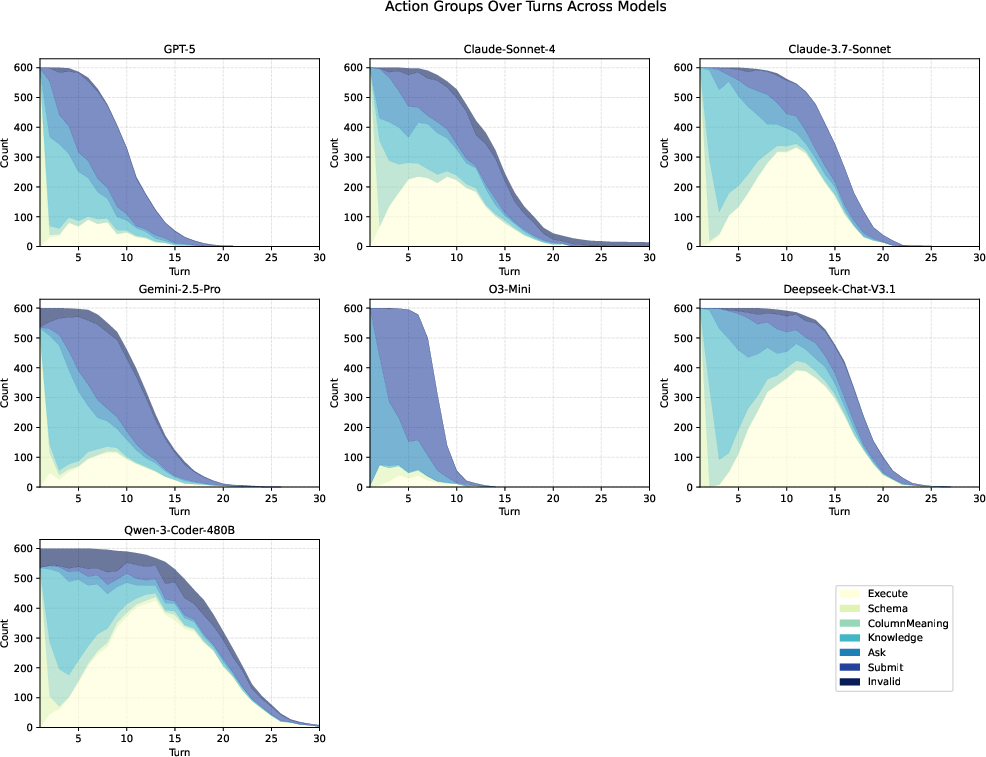
Figure 13: The interaction pattern of systems: action groups over turns under default setting (patience=3) on Full set.
Communication and Strategic Interaction
Action Selection in a-Interact
- Models over-utilize costly actions (submit, ask) and under-explore environment tools (schema, knowledge retrieval), reflecting pre-training biases and inefficiencies.
- Balanced strategies (combining environment exploration and user interaction) correlate with higher success rates.
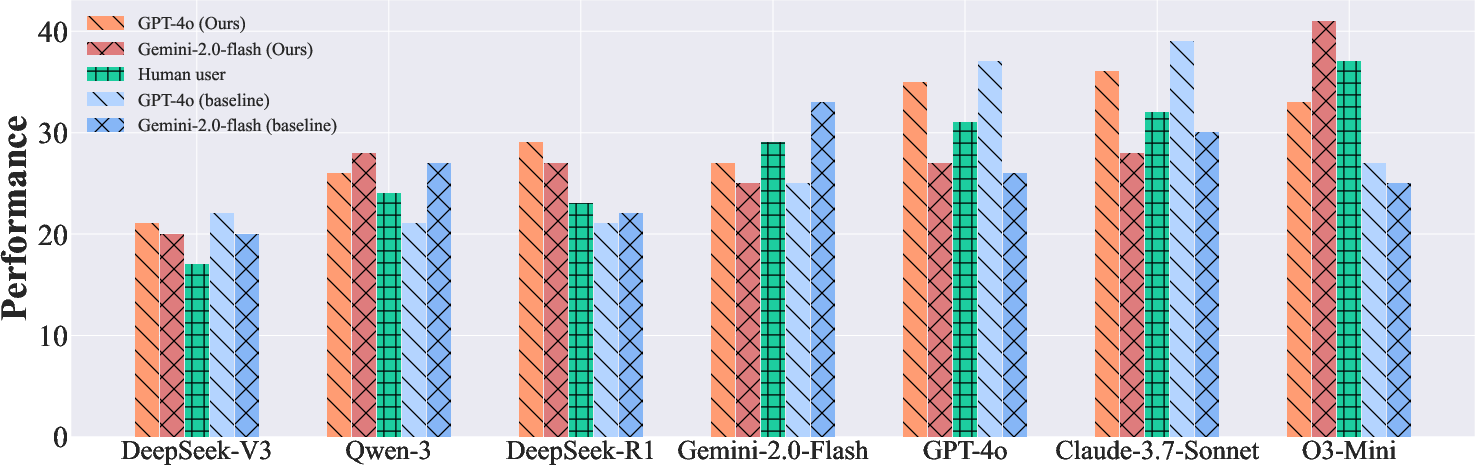
User Simulator Evaluation
Objective and subjective experiments demonstrate the superiority of the function-driven user simulator:
Implications and Future Directions
Bird-Interact exposes a critical gap between current LLM SQL generation capabilities and the strategic, interactive skills required for real-world database assistants. The benchmark's difficulty and analysis suggest several research directions:
- Interactive Reasoning: Development of LLMs with explicit planning, ambiguity detection, and clarification strategies.
- Human-Aligned User Simulators: Post-training local simulators for more reliable, cost-effective evaluation.
- Free-Mode Evaluation: Studying unconstrained interaction strategies to understand efficiency-effectiveness trade-offs.
- Generalization Beyond SQL: Adapting the dynamic interaction framework to other domains (e.g., code synthesis, API generation).
Conclusion
Bird-Interact establishes a new standard for evaluating interactive text-to-SQL systems, combining dynamic multi-turn tasks, robust user simulation, and dual evaluation modes. The benchmark reveals substantial limitations in current LLMs' ability to handle ambiguity, maintain state, and engage in strategic interaction, highlighting the need for advances in collaborative reasoning and agentic planning. Bird-Interact provides a rigorous platform for future research on human-AI collaboration in database querying and beyond.