- The paper introduces EmbodiedEval, a benchmark featuring 328 tasks across 125 3D scenes to evaluate MLLMs as embodied agents.
- It employs a unified simulation framework to test capabilities in navigation, object and social interactions, and spatial reasoning.
- Experimental results reveal significant performance gaps, with even state-of-the-art models like GPT-4o underperforming compared to humans.
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
EmbodiedEval provides a comprehensive benchmark for evaluating Multimodal LLMs (MLLMs) as embodied agents, addressing a tangible gap in current benchmark design which often prioritizes static evaluations or task-specific assessments. By integrating diverse and interactive environments, EmbodiedEval facilitates a more holistic evaluation of MLLMs' capabilities, with tasks that span multiple categories, environments, and interaction types.
Motivation and Contributions
Traditional benchmarks for evaluating MLLMs primarily rely on non-interactive formats such as static images or pre-recorded videos, neglecting the dynamic and interaction-heavy scenarios that these models are increasingly applied to. Moreover, existing embodied AI benchmarks tend to focus narrowly on specific tasks or are limited in diversity, failing to encompass the full spectrum of capabilities expected from embodied agents. EmbodiedEval addresses these limitations by offering 328 distinct tasks across 125 diverse 3D scenes, covering a broad spectrum of existing embodied AI tasks. The tasks are organized into five main categories: navigation, object interaction, social interaction, attribute question answering, and spatial question answering (Figure 1).

Figure 1: Examples of the five task categories in EmbodiedEval. On the left are the task text and part of the action space. On the right are observations from specific steps, along with the actions taken in the expert demonstration at those moments.
Design of EmbodiedEval
Task Categories
EmbodiedEval synthesizes tasks into five categories to rigorously assess the capabilities of MLLMs as embodied agents:
- Navigation: Tasks requiring agents to follow natural language instructions to move from one point to another.
- Object Interaction: Agents change the state of the environment through direct interactions with objects.
- Social Interaction: Evaluations include human-agent interactions such as item delivery and non-verbal communication comprehension.
- Attribute Question Answering (AttrQA): Involves questions about the environment's objects and scenes, emphasizing the agent’s ability to explore and understand attributes.
- Spatial Question Answering (SpatialQA): Tasks that test the agent's understanding of spatial relationships and reasoning.
Evaluation Framework
EmbodiedEval implements a unified simulation and evaluation framework, which dynamically engages the agent in the task environment:
- Action Space: Incorporates movement, interaction, and answering spaces. Movement topology is represented by a navigation graph simplifying decision making while maintaining task complexity.
- Success Criteria: Success is automatically determined through predicates that map environment state to success conditions, ensuring objective evaluation.
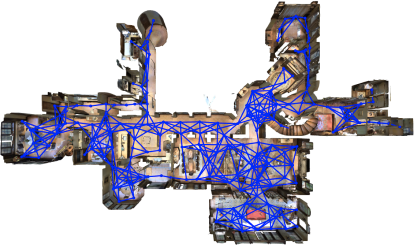
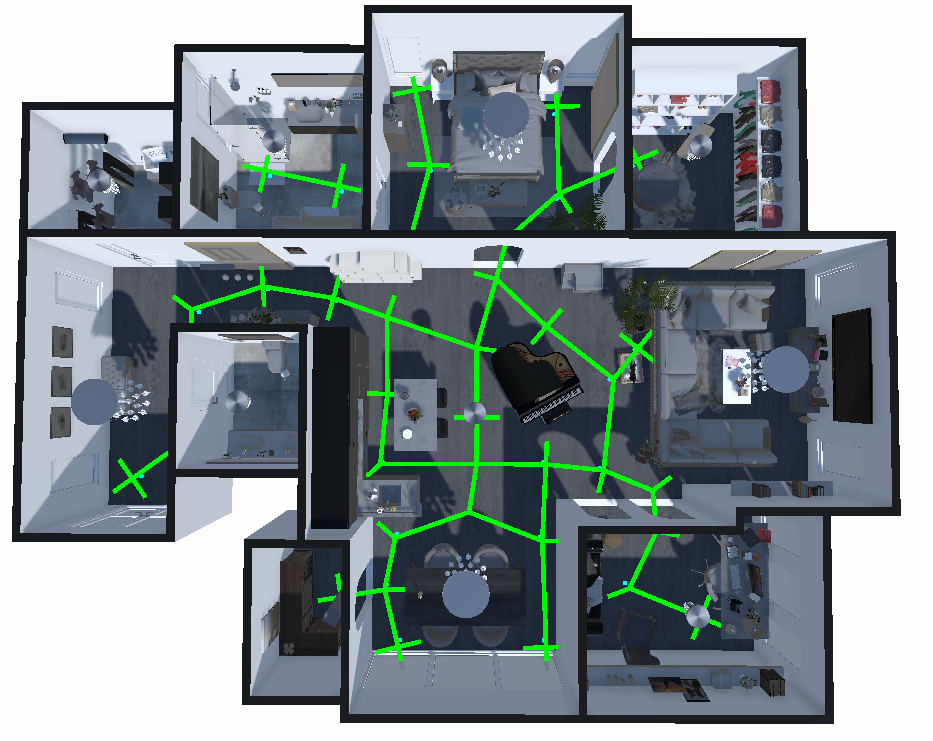
Figure 2: A comparison of navigation graphs between R2R dataset (left) and EmbodiedEval (right).
Dataset Construction
The dataset is constructed using scenes from various rich sources, including Objaverse and AI2THOR, with tasks systematically generated for diversity. Detailed annotation ensures each task has clear requirements and conditions for successful completion, facilitating reliable benchmark evaluation (Figure 3).

Figure 3: The dataset construction pipeline of EmbodiedEval.
Experimental Results
The evaluation of multiple MLLMs on EmbodiedEval demonstrated significant gaps between model performance and human-level capabilities. While human participants achieved near-perfect scores, the best-performing model, GPT-4o, achieved only a 25.00% success rate and a mere 32.42% GcS score, highlighting the persistent challenges that these models face in embodied scenarios. Models exhibited strong performance variance across task categories, with pronounced difficulties in tasks that require advanced dynamic interactions, including object and social interactions (Figure 4).
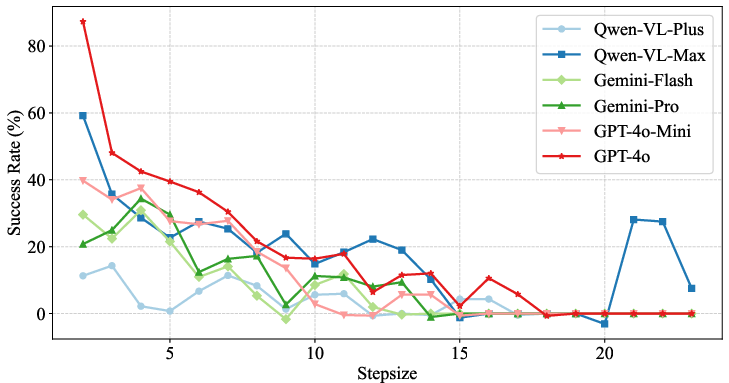
Figure 4: Success rate vs. number of steps required for the task.
Error Analysis and Insights
Four primary error categories were identified across MLLMs:
- Hallucination in Grounding: Misidentification or the perception of nonexistent objects.
- Insufficient Exploration: Ineffective environment exploration strategies leading to incomplete information gathering.
- Lack in Spatial Reasoning: Challenges in understanding and applying spatial relationships.
- Wrong Planning: Poor overall execution of task strategies.
These errors underline deficiencies in current models' interactive capabilities, suggesting important avenues for future improvement (Figure 5).

Figure 5: Case study of common error categories. In Hallucination in Grounding, the agent mistakenly identified a single blue sofa as two. In Insufficient Exploration, the agent failed to look for additional items. In Lack in Spatial Reasoning, the agent misestimated the distance between objects. In Wrong Planning, the agent did not organize the picking up and putting down of the vases in the proper order and at the correct positions.
Conclusion
EmbodiedEval provides a crucial tool for advancing the evaluation of MLLMs in interactive, embodied environments. Its comprehensive, diverse benchmark facilitates deeper insight into embodied agent capabilities and highlights existing limitations. The insights drawn from current experiments suggest avenues for advancing model training and architecture to bring embodied capabilities closer to human performance levels. Future research will benefit from EmbodiedEval as it continues to push the boundaries of what is possible in dynamic AI applications.