SWE-SQL: Illuminating LLM Pathways to Solve User SQL Issues in Real-World Applications
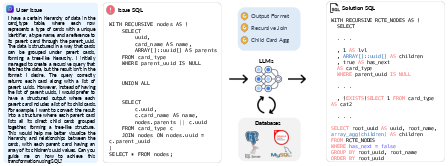
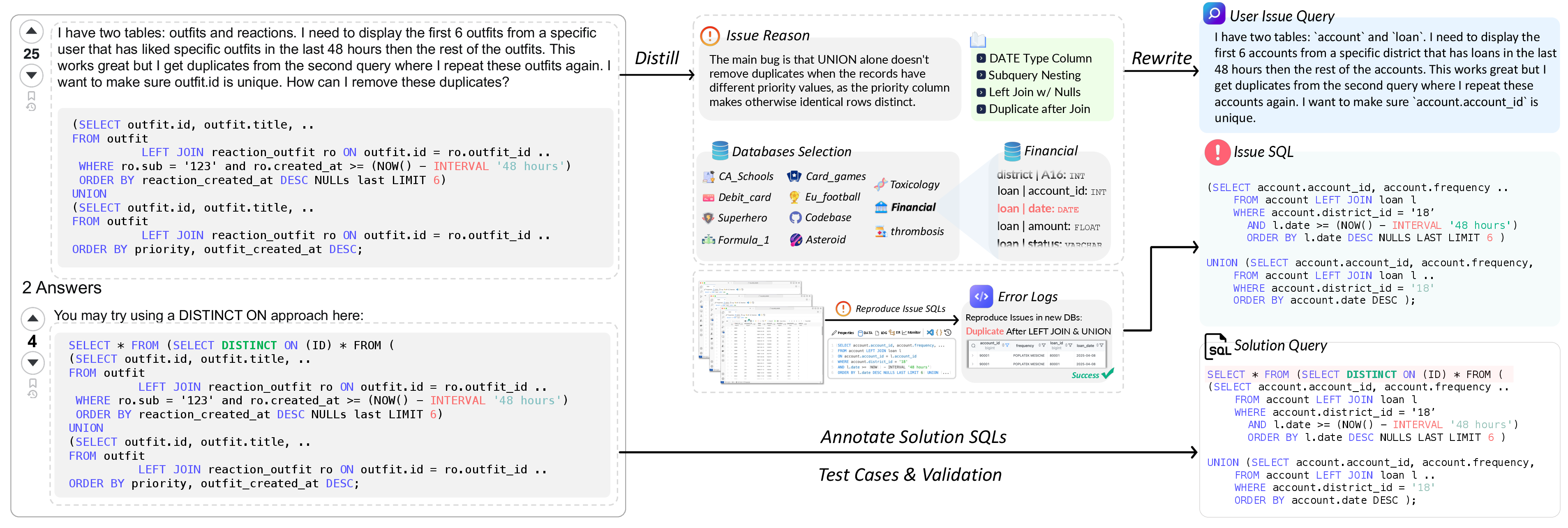
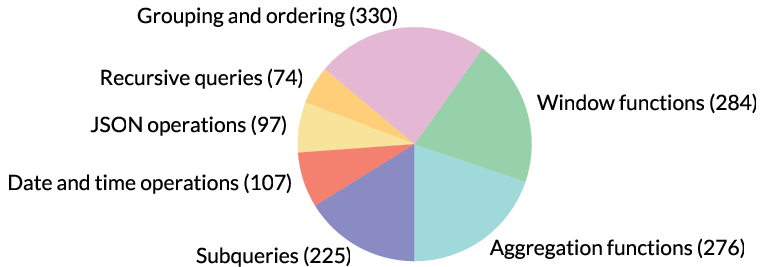
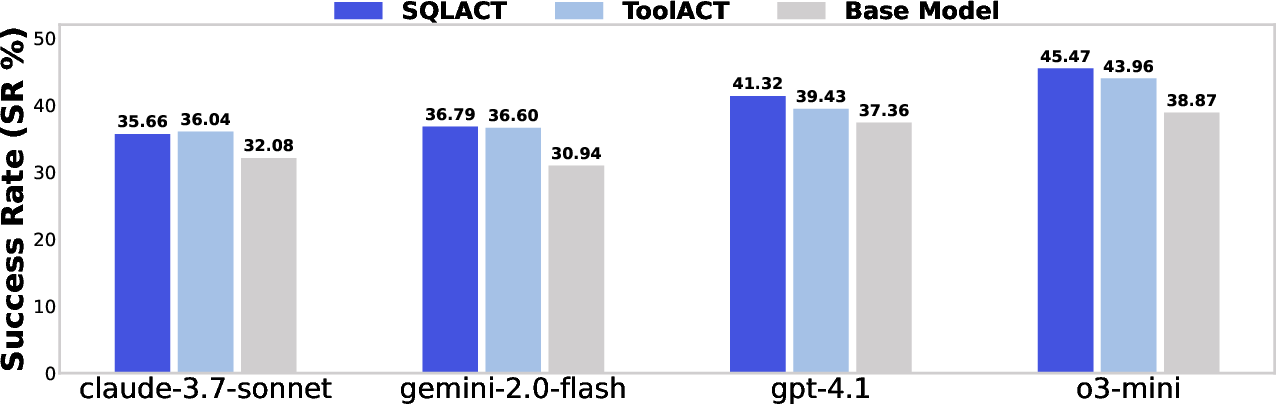
Abstract: Resolution of complex SQL issues persists as a significant bottleneck in real-world database applications. Current LLMs, while adept at text-to-SQL translation, have not been rigorously evaluated on the more challenging task of debugging SQL issues. To address this gap, we introduce BIRD-CRITIC, a new SQL issue debugging benchmark comprising 530 PostgreSQL tasks (BIRD-CRITIC-PG) and 570 multi-dialect tasks (BIRD-CRITIC-Multi), distilled from authentic user issues and replayed within new environments to facilitate rigorous evaluation. Baseline evaluations underscore the task's complexity, with the leading reasoning model O3-Mini achieving only 38.87% success rate on BIRD-CRITIC-PG and 33.33% on BIRD-CRITIC-Multi. Meanwhile, advancing open-source models for database tasks is crucial for empowering local development while safeguarding data privacy. Therefore, we present Six-Gym (Sql-fIX-Gym), a training environment for elevating open-source model capabilities for SQL issue debugging. This environment leverages SQL-Rewind strategy, which automatically generates executable issue-solution datasets by reverse-engineering issues from verified SQLs. However, popular trajectory-based fine-tuning methods do not explore substantial supervisory signals. We further propose f-Plan Boosting, which extracts high-level debugging plans from SQL solutions, enabling teacher LLMs to produce 73.7% more successful trajectories for training. We integrate these components into an open-source agent, Bird-Fixer. Based on Qwen-2.5-Coder-14B, Bird-Fixer achieves 38.11% success rate on BIRD-CRITIC-PG and 29.65% on BIRD-CRITIC-Multi, surpassing leading proprietary models such as Claude-3.7-Sonnet and GPT-4.1, marking a significant step toward democratizing sophisticated SQL-debugging capabilities. The leaderboard and source code are available: https://bird-critic.github.io/
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.