- The paper presents Bird, a benchmark that generates SQL from natural language queries using large-scale databases.
- It introduces innovative evaluation metrics like Execution Accuracy and Valid Efficiency Score to assess both correctness and efficiency.
- The study highlights challenges with noisy data values and external knowledge integration, guiding future text-to-SQL research.
Can LLM Already Serve as a Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
This paper presents Bird, a large-scale benchmark designed to address the gap between academic studies and real-world applications in text-to-SQL tasks. Bird focuses on generating SQL queries from natural language questions grounded with large-scale databases. It aims to improve the understanding and efficiency of text-to-SQL models concerning vast and noisy data values, external knowledge grounding, and SQL efficiency.
Introduction
Text-to-SQL is the process of transforming natural language questions into SQL queries, enabling users to retrieve relevant data from databases effortlessly. Despite notable progress with models such as GPT-4, the prevalent benchmarks do not sufficiently account for the challenges posed by large-scale database values. Bird addresses this by encompassing vast databases, complex database types, external reasoning requirements, and efficiency considerations. The benchmark includes 12,751 text-to-SQL pairs over 95 databases, covering diverse professional domains.

Figure 1: Examples of challenges in our Bird benchmark, illustrating noisy data types, external knowledge requirements, and efficiency considerations.
Benchmark Characteristics
Bird introduces several novel attributes that differentiate it from existing benchmarks. One of the key features is the emphasis on database values rather than purely focusing on schema. This highlights new challenges such as handling noisy data types and integration of external knowledge for efficient SQL generation.
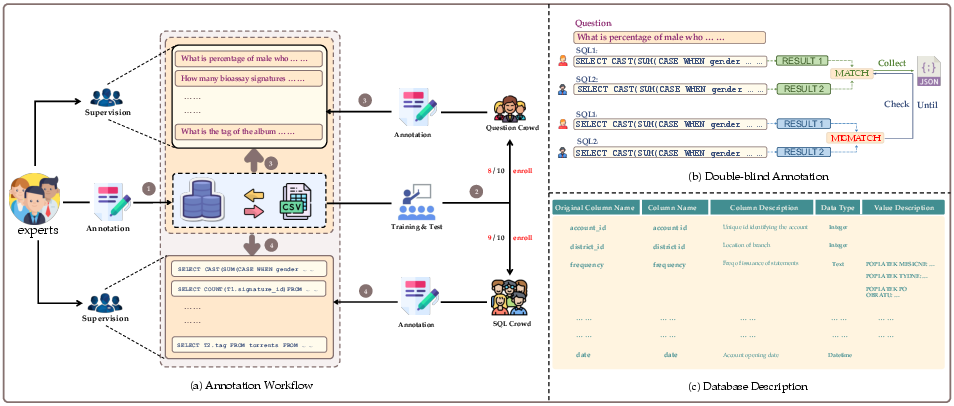
Figure 2: An Overview of the Bird Annotation Workflow displaying database assembly, teaching crowdsourcing participants, question corpus creation, and SQL annotation.
Evaluation Metrics
The paper introduces two evaluation metrics: Execution Accuracy (EX) and Valid Efficiency Score (VES). Execution Accuracy measures the correctness of SQL results, while VES evaluates the efficiency of SQL execution, incorporating not just correctness but also the speed of query performance.
Experimental Analysis
Bird provides an extensive evaluation of both FT-based and ICL-based models, with GPT-4 achieving top performance but still lagging behind the human baseline. This demonstrates the complex nature of Bird and the need for robust text-to-SQL models which can efficiently handle large-scale database values.
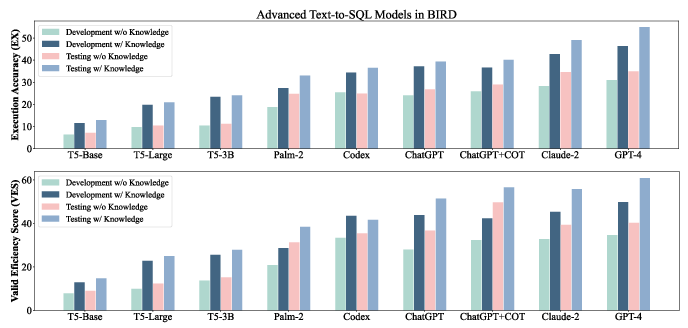
Figure 3: A bar chart provides a visual comparison of advanced model performances on BIRD.
SQL Efficiency and Knowledge Grounding
The paper analyzes strategies to improve SQL efficiency, emphasizing two-stage optimization and opportunities to leverage "chat with database" capabilities to fine-tune SQL generation. Additionally, it quantifies the impact of external knowledge sentences, demonstrating significant performance gains with their integration.

Figure 4: Solutions to improve SQL efficiency, including SQL rewriting and adding indexes.
Implications and Future Directions
Bird facilitates a connection between academic research and industry applications, encouraging the development of models capable of accurately and efficiently generating SQL from complex natural language instructions in realistic datasets. Future endeavors could explore new methodologies for knowledge grounding and further optimize models for real-world performance.
Conclusion
Bird offers a comprehensive challenge to the text-to-SQL community by focusing on large database values, external knowledge grounding, and SQL efficiency. The benchmark highlights the existing gaps in current models and aims to drive further research into creating more robust, efficient, and context-aware text-to-SQL solutions.

