- The paper provides a comprehensive survey of LLM-based text-to-SQL systems, detailing their evolution from rule-based methods to advanced LLM architectures.
- It reviews deep learning and pre-trained model advancements that enhance SQL generation accuracy and facilitate intuitive data access.
- Future directions focus on improving scalability, refining contextual understanding, and addressing data privacy and ethical challenges in real-world applications.
From Natural Language to SQL: Review of LLM-based Text-to-SQL Systems
Text-to-SQL systems have become an increasingly essential component in facilitating natural language access to relational databases, especially with the meteoric rise of LLMs. The ability to translate natural language queries into structured SQL commands is becoming vital for organizations relying on SQL for data management tasks. This paper offers a comprehensive survey of the evolution of LLM-based text-to-SQL systems, exploring their architecture, benchmarks, challenges, and future research directions.
Introduction to Text-to-SQL
Text-to-SQL systems bridge the gap between non-technical users and complex SQL queries, enabling the extraction and analysis of structured data through natural language interactions. As databases become more intricate with the proliferation of big data, the challenge of accessing information for users unfamiliar with SQL grows more pronounced. While text-to-SQL parsing allows users to interact with databases intuitively, building reliable systems face challenges such as linguistic ambiguity, complex schema understanding, and cross-domain generalization as depicted in (Figure 1).
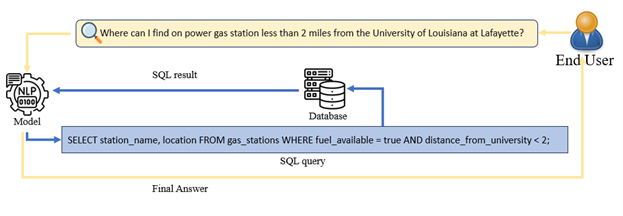
Figure 1: The text-to-SQL system architecture is designed for translating natural language queries into SQL commands, making database interaction accessible without requiring SQL knowledge.
The importance of text-to-SQL systems lies in democratizing data access, streamlining queries, and facilitating decision-making across diverse sectors such as healthcare, finance, and logistics. Nevertheless, overcoming these challenges presents an acute challenge, owing to databases' increasing complexities.
Evolutionary Trajectory of Text-to-SQL Systems
The field of text-to-SQL research has evolved significantly, moving from rule-based systems to the current era dominated by LLMs (Figure 2). This journey reflects the continuous efforts to enhance performance, flexibility, and scalability in addressing increasingly complex database queries.
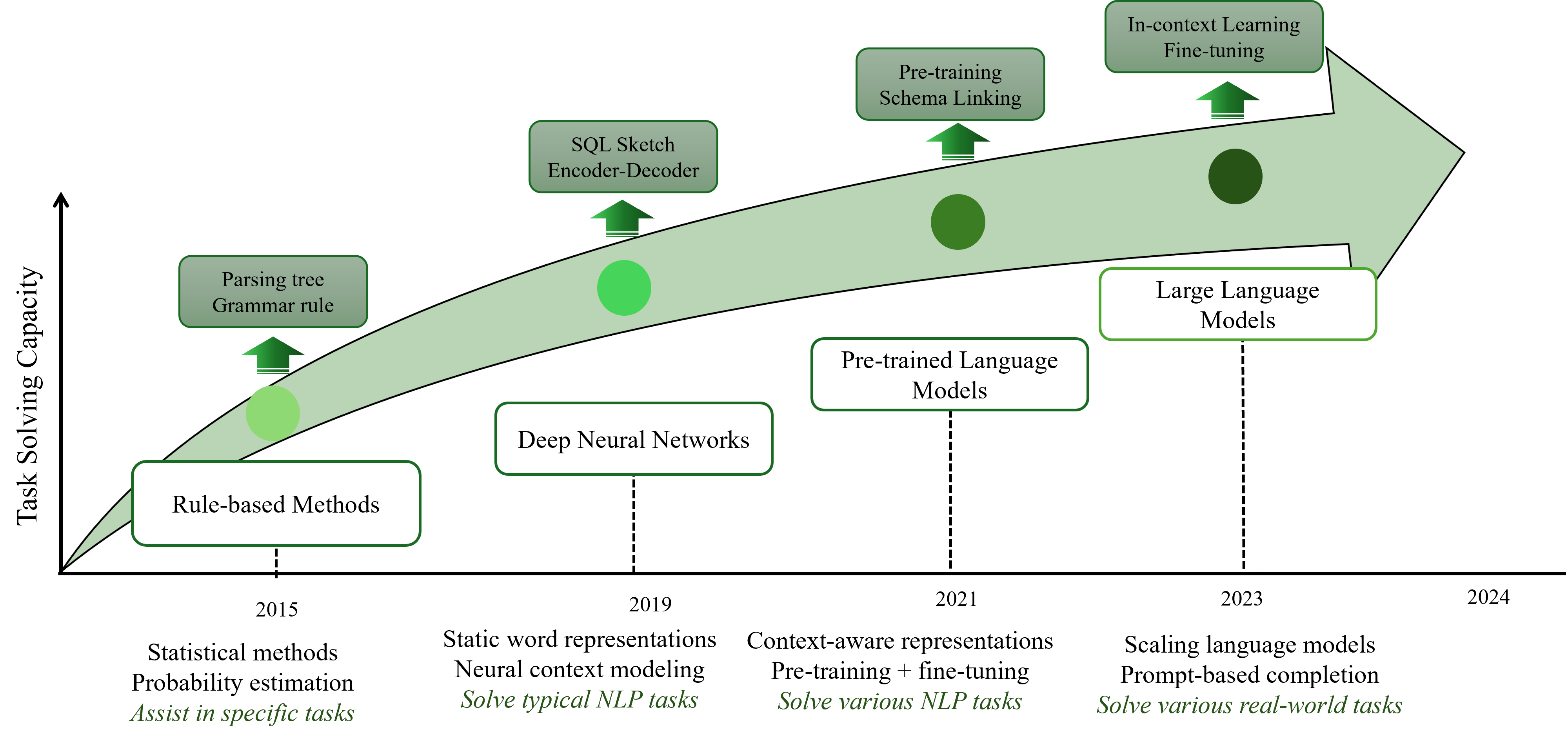
Figure 2: The evolution of text-to-SQL systems illustrated through different implementation approaches and key works.
Rule-Based Approaches: Initial systems relied heavily on manually crafted grammar rules and heuristics but were limited in scalability and flexibility. Despite their simplicity, the difficulty in capturing broad linguistic complexities within the rigid structures of SQL highlighted the need for data-driven methodologies.
Deep Learning Approaches: With the rise of deep learning around 2017, architectures such as Seq2SQL and SQLNet significantly improved the ability to translate natural language into SQL. Building on Seq2Seq models with LSTM and transformers marked a major leap in the performance of text-to-SQL systems, making them more effective across varied cases compared to their rule-based predecessors.
Pre-Trained LLMs (PLMs): BERT and TaBERT represent significant advancements by allowing task-specific fine-tuning using large-scale unsupervised datasets. Despite their successes, PLMs face certain limitations, including challenges with domain adaptation and schema linking, leading to the development of LLM-based approaches.
LLMs: Emerging as a paradigm shift, LLMs such as GPT-4 and Codex, with extensive pre-training and capabilities for zero-shot and few-shot learning, have greatly enhanced text-to-SQL systems. These LLMs demonstrate a substantial improvement in SQL generation accuracy by understanding complex queries without extensive task-specific training.
LLM-based Text-to-SQL System Architecture
LLM-based text-to-SQL systems involve several stages, including natural language understanding, schema linking, SQL generation, and SQL execution (Figure 3).
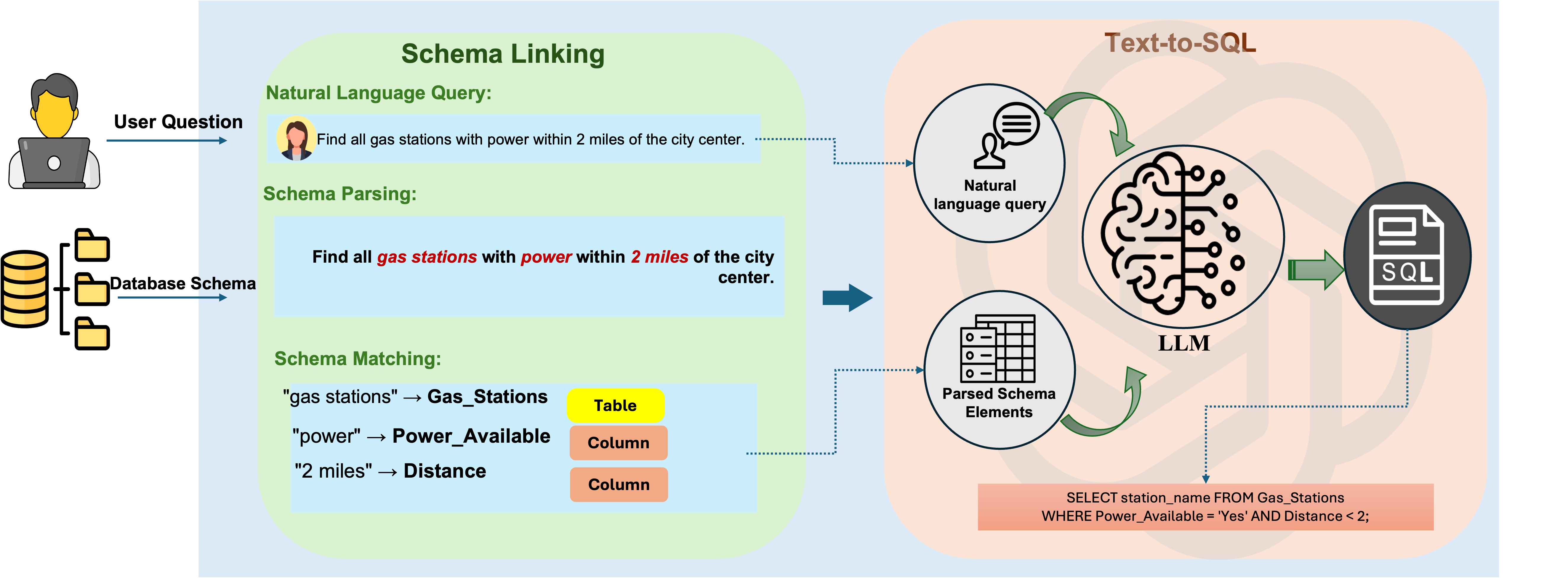
Figure 3: The key stages in LLM-based text-to-SQL process, from user input to SQL execution.
- Natural Language Understanding: LLMs first analyze natural language queries to capture the user's intent and structure the question into understandable components.
- Schema Linking: The parsed query components are linked to relevant database schema elements. This process is crucial for accurately reflecting the user's intent in the structured SQL query.
- SQL Generation: LLMs generate the SQL query based on the mapped schema linkages, followed by its validation and optimization for precise execution.
- SQL Execution and Output: The final query is executed on the target database, and the resulting data is presented to the user. This output can be provided in its raw SQL form or translated back into natural language for readability.
Benchmarks and Evaluation Metrics
Evaluating LLM-based text-to-SQL systems involves various datasets and metrics. These enable researchers to assess the ability of LLMs to generate accurate SQL queries and handle diverse scenarios (Table 1).
Cross-Domain Generalization: Key for LLM-based text-to-SQL evaluation is testing on multiple domains, ensuring generalization of model beyond just domain-specific training data.
Knowledge-Augmented, Context-Dependent, and Robustness Tests: Such datasets assess a model's capability to integrate external knowledge, maintain context across a dialogue, and withstand adversarial perturbations, respectively.
Evaluation Metrics: Models are assessed using both content matching metrics like Component Matching (CM) and Exact Matching (EM) for syntactic accuracy, as well as execution-based metrics like Execution Accuracy (EX) and Valid Efficiency Score (VES)
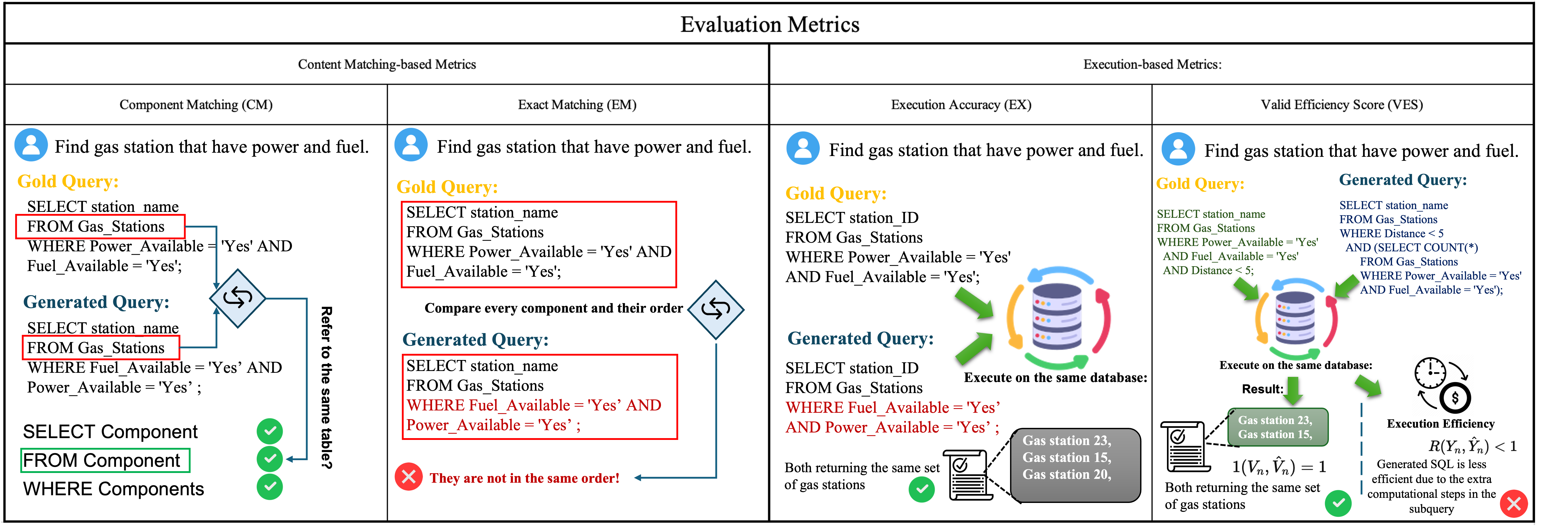
Figure 4: Four main evaluation metrics.
Future Research Directions
The field of LLM-based text-to-SQL systems has made remarkable advances, yet it presents unresolved challenges and opportunities for future development. Further progress in the following areas will help to address current limitations and open new possibilities.
- Enhancing Scalability and Efficiency: Exploration of optimized training and inference techniques, model sparsification, and distributed architectures can reduce computational demands and enable faster processing, crucial for real-world, large-scale, multi-user settings.
- Refined Contextual Understanding: Improvement in model's capacity to accurately grasp multi-step queries involving complex user intents and domain-specific language nuances is essential for applications needing precise and sophisticated query capabilities.
- Expanded Knowledge Graphs: Developing automation and dynamic updating strategies for knowledge graphs, while maintaining model efficiency, is key to contextual consistency, particularly in real-time databases with evolving schema.
- Data Privacy and Ethical Developments: Future systems need to prioritize stricter privacy and ethical protocols, ensuring data security while maintaining transparency and trustworthiness. Systems should operate optimally within privacy constraints, especially in sensitive sectors like healthcare and finance.
- Interactive Human-AI Systems: Evolving towards human-in-the-loop frameworks could create systems that interactively learn from user feedback to improve SQL accuracy. Through user corrections and guidance, models can learn to generate more accurate and context-rich queries.
- Addressing Low-Resource and Multilingual Scenarios: Further research into techniques that allow LLMs to excel in cross-lingual contexts and effectively operate in databases with limited training data is necessary. This expansion is crucial particularly in domains that require targeted, localized querying.
Conclusion
The survey presents a broad overview of LLM-based text-to-SQL systems, charting their evolution from rule-based models to advanced approaches incorporating LLMs and knowledge graphs. While tremendous progress has been made, there is a need for further exploration into areas like efficiency and scalability, ambiguity resolution, data privacy, and ethical challenges. Addressing these challenges will be pivotal in fostering the next generation of text-to-SQL systems, empowering a wider range of users to access and query complex databases effectively and intuitively.