GEM: A Gym for Agentic LLMs
Abstract: The training paradigm for LLMs is moving from static datasets to experience-based learning, where agents acquire skills via interacting with complex environments. To facilitate this transition we introduce GEM (General Experience Maker), an open-source environment simulator designed for the age of LLMs. Analogous to OpenAI-Gym for traditional reinforcement learning (RL), GEM provides a standardized framework for the environment-agent interface, including asynchronous vectorized execution for high throughput, and flexible wrappers for easy extensibility. GEM also features a diverse suite of environments, robust integrated tools, and single-file example scripts demonstrating using GEM with five popular RL training frameworks. Along with this, we also provide a set of baselines across 24 environments using REINFORCE with Return Batch Normalization (ReBN), which -- unlike GRPO -- is compatible with the full RL setting of dense per-turn rewards and offers better credit assignment. We further conduct apple-to-apple benchmarking of PPO, GRPO and REINFORCE in both single- and multi-turn settings using GEM to shed light on the algorithmic designs. Lastly, GEM also functions as a convenient evaluation toolkit besides a training environment. We hope this framework can help accelerate future agentic LLM research.
First 10 authors:


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces GEM, which stands for General Experience Maker. Think of GEM as a “gym” where AI LLMs can practice being agents—solving problems by taking actions, using tools, and learning from trial and error. It provides a standard, easy-to-use setup (like the classic OpenAI Gym) for training and testing LLMs on both simple one-step tasks and complex multi-step tasks that require planning, reasoning, and using tools like a calculator or web search.
What questions does the paper try to answer?
The authors focus on a few simple but important questions:
- How can we build a common, flexible place (a “gym”) where LLM agents can learn from experience across many kinds of tasks?
- Which reinforcement learning (RL) algorithms work best for training LLMs on multi-step tasks, not just single-step ones?
- Does letting LLMs use tools (like Python for math or search for facts) actually help them learn and perform better?
- How do design choices—like how much we reward finishing tasks faster—change what agents learn?
- Can GEM also serve as a fair way to test and compare strong LLMs on challenging tool-using and terminal (computer command-line) tasks?
How did they do it?
What is GEM?
GEM is a framework that:
- Offers many environments (like levels in a game) across math, coding, reasoning puzzles, text-based games, question answering (QA), and a terminal (sandboxed computer) you can control with commands.
- Lets tasks be single-turn (answer once) or multi-turn (go back-and-forth over many steps).
- Supports tools you can plug in—like:
- Python: run code to calculate or test ideas
- Search: look up information on the web
- MCP (Model Context Protocol): a universal “plug” that connects to many external tools (like databases)
In plain terms: GEM is a playground where an AI can try things, get feedback, use helpful tools, and learn.
How do agents learn here?
They use reinforcement learning—learning by doing. Imagine teaching a student by letting them try, telling them what went well or badly (rewards), and encouraging strategies that lead to better results over time.
- “Single-turn” tasks are like answer-the-question-once.
- “Multi-turn” tasks are like playing “Guess the Number,” where you ask questions, get hints, and keep going until you find the right answer.
Which RL algorithms did they explore?
They compare several ways to train the agent:
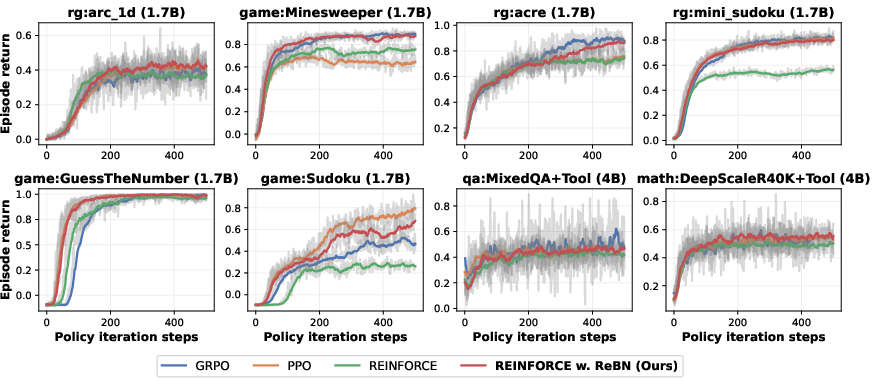
- GRPO: Performs well for single-turn tasks, but struggles with multi-turn tasks because it can’t easily figure out which particular step deserves credit or blame.
- PPO: Strong and stable for multi-turn tasks, but it relies on training an extra “critic” network (like a coach estimating how good each step is), which can be tricky.
- REINFORCE: A classic, simple method that learns directly from returns (how good the outcome was).
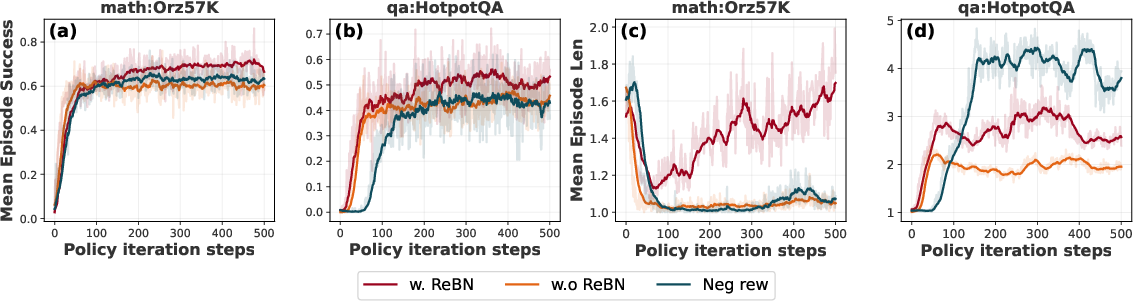
- REINFORCE + ReBN (Return Batch Normalization): Their enhanced version of REINFORCE. It “normalizes” the learning signals across a batch—like adjusting scores so they’re on the same scale—making training more stable and effective for multi-turn tasks with dense rewards.
Speed and scaling
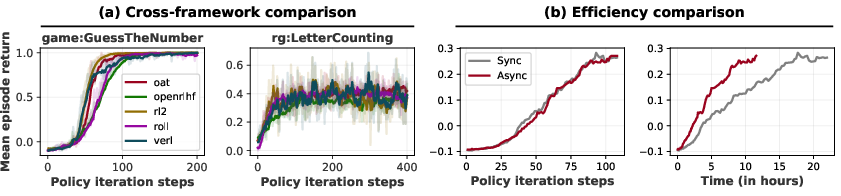
GEM runs many environments in parallel and can automatically restart episodes when they end, so training is efficient. It also integrates smoothly with popular training frameworks (Oat, Verl, OpenRLHF, ROLL, RL2), so researchers can plug GEM into the tools they already use.
What did they find?
Here are the main takeaways, explained simply:
- Algorithm performance:
- GRPO is good for single-turn tasks, but it isn’t a great fit for multi-turn tasks where you need to assign credit to specific steps.
- PPO can be very strong on complex multi-turn tasks, but learning the critic well is hard.
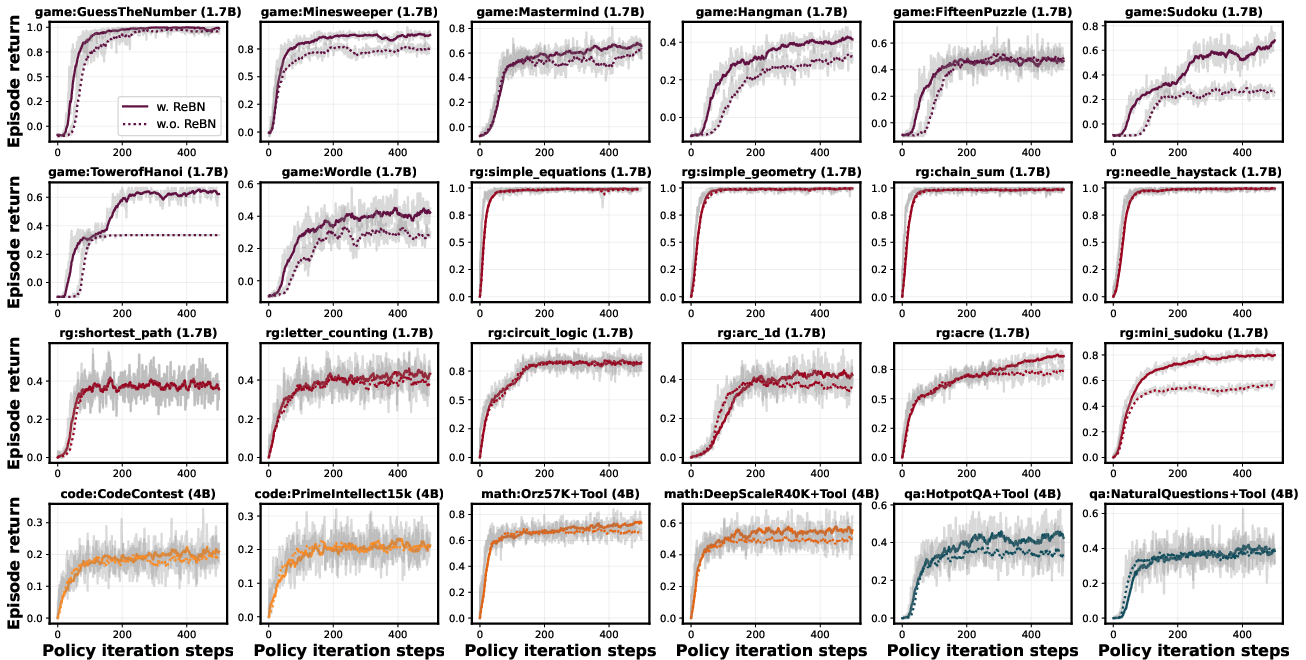
- REINFORCE + ReBN consistently improves over plain REINFORCE and often matches or beats PPO and GRPO—even without extra heavy components—making it a strong, simple baseline for multi-turn learning.
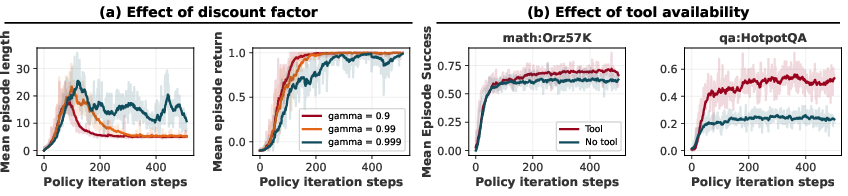
- Finishing faster matters (the “discount factor” γ):
- The discount factor γ is like saying, “We prefer reward sooner rather than later.”
- With γ < 1, agents are nudged to solve problems in fewer steps. In the “Guess the Number” game, this pushes the agent toward an efficient strategy (binary search), reducing the number of guesses to near optimal.
- GRPO can’t easily use this efficiency incentive, which limits it for multi-turn problems.
- Using tools helps:
- Giving the agent Python for math boosts results across multiple math benchmarks, especially after RL training.
- Allowing web search for QA massively improves accuracy, and combining multiple QA datasets for training helps even more.
- Generalization:
- Training on one environment (like easy Sudoku) can improve performance on other reasoning tasks, showing that skills can transfer.
- Unified evaluation:
- GEM doubles as a testing toolkit. The authors tested advanced LLMs (like GPT-5, Gemini 2.5 Pro, Claude Sonnet 4) on:
- Database tasks via MCP: GPT-5 had the best success and needed fewer steps.
- Terminal tasks (using a sandboxed Unix-like environment): GPT-5 again had the highest success rate, followed by Claude and Gemini.
Why does this matter?
- A shared, flexible “gym” for agentic LLMs means researchers can build and compare ideas fairly and quickly. This accelerates progress.
- Moving beyond single-turn tasks is essential for real-world AI agents that plan, revise, and use tools over many steps.
- Simple, robust training methods like REINFORCE + ReBN help make multi-turn RL more practical—without complicated extra components.
- Tool use (Python and Search) makes agents genuinely more capable, and GEM shows how to train and measure that improvement.
- The discount factor design shows that smarter training settings lead to smarter behaviors (like solving faster and more efficiently).
- Having the same platform for training and evaluation (including MCP and terminal tasks) lets people test agents in realistic settings with consistent rules.
In short, GEM makes it easier to build, train, and fairly evaluate LLM agents that act, plan, and use tools—moving us closer to AI systems that can handle complex, real-world tasks.
Knowledge Gaps
Below is a single, concise list of knowledge gaps, limitations, and open questions the paper leaves unresolved. Each item is concrete and actionable for future work.
- Formal theory for Return Batch Normalization (ReBN): convergence guarantees, bias/variance trade-offs, invariance properties under reward scaling, and equivalence or differences to advantage normalization across batch sizes and heterogeneous tasks.
- Systematic ablations of ReBN: sensitivity to batch size, normalization window, reward scaling/clipping, per-turn vs per-trajectory normalization, and interactions with entropy regularization and learning rate.
- Diagnosing and remedying PPO failures: rigorous analysis of why turn-level PPO underperforms (e.g., in Minesweeper), including critic architecture choices, bootstrapping strategies, value/advantage normalization, and temporal-difference target construction for LLM policies.
- Multi-turn GRPO alternatives: quantitative comparison of sample-complexity for tree sampling; evaluation of approximations (e.g., VinePPO, importance sampling, partial resampling per turn), and conditions where GRPO-like methods remain viable.
- Discount factor selection beyond a single game: task- and domain-wide studies of γ’s effect on efficiency, exploration, and convergence; methods to schedule or learn γ; guidance for tasks with unknown or variable horizon lengths.
- Observation wrapper design: empirical and theoretical study of how different observation encodings (last output vs full history vs action+state summaries) affect learning, context-length constraints, and memory management for very long dialogues.
- Scaling to ultra-long horizons (>100 turns): experiments and instrumentation for memory/context truncation, summarization policies, partial observability, and credit assignment at extreme lengths.
- Tool integration policies: handling determinism, latency, cost, error recovery, timeouts, and retries; explicit reward shaping for tool calls (e.g., penalizing unnecessary tool use); standardized logging of tool interactions for reproducibility.
- External search reproducibility: the search engine(s) used, version pinning, caching protocols, rate-limit handling, and offline corpora to ensure repeatable results across runs and labs.
- Math grading standardization: cross-code validation of graders, robust answer extraction, support for multiple solution formats, and release of a canonical GEM grader to prevent evaluator drift.
- QA evaluation breadth: beyond accuracy, measure faithfulness, citation quality, multi-hop reasoning traceability, tool-use correctness, and failure taxonomy; introduce verifiable QA reward functions where feasible.
- Terminal and MCP evaluations are narrow: expand beyond small Postgres and terminal subsets; include diverse MCP servers (APIs, filesystems, IDEs), more complex tasks, and agent scaffolding comparisons (simple loop vs agent frameworks).
- Safety and security in tool execution: sandboxing guarantees for Python and terminal tools, prevention of environment escape or destructive actions, resource quotas, and audits for reward hacking through tools.
- Multi-agent support is underexplored: provide benchmarks, protocols (cooperative/competitive), inter-agent communication interfaces, and credit assignment schemes; analyze emergent coordination and self-play stability.
- Vision-language tasks lack detail: publish full VLM environment specs, grading pipeline for image-linked math, and tool integration (OCR, visual grounding) with reproducible datasets and metrics.
- Framework parity and reproducibility: control for generation engine, sampling parameters, optimizer, and compute budget across Oat, Verl, OpenRLHF, ROLL, and RL2; report throughput, memory footprint, and cost per step/episode.
- Asynchronous vectorization at scale: details on failure handling, backpressure, scheduling fairness across tools, cross-node rollout orchestration, and the impact of rollout lag on on-policy updates.
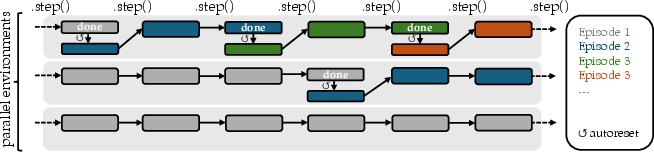
- Autoreset edge cases: behavior with partial rollouts, mixed-task batches, curriculum changes, and value bootstrapping boundaries; tests to ensure no leakage across episodes in all frameworks.
- Reward hacking and verification: adversarial tests to detect shortcutting in language games, robust reward functions, and countermeasures (e.g., perturbation, hidden checks) to ensure genuine task completion.
- Cost-aware RL objectives: incorporate tool latency, API costs, and token budgets directly into rewards; study Pareto frontiers between accuracy, efficiency, and cost.
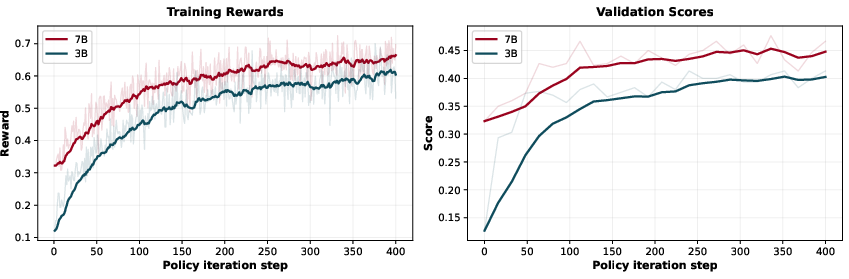
- Model family and scale generalization: replicate baselines across diverse LLMs (open/closed, varying sizes), derive scaling laws for sample efficiency and final performance, and quantify pretraining interactions.
- Dataset, Docker, and tool version pinning: publish exact environment images, tool endpoints, seeds, and licenses; provide offline mirrors for datasets/tools to ensure long-term reproducibility.
- Hyperparameter robustness: multi-seed and multi-task sweeps for learning rate, batch size, entropy, clipping, KL constraints, and update frequency; report variance and confidence intervals.
- Off-policy and replay-based methods: investigate experience replay, importance sampling, and off-policy actor-critic for LLM RL to improve sample-efficiency under expensive rollouts.
- Normalization across mixed-task training: study per-env vs global return normalization, distribution shift when mixing tasks, and strategies to stabilize learning in multi-env curricula.
- Evaluation metrics beyond mean return: standardized measures for sample efficiency (return vs steps), stability (variance across seeds), generalization (zero-shot to held-out envs), and robustness (tool failures/noise).
- MCP ecosystem stress testing: rate-limit resilience, server heterogeneity, schema drift, network failures, and caching strategies; define benchmarks for realistic production tooling conditions.
- Reward design guidelines for dense multi-turn tasks: publish templates and ablations for informative yet non-deceptive shaping; quantify the impact of shaping components on exploration and convergence.
- Preference and verifiable reward integration: combine verifiable signals (math/logic) with preference models for tasks lacking ground truth; study alignment-accuracy trade-offs in multi-turn settings.
- Time preference modeling: link γ to user-centric time costs and deadlines; explore learnable or context-conditioned discounting for agentic LLMs.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s LLMs and infrastructure, leveraging GEM’s standardized environments, tool integrations (Python, Search, MCP), async vectorization, Dockerized terminal sandbox, and the REINFORCE+ReBN baseline.
Industry
- Internal agent evaluation and benchmarking harness
- Use GEM’s unified interface to run vendor bake-offs (e.g., GPT-5, Claude, Gemini) on tool-use reliability (MCPMark subset) and shell proficiency (Terminal-Bench subset).
- Outcomes: procurement scorecards, reliability dashboards, regression tests in CI.
- Assumptions: access to target APIs/models; consistent graders; secure credentials for tool endpoints.
- RL training of practical agent workflows (software/devops/data)
- Train multi-turn agents to: execute runbooks in a Dockerized terminal; generate and validate code; answer knowledge queries with search; write SQL via MCP (Postgres).
- Outcomes: “DevOps copilot in a sandbox,” “SQL copilot with safe execution,” “code-repair loop with unit tests.”
- Assumptions: curated tasks and reward functions; sandboxing/isolation (Docker/network policies); logging/rollback for safety.
- Efficient RL training pipelines for agentic LLMs
- Plug GEM into Oat, Verl, OpenRLHF, ROLL, or RL2 single-file scripts; use async vectorized environments with autoreset; adopt REINFORCE+ReBN as a strong, critic-free baseline.
- Outcomes: reproducible multi-turn RL jobs, improved throughput, simpler credit assignment vs. GRPO in multi-turn.
- Assumptions: GPU capacity; inference engines (e.g., vLLM/DeepSpeed); correct reward shaping for your domain.
- Search-augmented QA and Python-augmented math copilots
- Stand up agents that call Search in multi-hop QA and Python for math/calc; use GEM results to justify RL fine-tuning with tools to lift accuracy.
- Outcomes: internal knowledge assistant, quant back-office calculator, customer support answerer with citations.
- Assumptions: stable search endpoint; verifiable graders; data governance for knowledge sources.
- Safety and red-teaming for tool use
- Use terminal/DB tasks to stress-test agents’ guardrails, escalation behavior, and step-efficiency (tune γ<1 to penalize long, risky trajectories).
- Outcomes: “AgentOps” safety harness, risk sign-offs for production deployment.
- Assumptions: policy constraints; secure secrets handling; audit logging.
Academia
- Reproducible benchmark suite for multi-turn LLM RL
- Apples-to-apples comparisons of GRPO, PPO, REINFORCE, and ReBN with unified tasks and rewards; controlled γ experiments for efficiency.
- Outcomes: fair algorithm papers; robust ablations on discounting, dense rewards, tools.
- Assumptions: adherence to GEM versions/datasets; shared configs for comparability.
- Teaching lab kit for LLMs-as-agents
- Course assignments on wrappers, tool use, environment design; Dockerized terminals for safe system tasks; MCP examples for database tools.
- Outcomes: hands-on curricula for agentic RL; student projects adding new tasks/tools.
- Assumptions: student compute; institutional policies for sandboxing and network access.
- Rapid prototyping of new environments and tools
- Extend GEM with domain datasets, MCP servers, or custom games; use observation/action wrappers to study memory and context strategies.
- Outcomes: new benchmarks for planning, credit assignment, or verifiability.
- Assumptions: dataset licenses; grader availability; minimal boilerplate via GEM base classes.
Policy and Government
- Standardized evaluation for procurement and compliance
- Adopt GEM tasks (Terminal, MCP DB) as acceptance tests for tool governance, auditability, and step-efficiency.
- Outcomes: procurement checklists; certification-style test suites for agentic LLMs.
- Assumptions: consensus on metrics; controlled evaluation compute; red-team scenarios.
- Safety sandboxes for operational readiness
- Simulate sensitive workflows (e.g., shell, DB) in isolation; evaluate adherence to rules and safe fallback strategies.
- Outcomes: deployment gating; incident readiness assessments.
- Assumptions: realistic but sanitized environments; policy-aligned reward design.
Daily Life and Individual Developers
- Personal research and math assistants with tools
- Local or cloud agents that browse, cite sources, and compute with Python for study, budgeting, or data analysis.
- Outcomes: reproducible “study agent” notebooks; small automation scripts trained in GEM tasks.
- Assumptions: API access to LLMs/search; modest compute; user consent for web access.
- Open-source contributions and plugin ecosystem
- Add MCP-compatible tools (calendar, email, spreadsheets) or new GEM tasks; share wrappers for memory, logging, or safety.
- Outcomes: community tool registry; reusable evaluation recipes.
- Assumptions: MCP compliance; basic Python/Docker skills.
Long-Term Applications
These opportunities are plausible extensions that need further research, scaling, integration, or governance maturation.
Industry
- Autonomous software engineering and SRE copilots
- Multi-turn agents that plan, code, test, and deploy; close the loop with terminals, issue trackers, and CI/CD; optimize steps with γ<1 and dense rewards.
- Products: “End-to-end Ticket Remediator,” “Self-healing Services Copilot.”
- Dependencies: robust safety layers, change management workflows, high-coverage test suites, provenance tracking, on-call oversight.
- Enterprise data operations agents via MCP
- Schema discovery, safe migrations, lineage-aware transformations; compliance-aware SQL with approvals.
- Products: “DataOps Agent,” “Governed Analytics Copilot.”
- Dependencies: enterprise IAM, PII compliance, RBAC in tools, offline sandboxes, signed action ledgers.
- Continuous AgentOps platform
- Always-on GEM-based eval farms that gate rollouts, scan regressions, and enforce SLAs on step-efficiency, success rate, and tool safety.
- Products: “AgentOps CI/CD,” “RL-in-prod Observability.”
- Dependencies: scalable infra; standardized SLIs/SLOs; vendor-neutral APIs.
Academia
- Scalable “experience-first” agent training
- Large-scale multi-environment RL curricula with tool ecosystems; curriculum learning; offline-to-online training.
- Outcomes: foundation agent models optimized for planning and tool use.
- Dependencies: substantial compute; replay buffers and safety filters; standardized verifiable rewards.
- Advances in credit assignment and value estimation
- Beyond ReBN: stable multi-turn actor-critic, partial observability handling, tree-structured sampling without combinatorial cost.
- Outcomes: algorithms that outperform PPO/REINFORCE in long horizons.
- Dependencies: new estimators, theory, and robust open benchmarks.
- Generalization and transfer across tool ecosystems
- Agents that zero/few-shot adapt to new MCP tools; meta-RL on wrappers and observation formats.
- Outcomes: tool-agnostic agent capabilities.
- Dependencies: diverse tool distributions; standardized schemas; representation learning advances.
Policy and Government
- Regulatory benchmarks and certifications for agentic LLMs
- Sector-specific GEM suites for finance (trading ops, KYC tooling), healthcare (EHR tool use), and public sector (records systems).
- Outcomes: certification pathways; insurer-backed risk ratings.
- Dependencies: inter-agency and industry consensus; red-team datasets; auditable logs.
- Safety-by-design mandate for tool-using agents
- Standard guardrails (rate limits, approval steps, rollback plans) validated in GEM terminal/DB environments before real-world integration.
- Outcomes: policy frameworks and reference implementations.
- Dependencies: legal guidance; uptake by major vendors; continuous audit infrastructure.
Daily Life and Individual Developers
- Personal “computer-use” agents
- Agents that safely operate OS tools, terminals, office apps, and personal knowledge bases via MCP-like protocols.
- Products: desktop copilots that execute tasks with confirmations and logs.
- Dependencies: local sandboxing; privacy-preserving data access; user trust and UX design.
- Education-at-scale tutors with reasoning and tools
- Tutors that can browse, compute, and explain with verifiable steps; adapt curricula via RL in GEM math/reasoning environments.
- Products: accredited digital tutors with progress guarantees.
- Dependencies: content safety/alignment; dependable graders; school/parental controls.
Cross-cutting assumptions and dependencies
- Technical: reliable LLM inference (latency/throughput), verifiable reward functions, robust graders (math/QA), safe Docker/network isolation, and MCP maturity/security.
- Data and governance: dataset licensing, PII handling, audit logs, rollback, and access controls for tools.
- Safety: strong guardrails for terminal/DB actions, human-in-the-loop approvals for high-impact steps, and comprehensive observability.
- Economics: training/inference cost management; throughput benefits from asynchronous vectorization and autoreset to keep RL feasible at scale.
Glossary
- Advantage actor-critic (A2C): A policy-gradient method that uses an estimated advantage computed from a learned value function to reduce variance. "We can compute GAE for the advantage actor-critic (A2C) objective:"
- Advantage normalization: Normalizing advantage estimates across a batch or group to stabilize and improve policy-gradient learning. "a useful technique similar to advantage normalization that brings consistent improvements"
- Agentic LLMs: LLMs designed and trained to act autonomously as agents in interactive, multi-step environments. "We hope this framework can help accelerate future agentic LLM research"
- Asynchronous vectorized execution: Running many environment instances in parallel with non-blocking tool calls to increase throughput. "including asynchronous vectorized execution for high throughput"
- Autoreset: Automatic resetting of an environment after termination to simplify continuous data collection in vectorized settings. "Autoresetting resets the environment automatically after termination"
- Chain-of-thought reasoning: Generating intermediate reasoning steps in natural language to solve complex problems. "Solve math problems with chain-of-thought reasoning."
- Contextual bandits: A one-step RL setting where the agent chooses an action based on context and receives immediate reward, without state transitions. "and the RL problem essentially degenerates to contextual bandits"
- Credit assignment: Determining which actions or decisions in a trajectory are responsible for observed rewards. "offers better credit assignment"
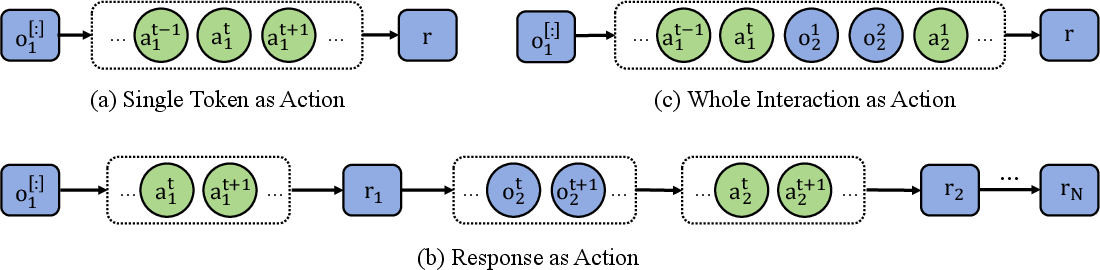
- Dense per-turn rewards: Reward signals provided at each turn/step of a multi-turn episode rather than only at the end. "including turn-level dense rewards and arbitrary discount factors."
- Discount factor (γ): A parameter that down-weights future rewards relative to immediate ones to encourage efficient solutions. "We also provide case studies on the impact of the discount factor on multi-turn learning"
- EOS: The end-of-sequence token that marks the completion of a model’s response. "treat a whole response (a sequence of tokens until an EOS) as a single action"
- Generalized Advantage Estimation (GAE): A technique for estimating advantages that trades bias and variance via temporal smoothing. "We can compute GAE for the advantage actor-critic (A2C) objective:"
- GRPO: A group-based policy-gradient method that normalizes trajectory-level rewards within sampled groups. "Unlike GRPO and its variants, REINFORCE with ReBN is fully compatible with the multi-turn RL setting"
- Model Context Protocol (MCP): An open protocol standardizing communication between LLMs and external tools or data sources. "MCP: General tool calling to any external servers that conform to the model context protocol."
- On-policy: Learning from data collected by the current policy rather than a replay buffer of past policies. "We start from the foundational on-policy policy-gradient method REINFORCE"
- Policy gradient: A class of methods that directly optimize the parameters of a stochastic policy using gradient ascent on expected return. "policy-gradient method REINFORCE"
- Proximal Policy Optimization (PPO): A policy-gradient algorithm that uses clipped updates and a learned critic to improve stability and sample efficiency. "PPO in this work generally refers to turn-level PPO instead of token-level PPO commonly seen in single-turn dialogue scenarios"
- Proximal updates: Constraining parameter changes during optimization to remain within a trust region or via clipping for stability. "we can also utilize proximal updates to improve sample efficiency."
- REINFORCE: A foundational on-policy policy-gradient algorithm that scales log-likelihoods of actions by returns. "We start from the foundational on-policy policy-gradient method REINFORCE"
- Return Batch Normalization (ReBN): Normalizing per-transition returns across the batch to stabilize gradients without learning a critic. "which incorporates Return Batch Normalization (ReBN), a useful technique similar to advantage normalization that brings consistent improvements"
- Sample-based advantage estimation: Computing advantages from multiple sampled completions of the same state to reduce variance. "sample-based advantage estimation methods such as GRPO can be applied efficiently"
- Sparse outcome reward: Reward provided only at episode completion or at infrequent events, with no per-step feedback. "Successful applications of RL in this formulation tend to use sparse outcome reward with discount factor "
- Tool-integrated environments: Task settings where agents can call external tools (e.g., Python, search) within multi-turn interactions. "tool-integrated multi-turn environments"
- Trajectory-level rewards: Rewards assigned to entire trajectories rather than individual steps, limiting fine-grained credit assignment. "limited to single trajectory-level rewards, losing fine-grained per-turn credit assignment."
- Vectorized environments: Multiple environment instances batched together to parallelize interaction and data collection. "vectorized environments via asynchronous tool calls"
- vLLM: A high-throughput inference engine for serving LLMs efficiently. "such as vLLM for response generation"
- Value bootstrapping: Using estimates from the value function of subsequent states to compute targets across episode boundaries. "prevent value bootstrapping across episode boundaries"
- Value function (critic): A learned estimator of expected return from a state (or state-action) that guides policy updates. "learn a value function to estimate the return , known as critic"
- Wrappers: Modular components that alter observations, actions, or add tools to environments without changing core logic. "GEM uses wrappers for easy extensibility."
Collections
Sign up for free to add this paper to one or more collections.

