- The paper presents the MC-DML algorithm, which integrates LLMs with Monte Carlo planning to enhance exploration in text-based game environments.
- It employs dual memory mechanisms—in-trial and cross-trial—to prioritize actions based on current trajectories and historical experiences.
- Empirical results show MC-DML outperforms traditional MCTS and RL methods on the Jericho benchmark, notably in games like Zork1 and Deephome.
Monte Carlo Planning with LLM for Text-Based Game Agents
Introduction
The paper presents the Monte Carlo planning with Dynamic Memory-guided LLM (MC-DML) algorithm, designed to tackle the challenges of text-based games on the Jericho benchmark. These games demand language understanding and reasoning capabilities due to their dynamic state spaces and sparse rewards. Traditional approaches, such as Monte Carlo Tree Search (MCTS) and reinforcement learning (RL), face limitations in this context due to extensive iterations and insufficient language capabilities. MC-DML aims to merge the language prowess of LLMs with the exploratory strengths of tree search algorithms, introducing in-trial and cross-trial memory mechanisms that empower the LLMs to learn from past experiences.
Methodology
MC-DML integrates the capabilities of LLMs into traditional MCTS by employing LLMs as prior policies. Throughout the expanded phases of selection, expansion, simulation, and backpropagation, the LLM assigns non-uniform search priorities to candidate actions based on its in-trial memory (the agent's current trajectory) and cross-trial memory (historical experiences from previous failures). This dual-memory setup allows the LLM to dynamically adapt its action evaluations during the simulation.
The MC-DML algorithm operates by aligning more closely with human reasoning, where in-trial memory reflects recent experiences and cross-trial memory leverages insights learned from prior mistakes. This design enables the LLM to refine its action-value estimates continually, aiming to improve efficiency in sparse or complex game environments.
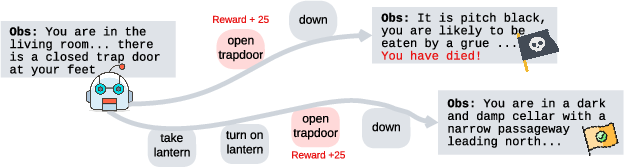
Figure 1: An example bottleneck state from the game Zork1.
Results
Empirical results from experiments conducted on text-based games in the Jericho benchmark show that MC-DML substantially enhances initial planning performance compared to other methods that require multiple iterations for policy optimization. Its innovative memory mechanism significantly outperforms contemporary RL-based and MCTS-based approaches, performing particularly well in complex environments like Zork1 and Deephome.
Comparison with Prior Algorithms
MC-DML was compared against multiple baselines. Traditional MCTS methods like PUCT and approaches such as MC-LAVE-RL, which incorporate value sharing among actions, were outperformed by MC-DML across 8 out of 9 games. By prioritizing exploration and leveraging memory mechanisms, MC-DML addresses the shortcomings of static policy learning in MCTS, providing a more robust solution for language-driven decision-making challenges.
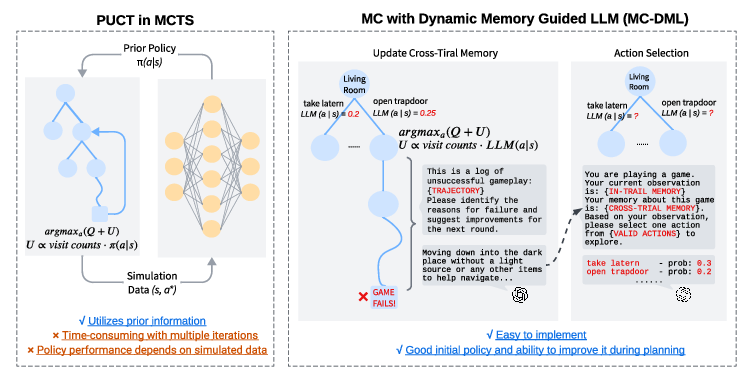
Figure 2: A comparison of the PUCT and MC-DML algorithms. PUCT trains its policy through imitation learning from self-play data. In contrast, MC-DML uses a LLM as the initial policy. During planning, the LLM learns from past failure trajectories and adjusts the action value estimates. This approach more closely aligns with the human thought process.
Technical Implementation and Challenges
The algorithm was implemented using the gpt-3.5-turbo LLM, meticulously tuned to achieve optimal balance between exploration and exploitation using estimated Q-values and memory-guided adjustments. However, the cross-trial memory relies on curated reflections from failed trajectories, emphasizing the pivotal role of effective feedback mechanisms.
The flexibility of MC-DML to dynamically adjust the state-action evaluations marks an advancement in its ability to mimic human-like strategic depth and planning adaptability. Nevertheless, practical challenges exist, such as managing the LLM's input constraints and ensuring relevance in the stored memory, particularly in games where decisions in early states have significant subsequent ramifications.
Conclusion
MC-DML demonstrates a significant step forward in integrating LLMs into Monte Carlo planning for enhanced action exploration in text-based games. Its dual-memory approach allows for dynamic learning and illuminated strategies that align closely with natural human decision processes. Future work could explore optimizing memory management techniques and expanding to other complex decision-making tasks requiring intricate language understanding combined with strategic planning capabilities.