Bridging Offline and Online Reinforcement Learning for LLMs
Published 26 Jun 2025 in cs.CL | (2506.21495v1)
Abstract: We investigate the effectiveness of reinforcement learning methods for finetuning LLMs when transitioning from offline to semi-online to fully online regimes for both verifiable and non-verifiable tasks. Our experiments cover training on verifiable math as well as non-verifiable instruction following with a set of benchmark evaluations for both. Across these settings, we extensively compare online and semi-online Direct Preference Optimization and Group Reward Policy Optimization objectives, and surprisingly find similar performance and convergence between these variants, which all strongly outperform offline methods. We provide a detailed analysis of the training dynamics and hyperparameter selection strategies to achieve optimal results. Finally, we show that multi-tasking with verifiable and non-verifiable rewards jointly yields improved performance across both task types.
The paper's main contribution is demonstrating that semi-online and online RL methods achieve competitive performance and faster convergence compared to offline approaches.
It employs DPO and GRPO objectives to fine-tune large language models by synchronizing model parameters and optimizing hyperparameters for stability.
Experiments reveal that integrating verifiable tasks (e.g., math problem-solving) with non-verifiable tasks (e.g., instruction following) improves overall performance and generalization.
Bridging Offline and Online Reinforcement Learning for LLMs
This paper explores the efficacy of reinforcement learning techniques for fine-tuning LLMs, focusing on the transition from offline to semi-online to fully online regimes across both verifiable and non-verifiable tasks. The study compares online and semi-online DPO and GRPO objectives, analyzing training dynamics and hyperparameter selection strategies to optimize performance. The paper's key finding is the comparable performance and convergence between semi-online and online variants, which both outperform offline methods, suggesting potential efficiency gains. Additionally, the paper investigates the joint optimization of verifiable tasks with rule-based rewards and non-verifiable tasks with reward models, demonstrating improved overall performance.
LLM Alignment Algorithms
The paper investigates several algorithms for LLM alignment, including GRPO and DPO. GRPO, based on PPO, leverages a group of responses for a given prompt to approximate the relative advantage of each response. The GRPO loss is defined as:
The paper also introduces a semi-online DPO setup, where the generation model parameters are synchronized with the training model parameters periodically. This approach bridges the gap between offline and online training, offering potential computational efficiency.
Experimental Setup
The experimental setup involves comparing offline, semi-online, and online configurations across verifiable and non-verifiable tasks using DPO and GRPO. The verifiable task focuses on mathematical problem-solving using the NuminaMath dataset and the Math-Verify toolkit for evaluation. The non-verifiable task centers on instruction following, employing the WildChat-1M dataset and the Athene-RM-8B reward model for evaluation. The paper also examines combining verifiable and non-verifiable tasks to assess skills generalization.
Results
The paper's main results demonstrate that online and semi-online training regimes significantly outperform offline DPO across both verifiable and non-verifiable tasks (Table 1, Table 2). Specifically, semi-online DPO achieves comparable performance to online DPO and GRPO, suggesting that pure online training may not be necessary. The combined training of verifiable and non-verifiable tasks shows improved performance compared to training on individual tasks, highlighting the benefits of a mixed reward training approach (Table 3).
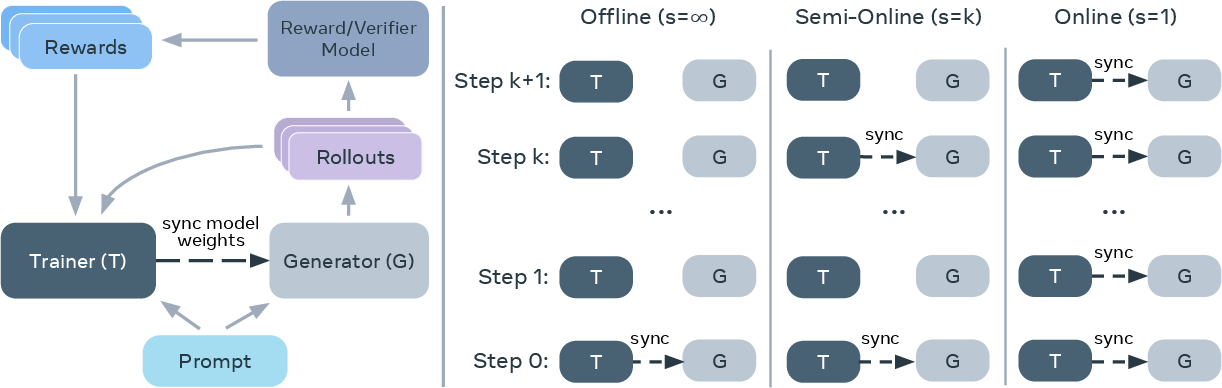
Figure 1: (left): Visualization of a single training step within our training pipeline, which can be used for any training objective such as DPO or GRPO; syncing the weights allows rollout responses to be generated from the most recent model; (right): Progression from offline to online training, showing when model weight synchronizations occur at different train steps; offline training only syncs before training starts, whereas online training syncs at every step.
Additional Experiments and Observations
Further experiments explore response length, entropy collapse, and loss function variations. The paper observes that disabling reference model synchronization can lead to response length collapse and performance degradation, particularly in verifiable tasks (Figure 2). Entropy collapse is also observed in verifiable tasks, except for offline DPO (Figure 3). Experiments with entropy regularization and the addition of an NLL term to the DPO loss do not yield significant benefits. The paper also explores GroupDPO and the combination of GroupDPO and GRPO, finding no substantial performance changes compared to standard DPO.
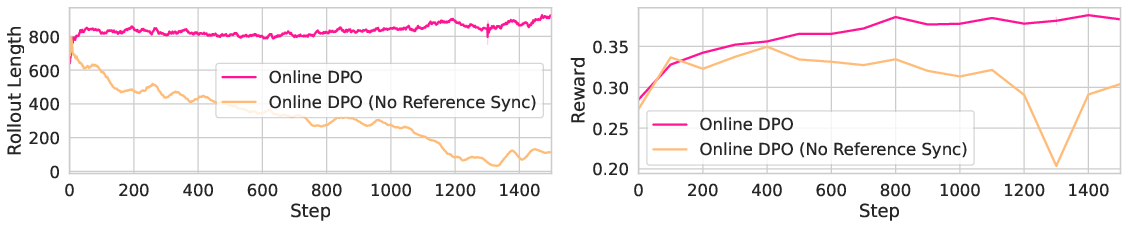
Figure 2: Without syncing the reference model, response lengths of online DPO collapse when trained on verifiable tasks (left); this length collapse is also correlated with lower validation reward (right).
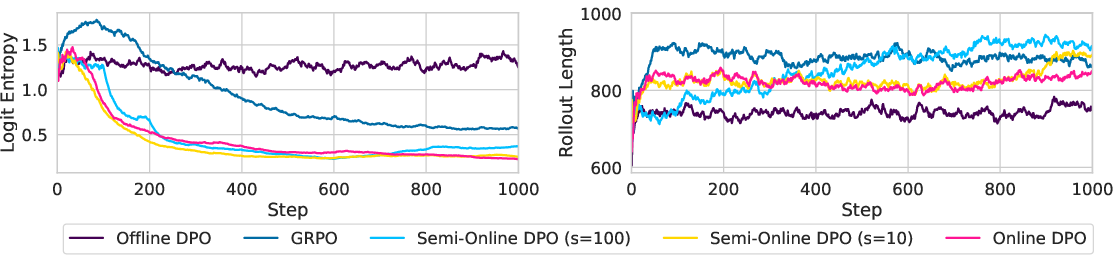
Figure 3: Logit entropy collapse in iterative and online training on verifiable tasks; despite stable average length of rollouts during training (right), the average entropy of the next token distribution (left) decreases significantly during the training in all training regimes except the offline one.
Discussion
The paper discusses hyperparameter selection, noting instabilities in DPO training and the importance of Adam's epsilon value for stability. It also highlights the training efficiency of DPO and the advantages of the semi-online configuration in enabling asynchronous and parallel response annotation.
Conclusion
The study concludes that semi-online and online RL methods outperform offline approaches for LLM finetuning on both verifiable and non-verifiable tasks. Semi-online DPO offers a balance between performance and efficiency, making it viable for agentic applications. The paper also demonstrates the effectiveness of combining verifiable and non-verifiable tasks during training, suggesting avenues for further research in multi-task settings.