- The paper introduces DARS to correct depth bias by reallocating rollouts, significantly improving Pass@K performance.
- It demonstrates that large-batch training boosts Pass@1 by enhancing gradient estimation and sustaining exploration.
- DARS-B synergizes adaptive depth and breadth methods, achieving simultaneous improvements in key reasoning metrics.
Depth-Breadth Synergy in RLVR: Adaptive Exploration for Enhanced LLM Reasoning
Introduction
This paper addresses a critical limitation in Reinforcement Learning with Verifiable Reward (RLVR) for LLMs: the insufficient exploitation of two orthogonal training dimensions—depth (the hardest problems a model can solve) and breadth (the number of instances processed per iteration). The authors identify a systematic bias in the widely used Grouped Relative Policy Optimization (GRPO) algorithm, which underweights high-difficulty samples, thereby capping Pass@K performance. To address this, they introduce Difficulty Adaptive Rollout Sampling (DARS) and its breadth-augmented variant DARS-B, demonstrating that adaptive exploration along both depth and breadth axes is essential for maximizing LLM reasoning capabilities.
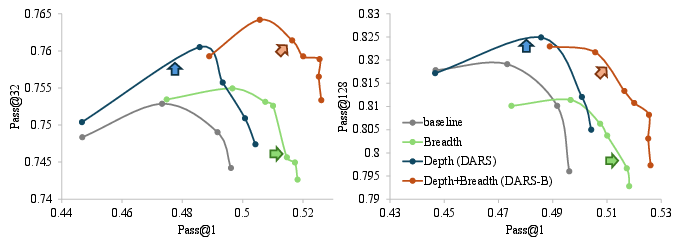
Figure 1: DARS significantly improves Pass@K and is complementary to breadth scaling for Pass@1.
Analysis of Depth and Breadth in RLVR
Depth: Hardest Problem Sampled
The depth dimension is defined as the hardest problem that can be correctly answered during RLVR training. The authors show that simply increasing rollout size (i.e., the number of sampled responses per question) does not consistently improve Pass@K and can even degrade it for smaller models. This is attributed to a cumulative advantage bias in GRPO and its variants, which allocate most learning signal to medium-difficulty problems, neglecting the high-difficulty instances that are crucial for expanding reasoning capacity.
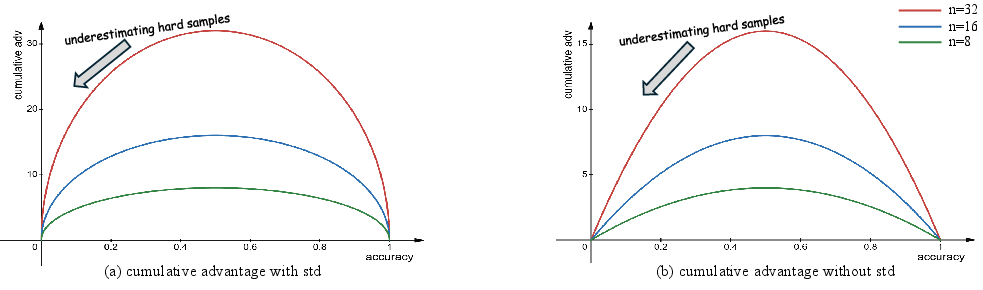
Figure 2: Cumulative advantage underestimates high-difficulty problems, regardless of calculation method.
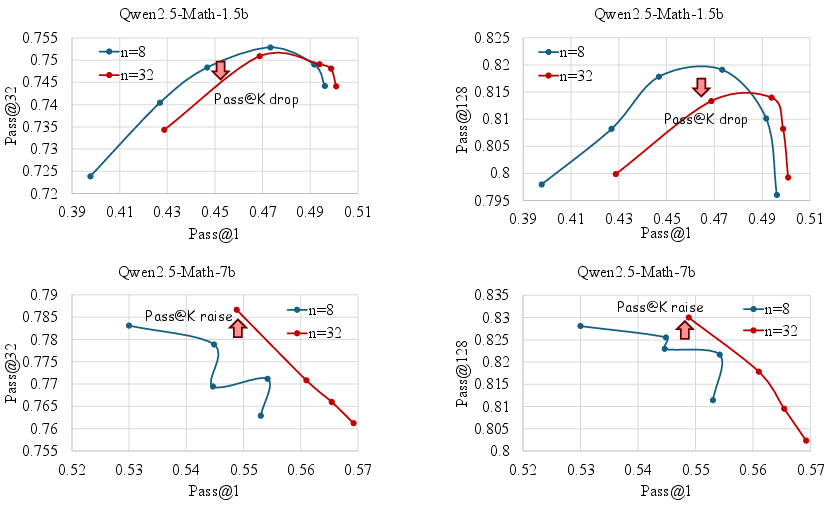
Figure 3: Increasing rollout size benefits Pass@1 but not necessarily Pass@K, especially for smaller models.
Breadth: Iteration Instance Quantity
Breadth is defined as the number of instances (questions) processed per RLVR iteration. The authors demonstrate that increasing batch size (breadth) leads to significant improvements in Pass@1, attributed to more accurate gradient estimation and reduced noise. However, this can harm Pass@K for smaller models, indicating a trade-off.
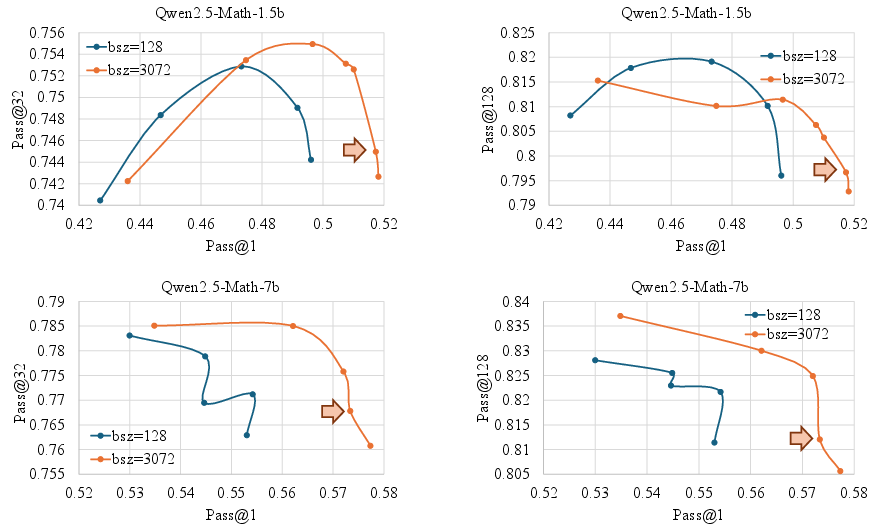
Figure 4: Larger batch size improves Pass@1 but can reduce Pass@K for smaller models.
Breadth also sustains higher token-level entropy during training, acting as an implicit regularizer that delays premature convergence and maintains exploration.
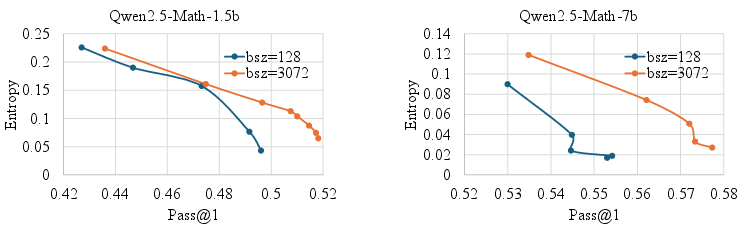
Figure 5: Breadth scaling sustains higher token entropy, supporting exploration.
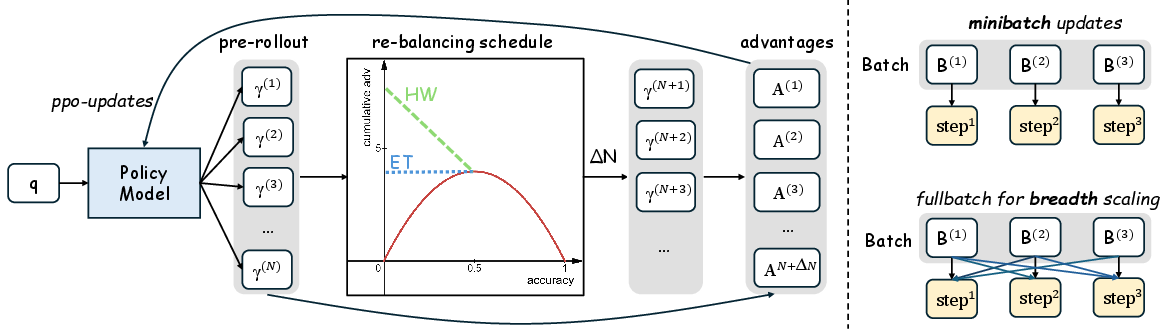
Methodology: Difficulty Adaptive Rollout Sampling (DARS)
DARS is a two-phase adaptive sampling strategy designed to correct the depth bias in GRPO:
- Pre-Rollout Difficulty Estimation: For each question, a lightweight rollout estimates empirical accuracy, which is used to assign a difficulty score.
- Multi-Stage Rollout Re-Balancing: Additional rollouts are allocated to harder questions (lower accuracy), rebalancing the cumulative advantage to upweight high-difficulty samples.
Two rebalancing schedules are proposed:
Depth-Breadth Synergy: DARS-B
To unify the benefits of depth and breadth, the authors propose DARS-B, which combines DARS with large-batch (breadth) training. This is implemented by replacing PPO mini-batch updates with full-batch gradient descent across multiple epochs, ensuring compatibility with DARS's dynamic allocation and maximizing effective training breadth.
Key advantages:
- Eliminates mini-batch gradient noise.
- Sustains token-level exploration (entropy regularization).
- Achieves simultaneous gains in Pass@1 (breadth) and Pass@K (depth).
Experimental Results
Experiments are conducted on Qwen2.5-Math-1.5b and 7b models using five mathematical reasoning benchmarks. The main findings are:
- Breadth scaling (large batch size) consistently improves Pass@1 across all model scales and tasks.
- DARS delivers significant Pass@K gains by reallocating compute to hard problems, with minimal extra inference cost.
- DARS-B achieves the highest Pass@1 and matches or exceeds the best Pass@K, confirming the orthogonality and synergy of depth and breadth.
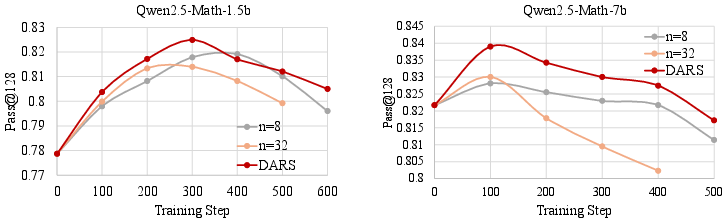
Figure 7: Pass@128 peaks early and then declines; DARS achieves the highest peak.
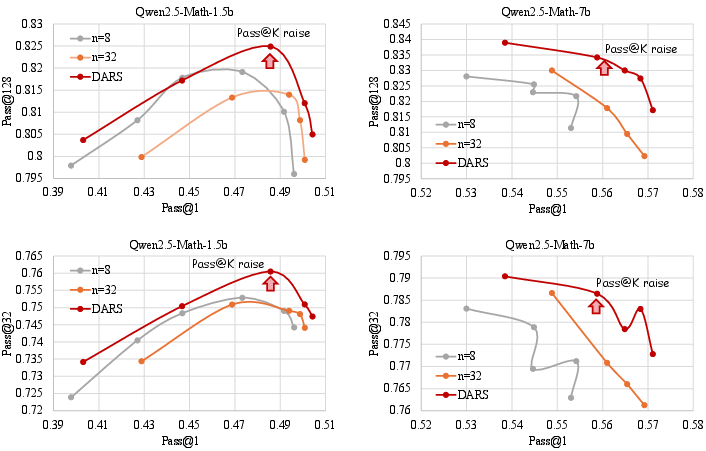
Figure 8: DARS consistently delivers higher Pass@K at any fixed Pass@1 level compared to naive scaling.
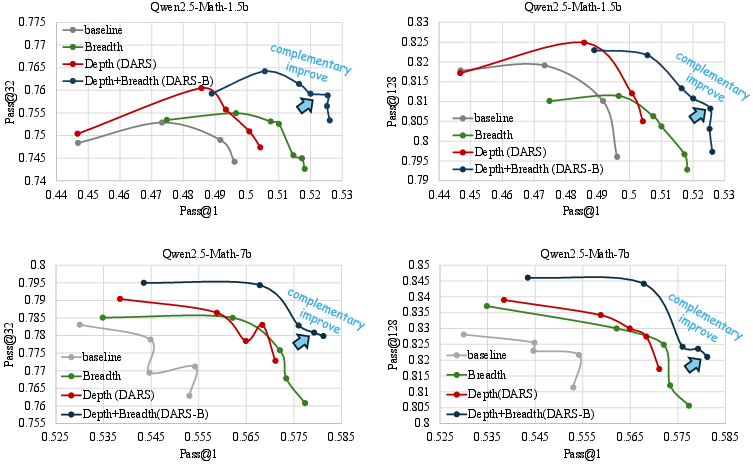
Figure 9: DARS-B achieves the outermost envelope in Pass@1–Pass@K space, demonstrating depth-breadth complementarity.
Implications and Future Directions
The findings have several important implications:
- Algorithmic: RLVR optimization should explicitly address both depth and breadth. Adaptive sampling (DARS) and large-batch training (breadth scaling) are orthogonal and synergistic.
- Practical: DARS and DARS-B can be implemented with minimal changes to existing RLVR pipelines, requiring only adaptive rollout allocation and full-batch PPO updates.
- Theoretical: The cumulative advantage bias in GRPO highlights the need for more nuanced credit assignment in RL for LLMs, especially for sparse-reward, high-difficulty tasks.
- Scaling: The approach is compatible with larger models and datasets, and the authors note plans to extend experiments to additional LLMs.
Future work may explore:
- Generalization of DARS to other domains (e.g., code generation, scientific reasoning).
- Automated schedule selection for rollout allocation.
- Integration with other RLVR variants and reward structures.
Conclusion
This work provides a rigorous analysis of the depth and breadth dimensions in RLVR for LLMs, identifying a key limitation in existing algorithms and proposing a principled solution. DARS and DARS-B demonstrate that adaptive exploration along both axes is essential for maximizing LLM reasoning performance, achieving simultaneous improvements in Pass@1 and Pass@K. The results establish a new standard for RLVR optimization and open avenues for further research into adaptive, scalable RL for LLMs.