Published 2 Sep 2025 in cs.CL, cs.AI, and cs.LG | (2509.02333v1)
Abstract: Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a promising framework for enhancing the reasoning capabilities of LLMs. However, existing approaches such as GRPO often suffer from zero gradients. This problem arises primarily due to fixed clipping bounds for token-level probability ratios and the standardization of identical rewards, which can lead to ineffective gradient updates and underutilization of generated responses. In this work, we propose Dynamic Clipping Policy Optimization (DCPO), which introduces a dynamic clipping strategy that adaptively adjusts the clipping bounds based on token-specific prior probabilities to enhance token-level exploration, and a smooth advantage standardization technique that standardizes rewards across cumulative training steps to improve the response-level effective utilization of generated responses. DCPO achieved state-of-the-art performance on four benchmarks based on four different models. In particular, DCPO achieved an Avg@1 of 46.7 under greedy decoding and an Avg@32 of 38.8 under 32 times sampling on the AIME24 benchmark, surpassing both DAPO (36.7/31.6) and GRPO (36.7/32.1) on the Qwen2.5-Math-7B model. On the AIME25 benchmark based on Qwen2.5-14B, DCPO achieves a performance of (23.3/19.0), surpassing GRPO (13.3/10.5) and DAPO (20.0/15.3). Furthermore, DCPO achieved an average 28% improvement in the nonzero advantage over GRPO in four models, doubled the training efficiency over DAPO, and significantly reduced the token clipping ratio by an order of magnitude compared to both GRPO and DAPO, while achieving superior performance. These results highlight DCPO's effectiveness in leveraging generated data more efficiently for reinforcement learning in LLMs.
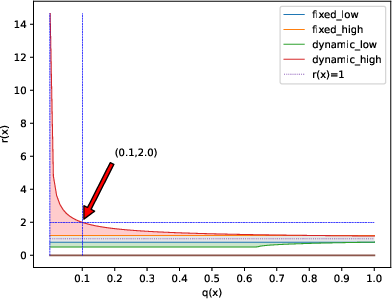
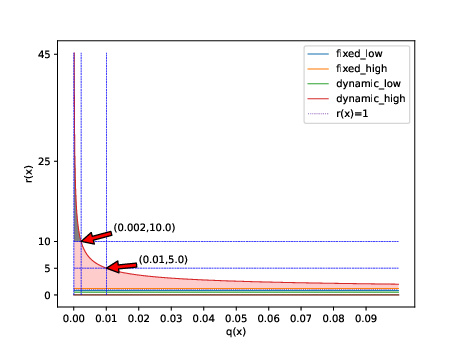
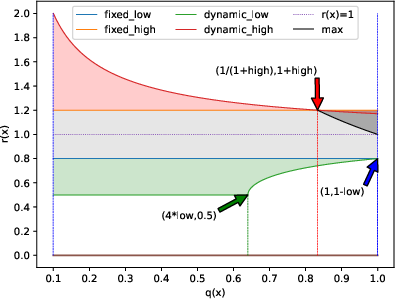
Traditional RLVR methods employ fixed symmetric clipping bounds on the probability ratio r(x)=q(x)p(x) to stabilize policy updates. However, this approach restricts exploration, especially for tokens with low prior probability under the old policy. DCPO replaces the fixed bound with a dynamic-adaptive scheme:
This formulation allows the clipping interval to expand for low-probability tokens, facilitating greater exploration in high-entropy regions while maintaining tight bounds for high-confidence tokens. A hard ceiling rmax=10 is imposed to prevent instability from excessively large importance weights.
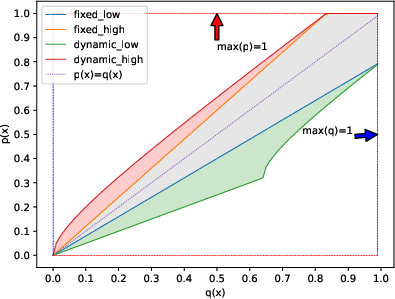
Figure 1: Not Clipped p(x) regions. Dynamic clipping enables broader update intervals for rare tokens, compared to fixed bounds.
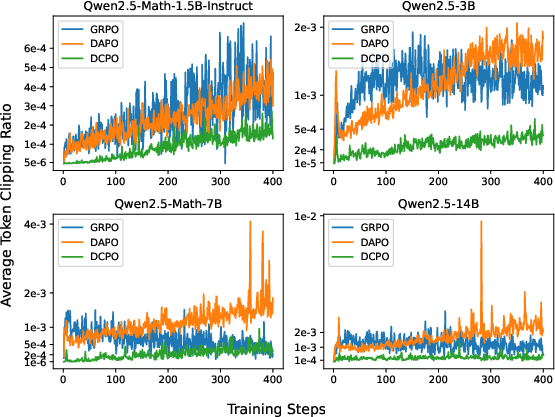
This adaptive mechanism is theoretically justified by variance-bias trade-offs in importance sampling and empirically shown to reduce the token clipping ratio (TCR) by an order of magnitude compared to GRPO and DAPO.
Figure 2: TCR across models and methods. DCPO maintains a consistently low and stable TCR, maximizing token-level data utilization.
Smooth Advantage Standardization
Standard RLVR advantage estimation normalizes rewards within each batch, leading to zero gradients when all responses receive identical rewards. DCPO introduces Smooth Advantage Standardization (SAS), which aggregates reward statistics cumulatively across all training steps:
A^total,ji=σtotaliRji−μtotali
A weighted average between current-step and cumulative standardization is computed, and the final advantage is selected to minimize fluctuation:
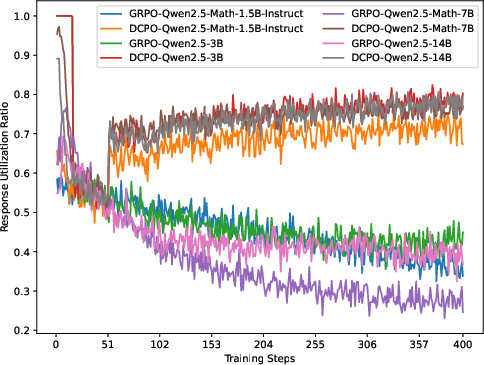
This approach ensures that all responses, even those with identical rewards, contribute to model updates, significantly increasing the response utilization ratio (RUR).
Figure 3: % RUR progresses during training. DCPO sustains high RUR, indicating efficient response-level data usage.
Only Token Mean Loss (OTM)
DCPO further refines the loss computation by averaging over tokens within each response, rather than across the batch. This preserves the relative advantage structure and prevents dilution effects from batch-level averaging, which are prevalent in GRPO and DAPO. The OTM loss is defined as:
This design ensures that each response's contribution to the loss is proportional to its advantage, independent of sequence length or batch composition.
Empirical Results
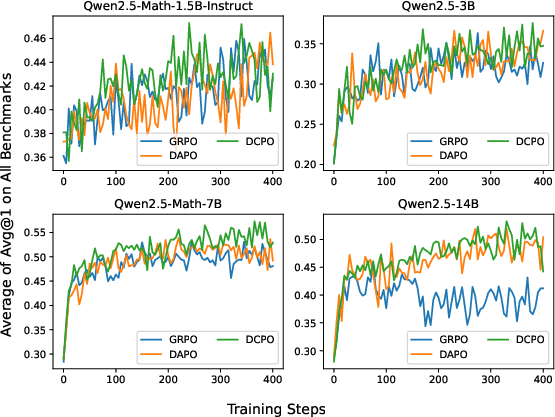
DCPO was evaluated on four mathematical reasoning benchmarks (MATH500, AMC23, AIME24, AIME25) using four Qwen2.5 model variants (1.5B, 3B, 7B, 14B). Metrics include Avg@1 (greedy decoding) and Avg@32 (32-sample stochastic decoding).
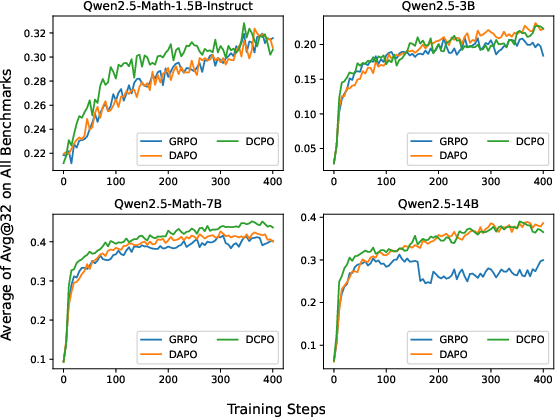
Figure 4: Avg@1 performance across benchmarks. DCPO consistently outperforms GRPO and DAPO in greedy decoding accuracy.
Figure 5: Avg@32 performance across benchmarks. DCPO demonstrates superior robustness and stability under sampling-based evaluation.
Key findings:
DCPO achieves state-of-the-art results: On AIME24 (Qwen2.5-Math-7B), DCPO attains Avg@1/Avg@32 of 46.7/38.8, surpassing DAPO (36.7/31.6) and GRPO (36.7/32.1).
Substantial efficiency gains: DCPO increases RUR by 28% over GRPO and doubles training efficiency compared to DAPO.
Reduced token clipping: TCR is an order of magnitude lower than baselines, indicating minimal data waste.
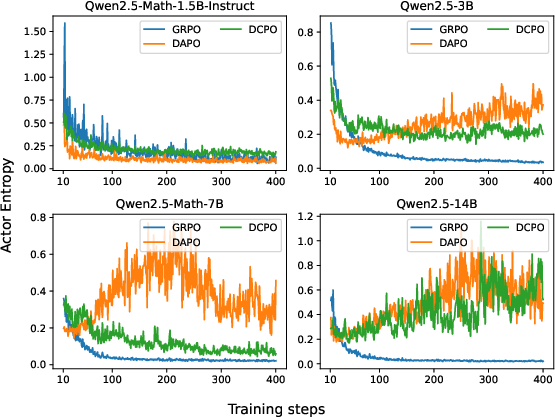
Stable entropy regulation: DCPO maintains moderate entropy throughout training, avoiding both collapse and instability.
Figure 6: The Entropy of the models during Training. DCPO maintains balanced entropy, supporting both convergence and exploration.
Ablation and Analysis
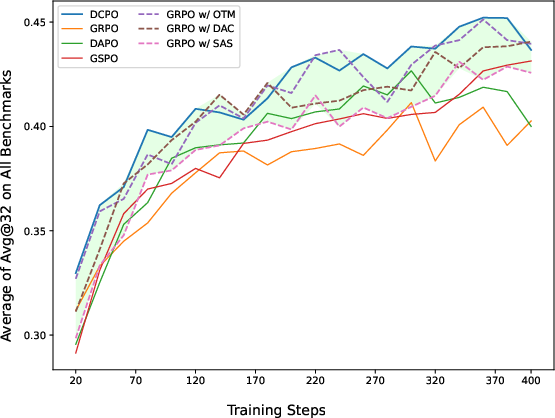
Ablation studies confirm that each DCPO component (OTM, SAS, DAC) contributes positively to performance and training stability. The combination yields cumulative gains, with DCPO outperforming GRPO, DAPO, and GSPO across all metrics. Notably, DCPO's dynamic clipping mechanism is particularly effective in enhancing exploration of rare, high-entropy tokens, which are crucial for emergent reasoning capabilities.
Practical and Theoretical Implications
DCPO's innovations have direct implications for RLVR in LLMs:
Maximized data efficiency: By reducing token and response waste, DCPO enables faster convergence and better utilization of computational resources.
Enhanced exploration: Dynamic clipping allows the model to learn from rare tokens, improving generalization and reasoning.
Stable optimization: Smooth advantage standardization and OTM loss prevent gradient collapse and maintain robust training dynamics.
Theoretically, DCPO's probability-dependent clipping aligns with optimal variance-bias trade-offs in off-policy RL, and its cumulative standardization leverages the global reward distribution for more reliable policy updates.
Future Directions
Potential extensions of DCPO include:
Application to other RLHF/RLVR domains, such as code generation and semantic reasoning.
Integration with more complex reward models, including human feedback or multi-objective optimization.
Exploration of adaptive entropy regulation mechanisms for further stability and diversity.
Conclusion
DCPO represents a significant advancement in RLVR for LLMs, addressing longstanding issues of sample inefficiency and restricted exploration. Through dynamic-adaptive clipping and smooth advantage standardization, DCPO achieves superior performance, efficiency, and stability across multiple benchmarks and model scales. Its design principles are broadly applicable to reinforcement learning in generative models, with promising implications for future research in scalable, data-efficient LLM optimization.