- The paper introduces RL-PLUS, a hybrid-policy optimization approach that counteracts capability boundary collapse in LLMs by integrating internal exploitation with external data exploration.
- It employs multiple importance sampling to reduce bias and variance in off-policy learning, ensuring robust policy updates despite distribution mismatches.
- Experimental results show up to 69.2% relative improvement and state-of-the-art performance on six math reasoning benchmarks, validating its efficacy.
Hybrid-Policy Optimization for Enhanced LLM Reasoning
The paper "RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization" (2508.00222) addresses a critical limitation in applying RLVR to LLMs: the collapse of capability boundaries, where RLVR-trained models, while improving performance on known tasks, fail to expand their ability to solve novel problems. To overcome this, the authors introduce RL-PLUS, a hybrid-policy optimization approach that synergizes internal exploitation with external data to enhance reasoning capabilities and surpass the limitations of base models. The approach integrates multiple importance sampling to handle distributional mismatch from external data and an exploration-based advantage function to guide the model towards high-value, unexplored reasoning paths.
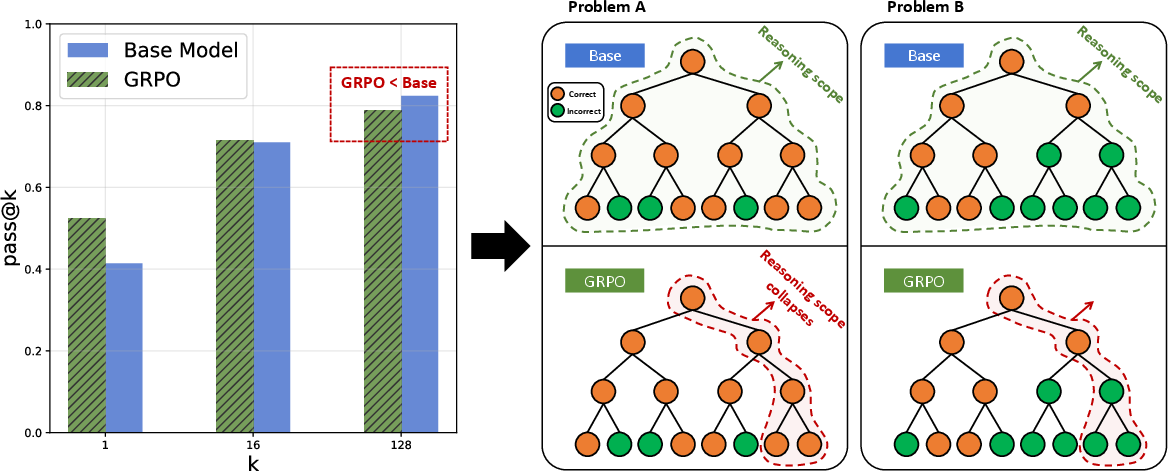
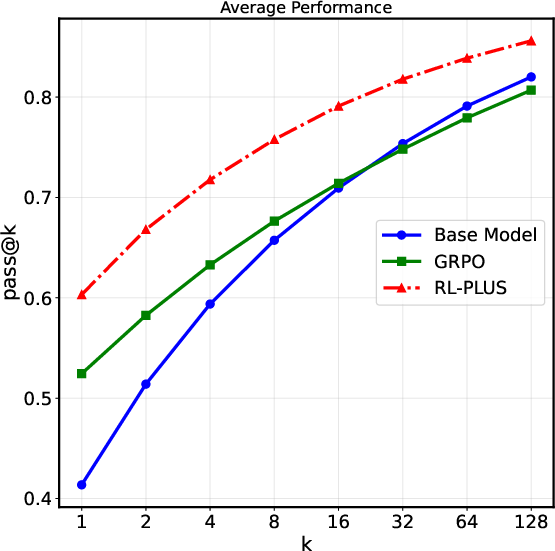
Figure 1: The commonly used RLVR methods can lead to the collapse problem of capability boundaries in base LLMs.
Background and Problem Statement
The RLVR paradigm has shown promise in improving the reasoning performance of LLMs in complex tasks like math and coding. By optimizing LLMs through RL with verifiable rewards, these methods enable models to scale computation at test time and exhibit sophisticated cognitive behaviors. However, recent studies indicate that current RLVR methods primarily exploit existing knowledge rather than acquiring new reasoning abilities. This leads to a capability boundary collapse, where the model's ability to solve a diverse range of problems diminishes after RLVR training (Figure 1). This limitation stems from the vast action space of LLMs and the sparse rewards in long reasoning tasks, which make it difficult for the model to explore new and unknown pathways. Current RLVR techniques tend to focus on inward exploitation, refining existing knowledge, rather than outward exploration, thus limiting the acquisition of new reasoning pathways.
RL-PLUS Methodology
RL-PLUS addresses the limitations of existing RLVR methods by integrating external learning with internal exploitation. The approach incorporates two core techniques: multiple importance sampling and an exploration-based advantage function.
Multiple Importance Sampling
The distributional mismatch between the model's policy and external data sources poses a challenge for effective learning. Standard importance sampling corrections are inadequate, as on-policy proxies introduce systematic bias, while off-policy methods suffer from high variance and bias. To address this, RL-PLUS employs multiple importance sampling, which combines information from multiple policies to provide a lower bias and variance estimation of importance. The method treats the generation of an external sample as arising from a mixture policy composed of the previous policy $\pi_{\theta_{old}$ and the external policy πω. By using a mixture of policies in the importance sampling ratio, RL-PLUS mitigates the explosive bias from poor proxies or support mismatch, making the estimator more robust for stable learning from external data.
Exploration-Based Advantage Function
To efficiently extract valuable information from external data, RL-PLUS introduces an exploration-based advantage function. This function reshapes the learning objective by prioritizing advantages for reasoning paths that are correct but hard to explore under the current policy. The method encourages the model to explore low-probability tokens that might lead to novel reasoning paths.
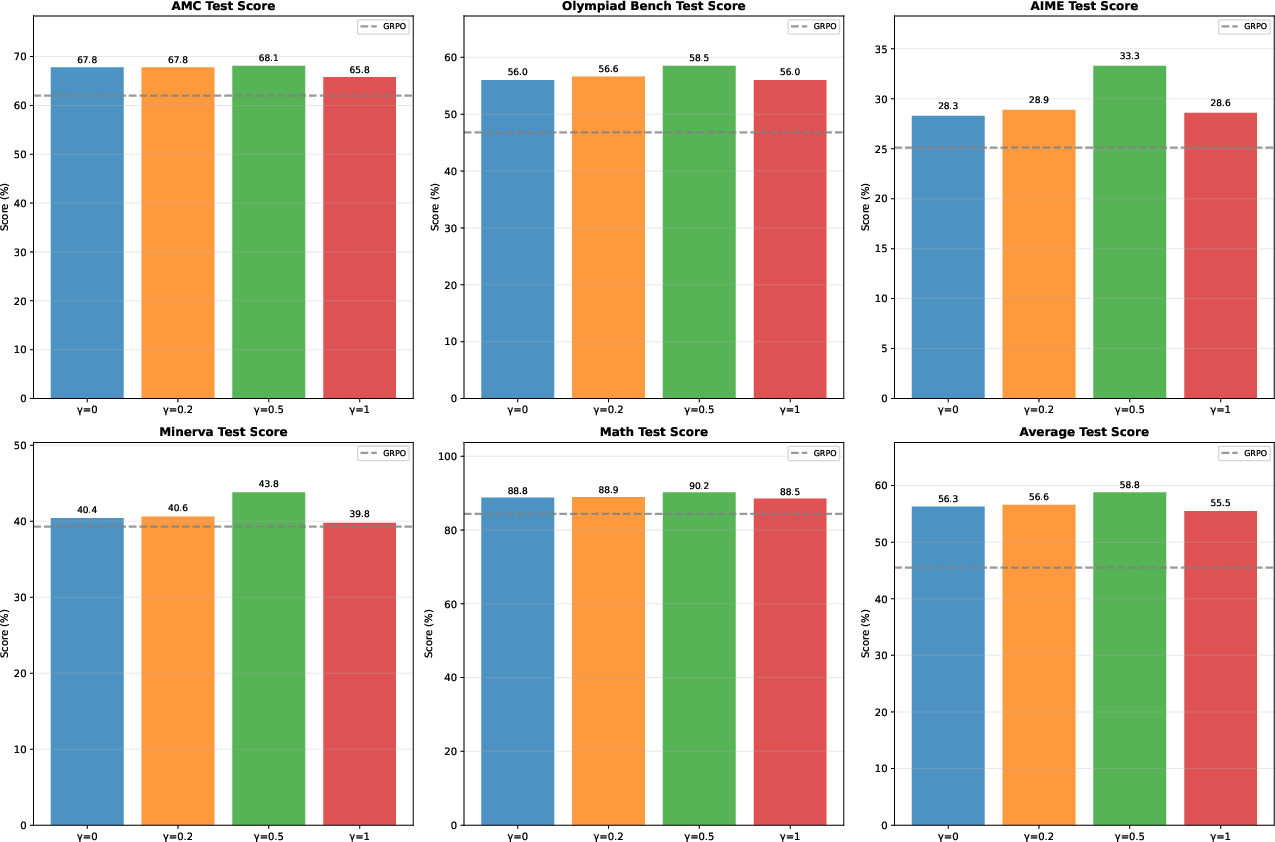
Figure 2: Effect of hyperparameter gamma in RL-PLUS.
The exploration-based advantage function, Ai,tc, is defined as:
Ai,tc=std({R1,R2,…,RG})Ri−mean({R1,R2,…,RG})⋅Ci,t, where Ci,t=(1−detach(πθ(ei,t∣q,ei,<t)))γ. This prioritizes reasoning steps that are correct but have low probability under the current policy, effectively amplifying the advantage signal for overlooked regions. The hyperparameter γ controls the strength of this exploration (Figure 2).
Composite Objective
The final training objective of RL-PLUS is a composite function that synergizes internal exploitation with external data:
$\mathcal{J}_{\text{RL-PLUS}(\theta) = \underbrace{\mathbb{E}_{(o_i, A_{i}) \sim \mathcal{D}_o} \left[ r_{i,t}(\theta) A_{i} \right]}_{\text{Internal Exploitation (Thinking)} + \underbrace{\mathbb{E}_{(e_i, A_{i,t}^c) \sim \mathcal{D}_e} \left[ r_{i,t}^m(\theta) A_{i,t}^c \right]}_{\text{External data for Exploration (Learning)}}$. The objective combines the standard policy gradient objective for internal exploitation with a term that drives the policy towards external exploration, leveraging multiple importance sampling and the exploration-based advantage function.
Experimental Evaluation and Results
The paper presents extensive experiments to demonstrate the effectiveness and generalization of RL-PLUS. The method achieves state-of-the-art performance on six math reasoning benchmarks, outperforming existing RLVR methods and improving upon SFT+GRPO by 5.2 average points (Table 1). RL-PLUS also demonstrates superior generalization to six out-of-distribution tasks (Table 2).
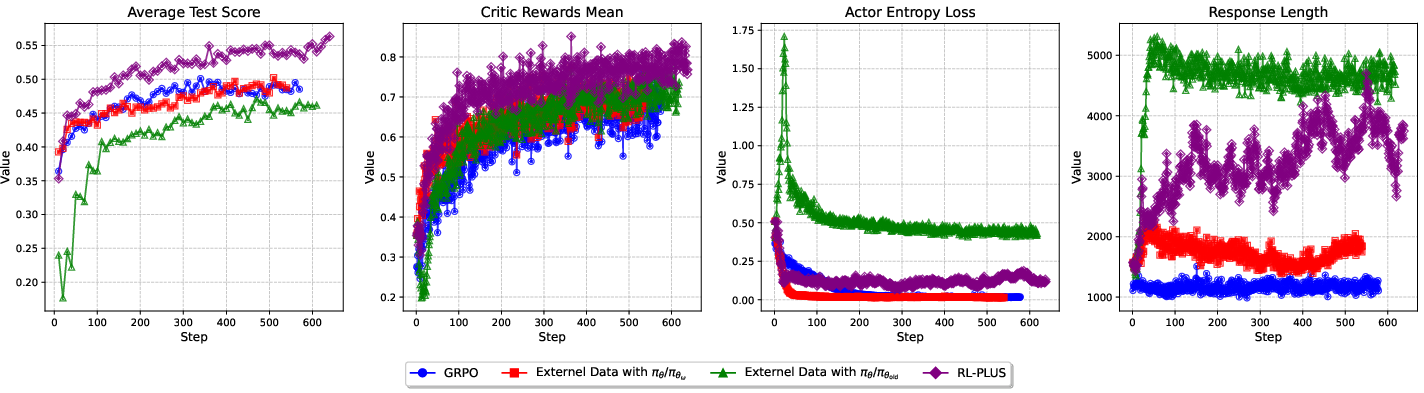
Figure 3: Training dynamics of RL-PLUS and other baselines.
Furthermore, RL-PLUS exhibits clear and stable improvements across diverse model families, with average relative improvements of GRPO up to 69.2%. Analysis of pass@k curves indicates that RL-PLUS effectively transcends the inherent capability ceiling of the base model, addressing the capability boundary collapse observed in prior RLVR approaches (Figure 4). The training dynamics show that RL-PLUS consistently outperforms baselines in terms of test accuracy and rewards throughout training (Figure 3). RL-PLUS maintains a considerable capacity for exploration.
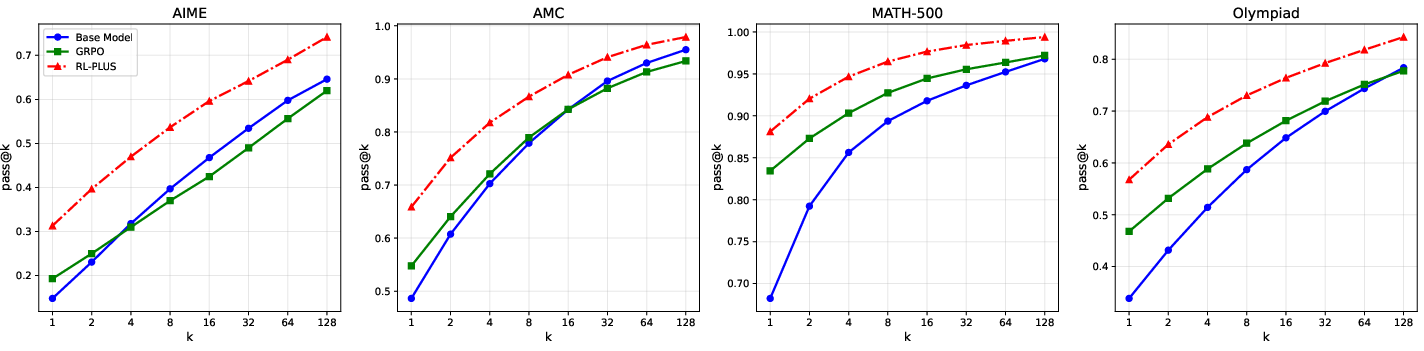
Figure 4: Pass@k curves of RL-PLUS compared with baselines across multiple benchmarks.
Ablation Studies and Analysis
Ablation studies validate the contribution of each component of RL-PLUS. Removing the exploration-based advantage function decreases average performance, demonstrating the importance of efficient exploration. Removing multiple importance sampling leads to a more significant performance degradation, highlighting the significance of incorporating external knowledge. Additional analysis compares RL-PLUS against naive approaches for integrating external knowledge, demonstrating the effectiveness of the proposed policy estimation method.
Conclusion
The paper introduces RL-PLUS, a hybrid-policy optimization approach that addresses the capability boundary collapse in LLMs trained with RLVR. By synergizing external data with internal exploitation, RL-PLUS achieves state-of-the-art performance on math reasoning benchmarks and demonstrates superior generalization to out-of-distribution tasks. The method's ability to break through the reasoning capability boundary of base models and achieve further performance improvements highlights its potential for advancing LLM reasoning.