- The paper introduces Pass@k Training, leveraging the Pass@k reward metric to enhance exploration in large reasoning models without degrading Pass@1 performance.
- It employs both full sampling and bootstrap sampling techniques to efficiently generate diverse responses while reducing computational costs and variability.
- Analytical derivation of advantage functions and implicit reward designs stabilize training and improve generalization across various tasks and domains.
Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models
Introduction
The paper introduces a novel approach called Pass@k Training, designed to enhance the reinforcement learning with verifiable rewards (RLVR) for large reasoning models (LRMs). Traditional RLVR methods often focus on the Pass@1 metric, which optimizes for a single, most confident response, leading to imbalanced exploration and exploitation. The proposed Pass@k Training uses the Pass@k metric as a reward to improve exploration capabilities, allowing the model to generate multiple diverse responses, potentially capturing a wider range of solutions.
Pass@k as Reward in RLVR Training
The Pass@k metric evaluates whether a model can generate a successful response within k attempts. By integrating this into the RLVR process, the paper aims to address the inherent limitations of Pass@1 Training, where exploration is often sacrificed for exploitation.
Full Sampling Implementation
The basic implementation of Pass@k Training involves rolling out Nrollout responses, separating them into groups, and assigning rewards based on the maximum success among the sampled responses. This method demonstrated significant improvements in exploration capabilities without degrading Pass@1 performance (Figure 1).
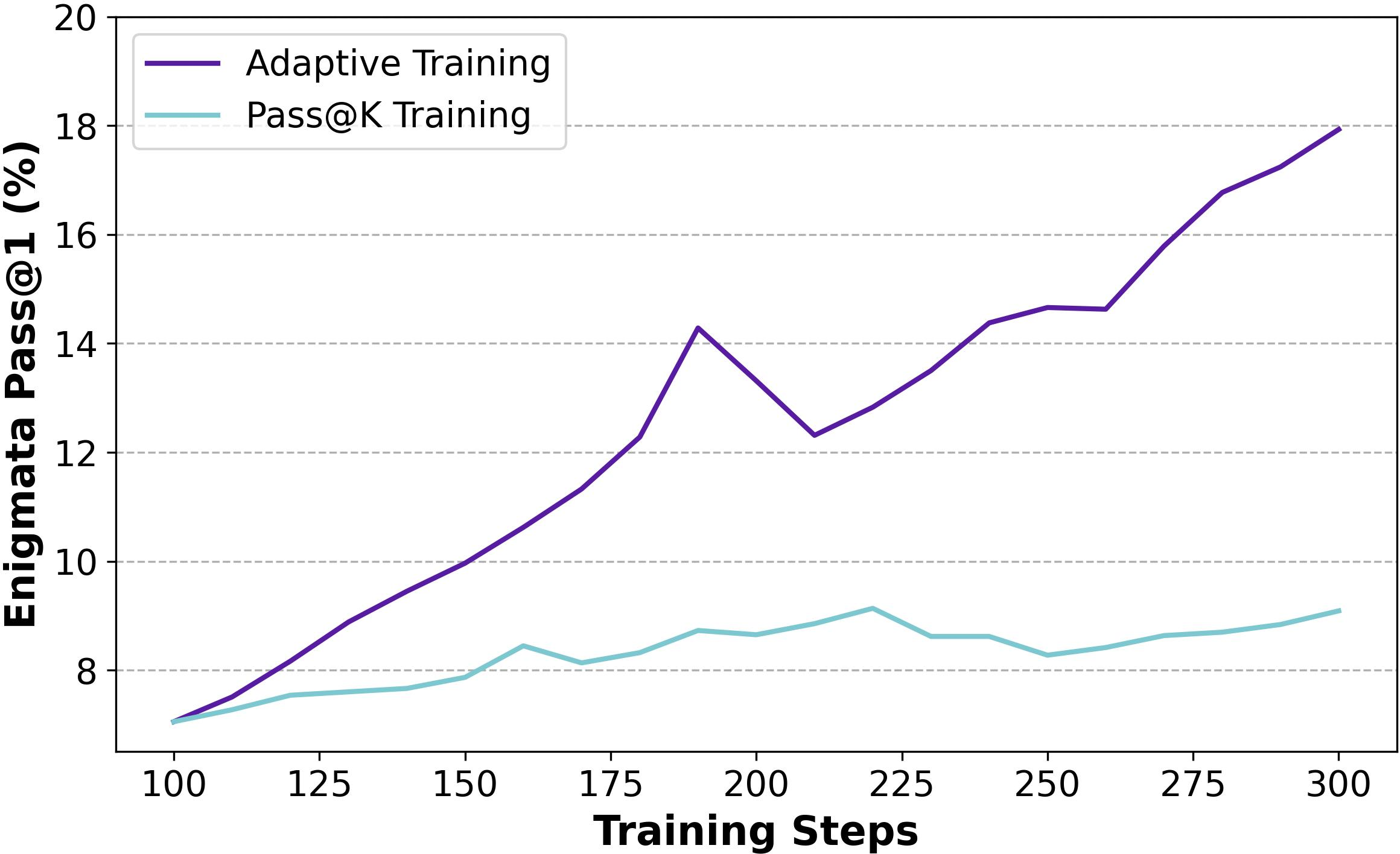
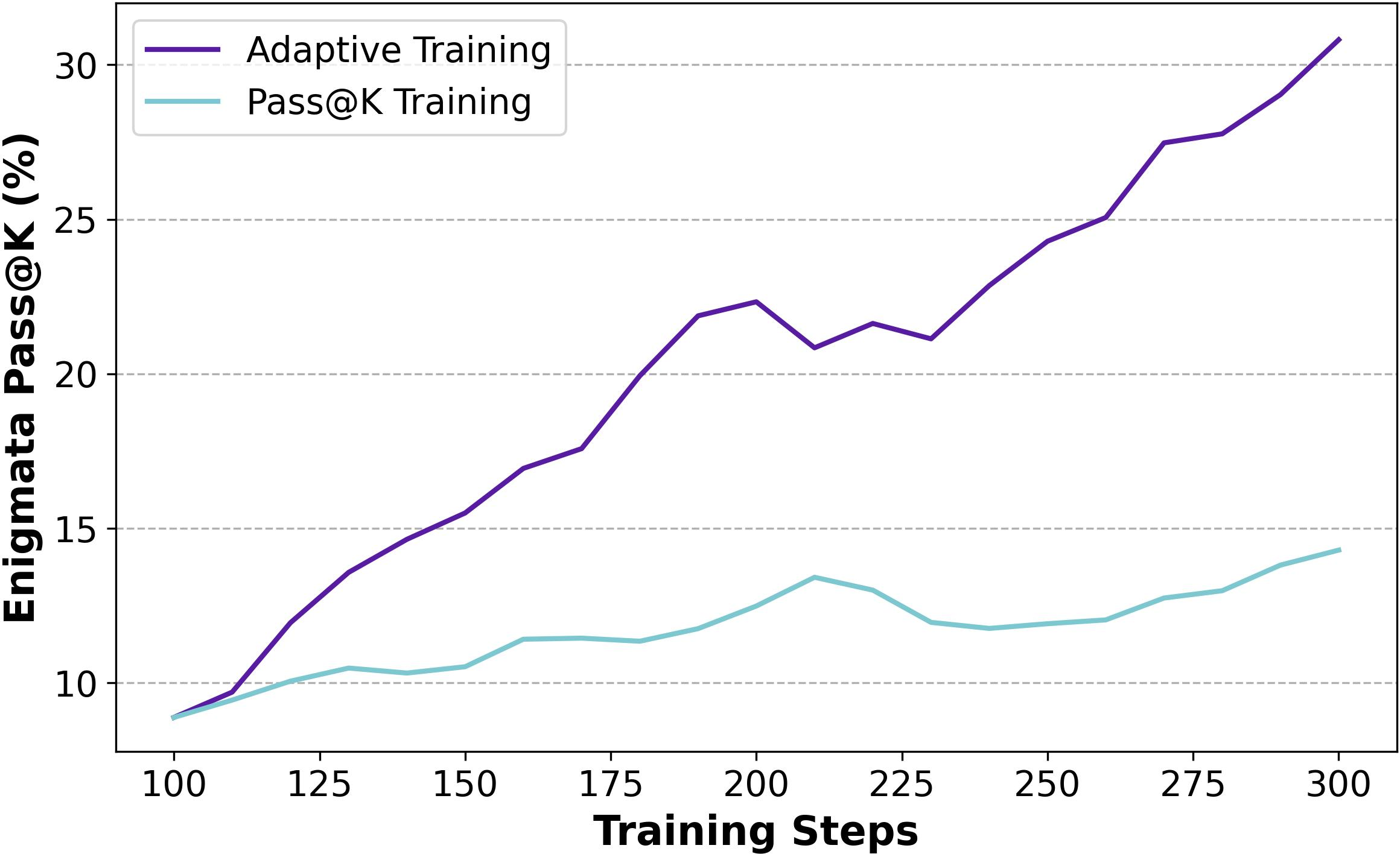
Figure 1: Training progress of Pass@1 Training and Pass@k Training with Full Sampling on baseline setting.
Efficient Training with Bootstrap Sampling
To optimize the computational efficiency, bootstrap sampling is introduced. This method constructs multiple groups from the same rollout responses, reducing the required computational resources while maintaining performance. Bootstrap sampling achieved higher training efficiency compared to full sampling (Figure 2).
Figure 2: Training progress of Pass@1 Training and Pass@k Training with Bootstrap Sampling under various $N_\text{rollout$.
Analytical Derivation
An analytical approach to derive the advantage values is presented, reducing variability introduced by sampling and further enhancing the efficiency of Pass@k Training (Figure 3). This method allows for a more stable training process, contributing to continuous performance improvements in exploration tasks.
Figure 3: Training progress of Pass@1 Training and Pass@k Training with Analytical Derivation and Bootstrap Sampling on baseline setting.
Balancing Exploration and Exploitation
Pass@k Training not only improves exploration by maintaining higher entropy and diversity in response generation (Figures 6 and 7) but also exhibits strong generalization capabilities across various domains and tasks. This robustness makes it superior to typical noise-induced rewards or entropy regularization methods, which often lead to new trade-off challenges.
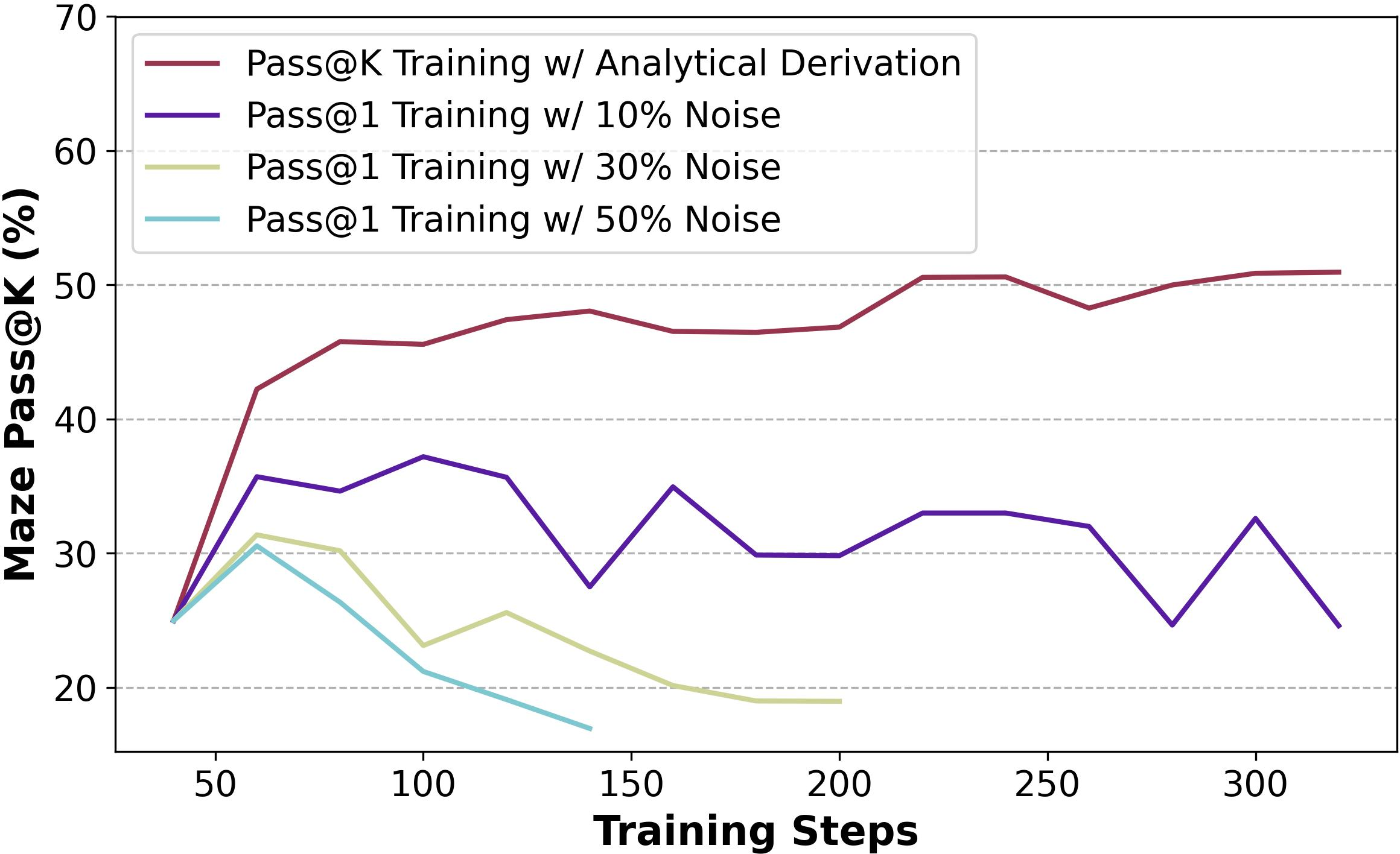
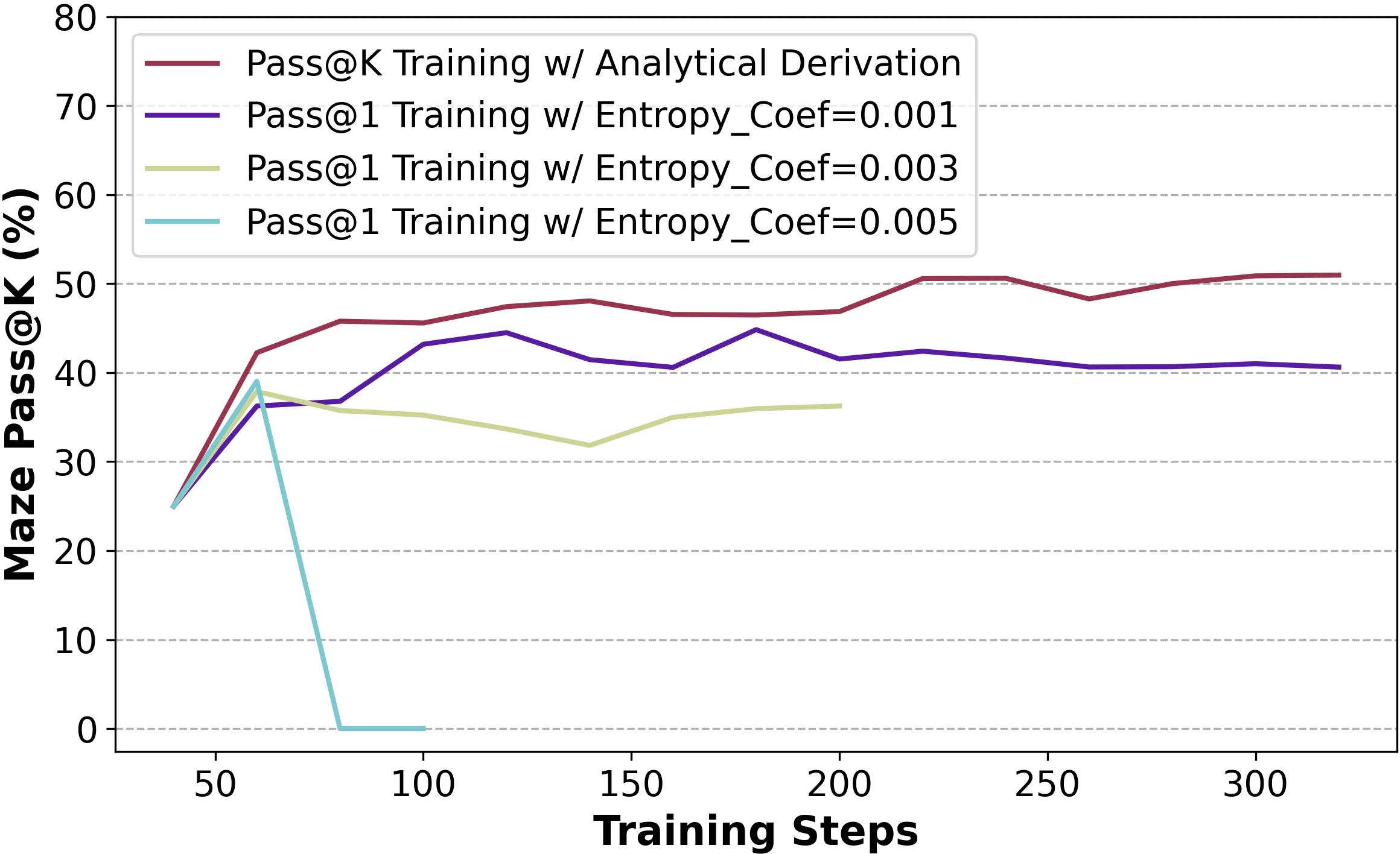
Figure 4: Training progress of Noise Rewards and Entropy Regularization on baseline setting.
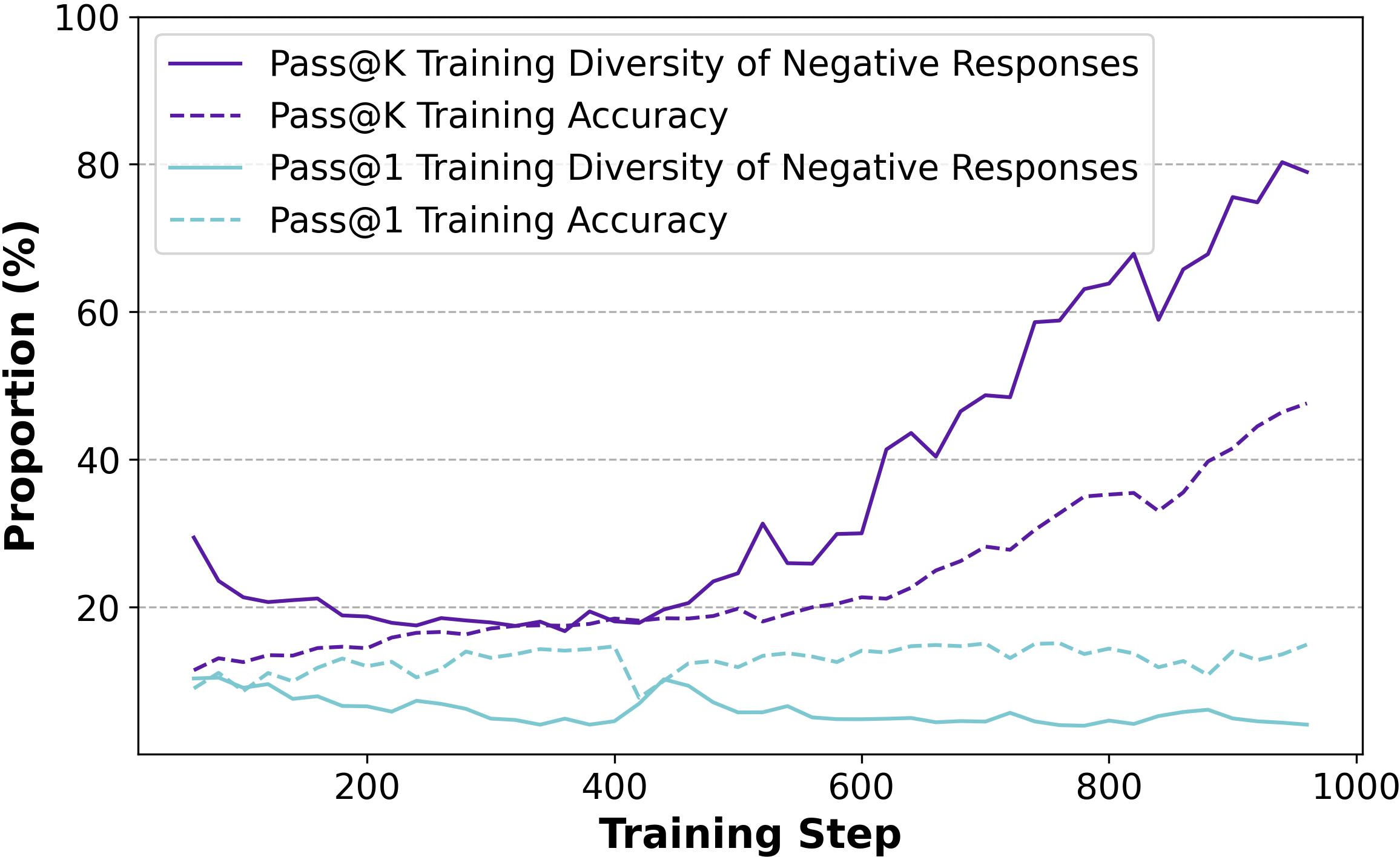
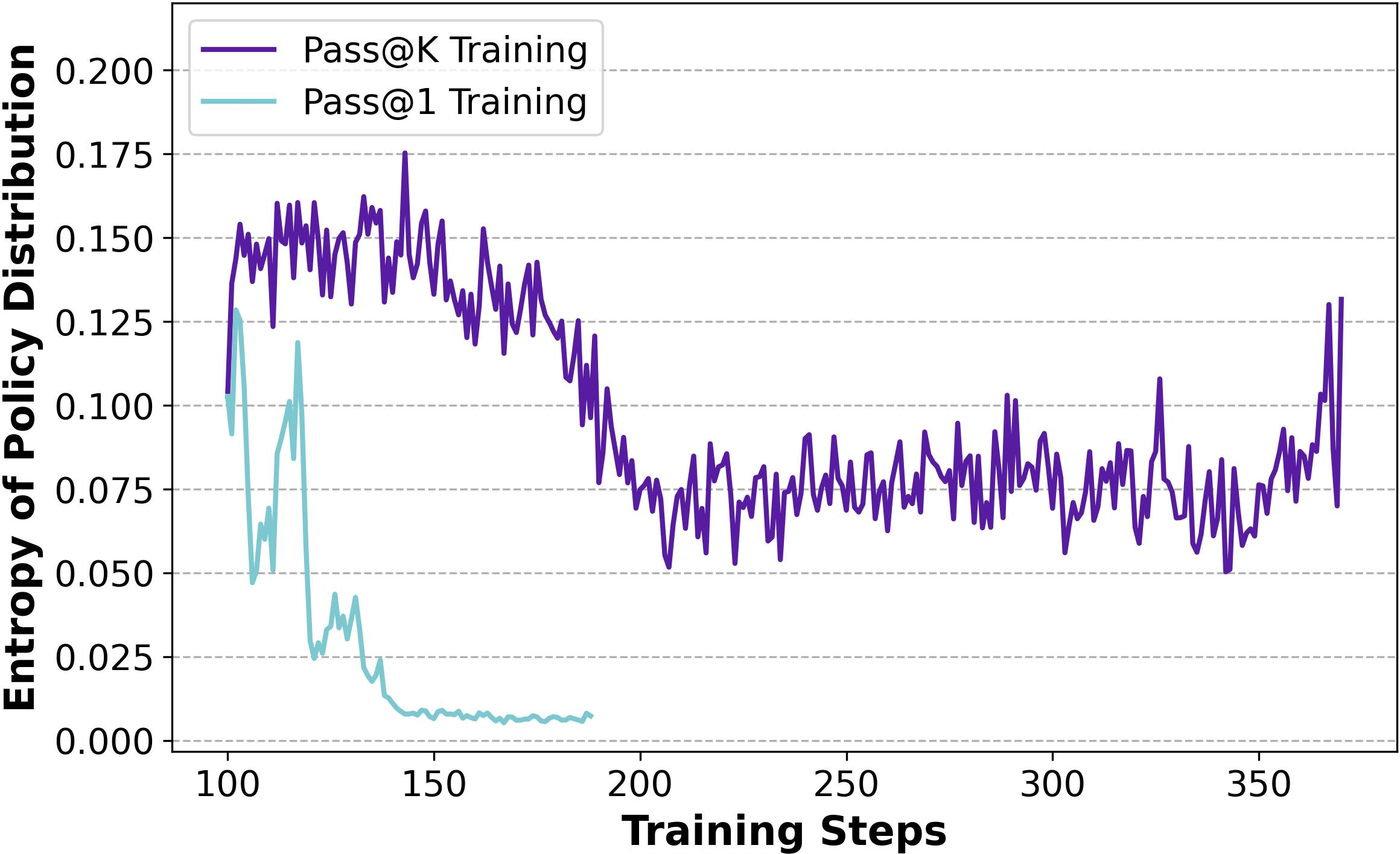
Figure 5: Diversity of Negative Responses on Maze Tasks.
Generalization and Robustness
The method demonstrates robust exploration capabilities across different task types and model architectures. Although increasing k may reduce training efficiency, this can be mitigated with appropriate learning rate adjustments (Figure 6).
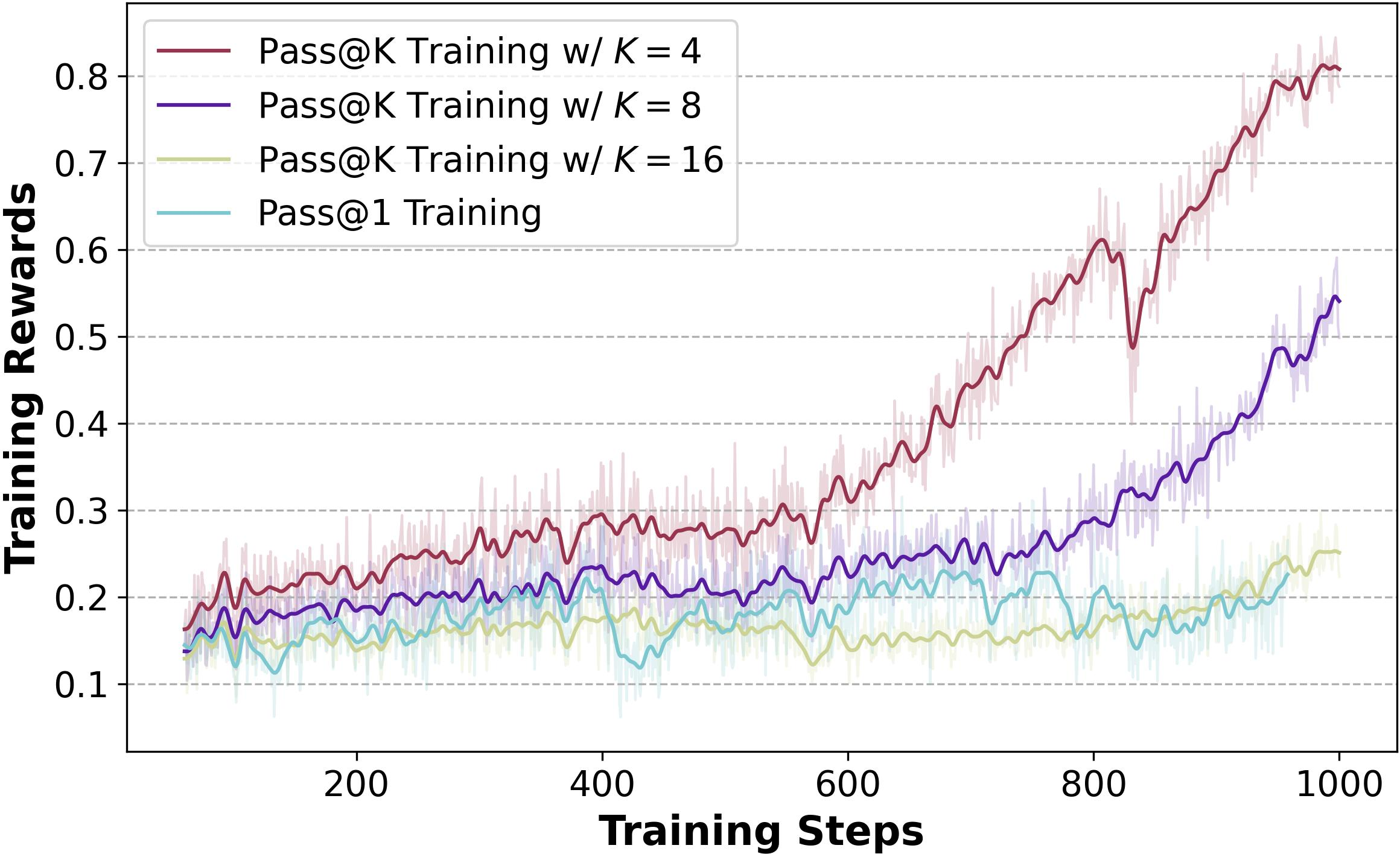
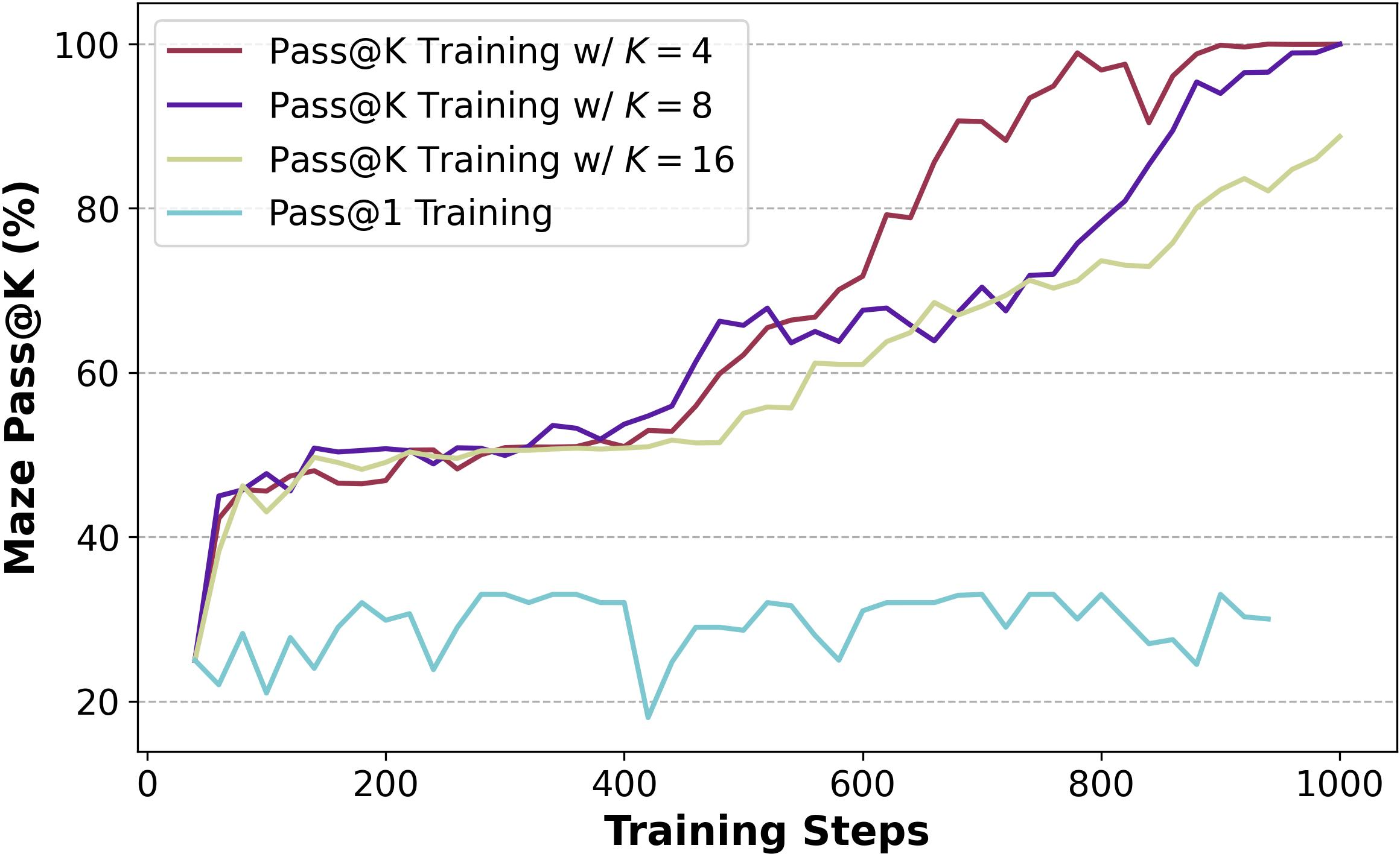
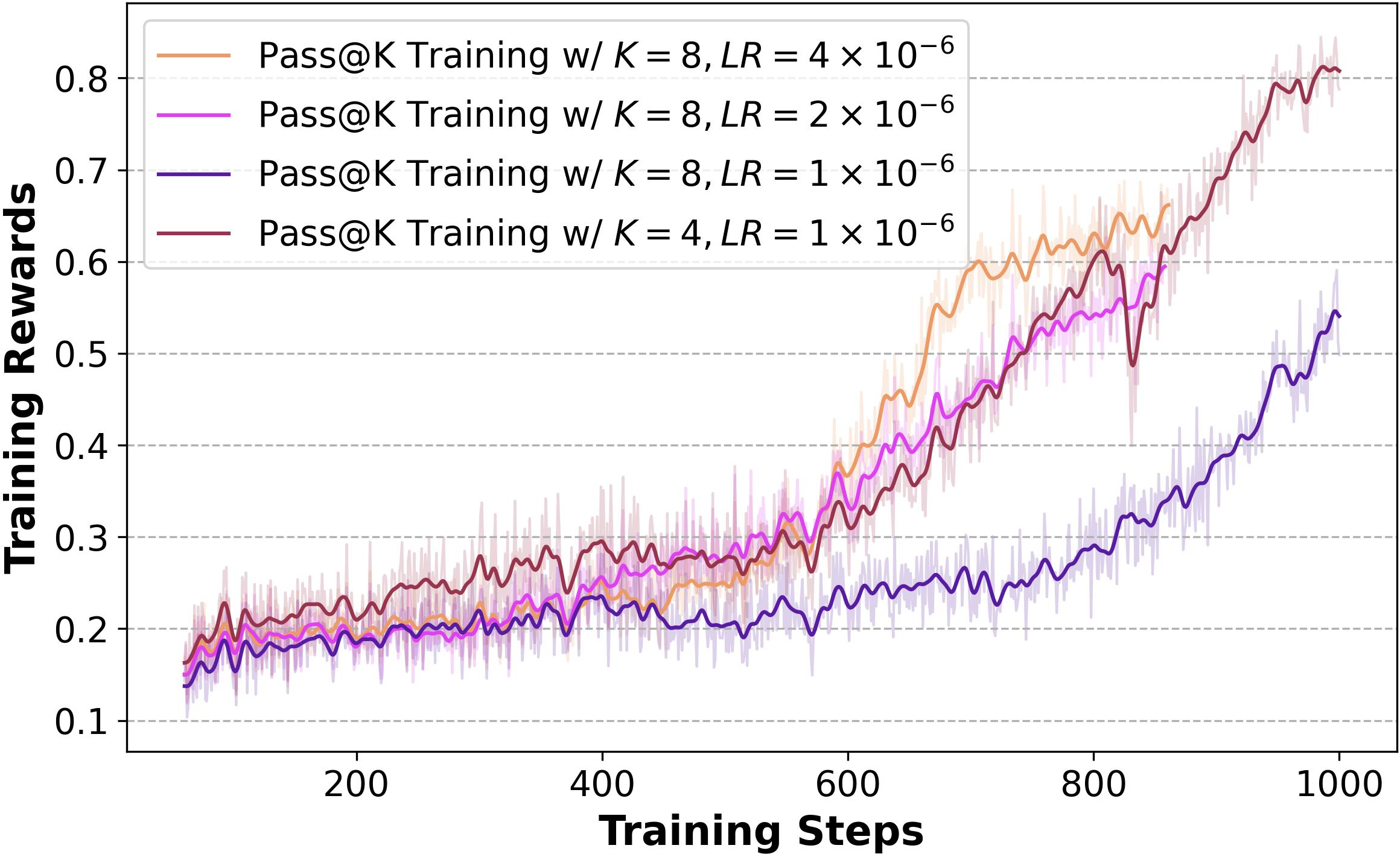
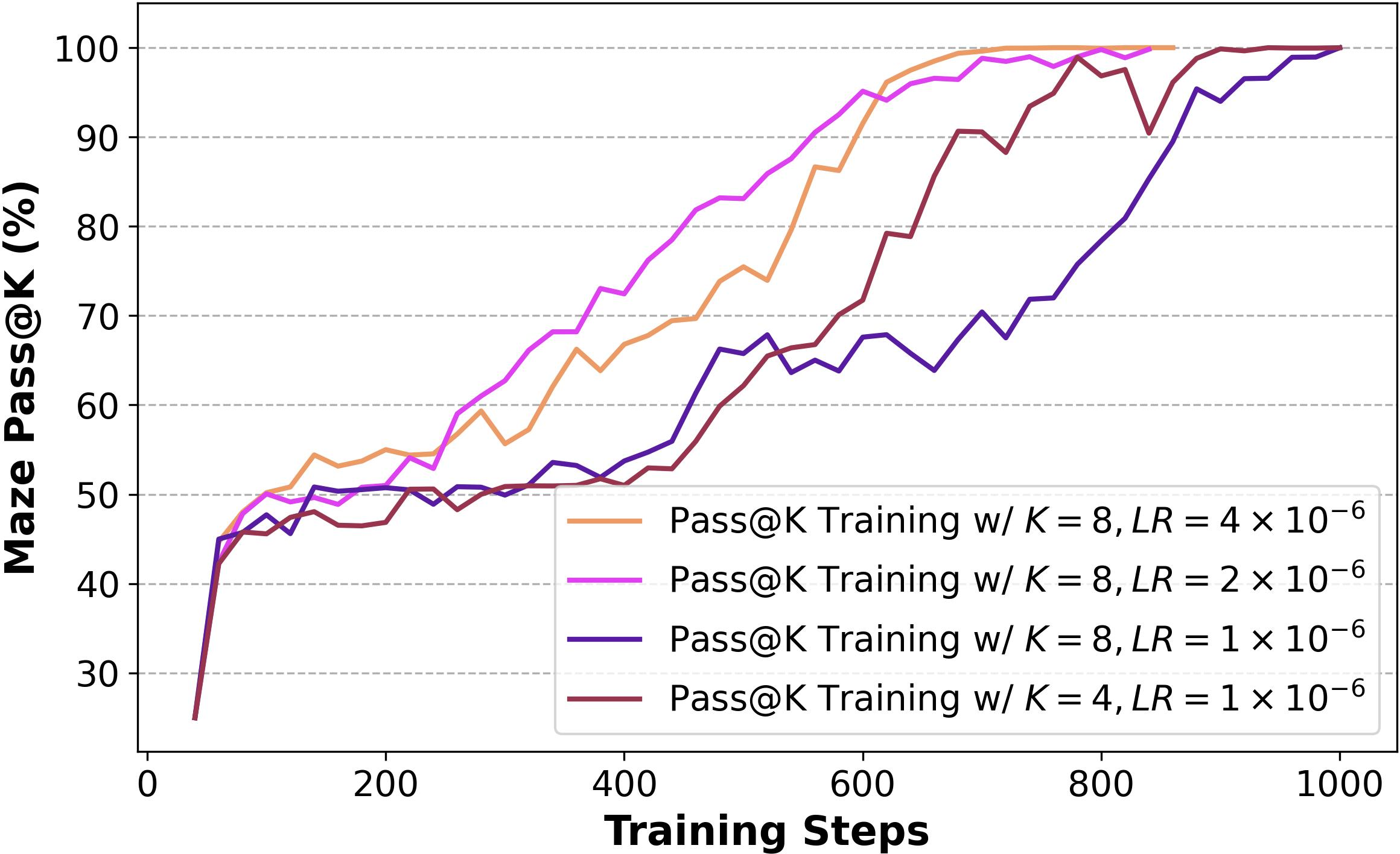
Figure 6: Training progress of Pass@k Training under various k and learning rate (LR).
Practical Application and Transfer of Benefits
The benefits of Pass@k Training can be effectively transferred to enhance Pass@1 performance, as evidenced in various labyrinthine and mathematical reasoning tasks. This transferability underscores the potential of Pass@k Training to drive performance in LLMs beyond mere exploratory tasks.
Generalizing Pass@k Training via Implicit Reward Design
Analysis of Advantage Functions
The analysis reveals that the success of Pass@k Training is influenced by the position of the advantage function's maximum and its trend, suggesting that focusing on harder problems might improve optimization efficiency.
Implicit Reward Design
The study explores potential implicit reward designs, such as Exceeding Pass@k Training and a combination of Pass@1 and Pass@k Training, showing improved model performance. Adaptive strategies guided by policy entropy further enhance both exploration and exploitation capabilities (Figures 11-13).
Figure 7: Training progress of Pass@k Training and Exceeding Pass@k Training on baseline setting.
Figure 8: Training progress of Pass@k Training and Combination Training on baseline setting.
Figure 9: Training progress of Pass@k Training and Adaptive Training on baseline setting.
Conclusion
Pass@k Training represents a significant advancement in balancing exploration and exploitation in RLVR for LRMs. By incorporating the Pass@k metric as a reward, the paper demonstrates its potential to enhance exploration without adversely affecting performance, paving the way for future research in RLVR training methodologies and implicit reward design.