- The paper introduces a simulator that models heterogeneous LLM training workloads by enabling custom device groupings, hybrid parallelism, and topology-aware network simulation.
- The methodology evaluates compute heterogeneity and interconnect disparities, showing up to 4x slowdowns in compute and 25.3x delays in mixed GPU configurations.
- The implications guide optimal placement strategies to reduce synchronization stalls, maximize throughput, and enhance cost-effective LLM infrastructure design.
Simulating LLM Training on Heterogeneous Compute and Network Infrastructure
Motivation and Problem Statement
The exponential growth in LLM complexity and scaling, paired with rapid hardware innovation, necessitates distributed training across massive, multi-generation GPU clusters. Maintaining homogeneous compute/network environments imposes substantial economic and operational friction, particularly in shared cloud facilities and transitional periods between hardware upgrades. However, state-of-the-art LLM training simulators—specifically ASTRA-Sim and SimAI—presume uniform compute and network setups, rendering them inadequate for simulating deployment strategies in realistic, heterogeneous clusters.
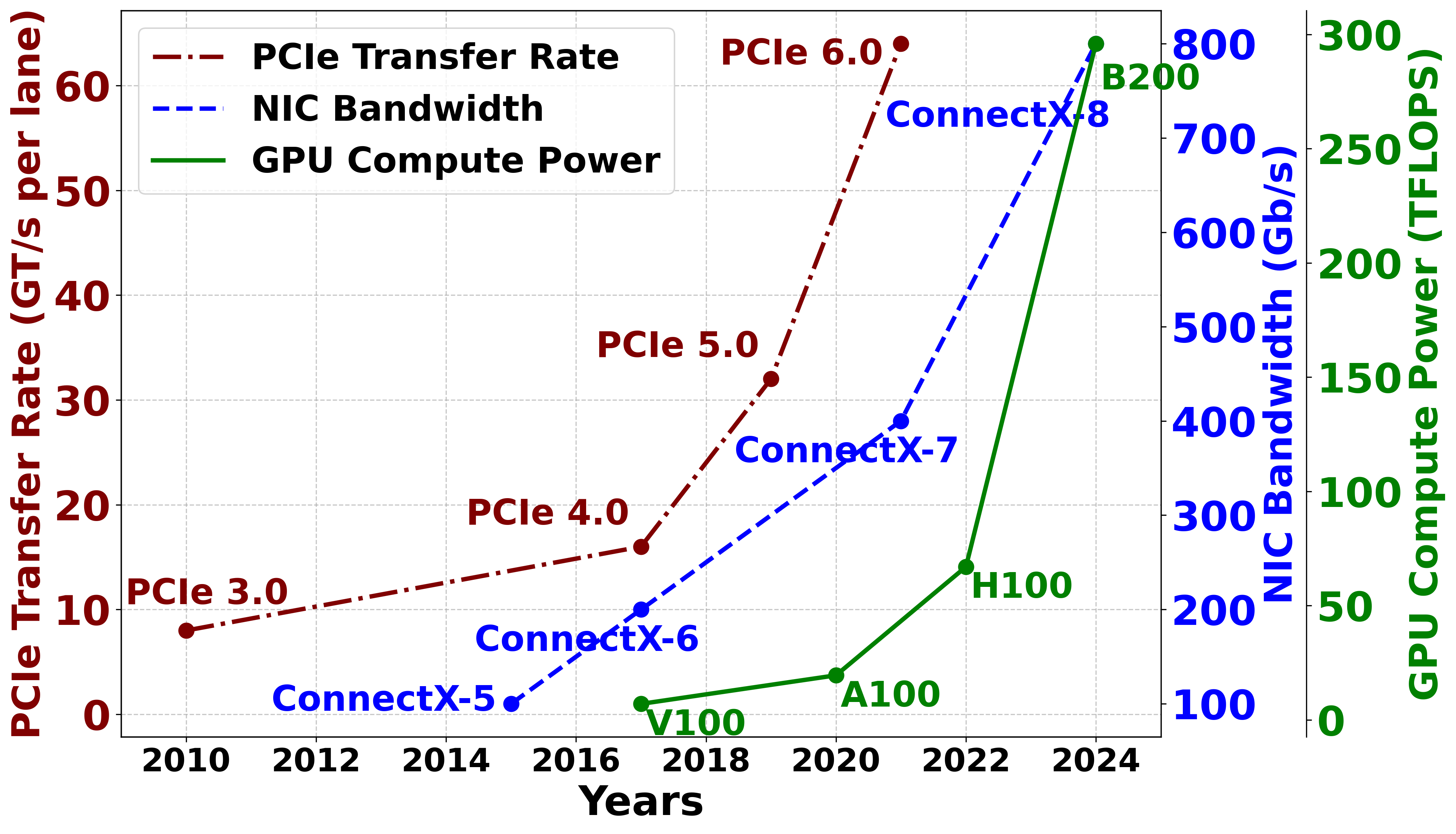
Figure 1: Evolution of AI cluster hardware.
This paper addresses the fundamental modeling and simulation gap by introducing a heterogeneity-aware distributed training simulator. The solution enables explicit specification of device groupings, non-uniform workload partitioning, device-to-parallelism mapping, and detailed hardware topology and interconnect abstractions. This framework facilitates targeted evaluation of compute/network bottlenecks, thus guiding deployment decisions and system architecture refinements.
Cluster Topology and Parallelism Analysis
Modern LLM clusters employ “rail-only” topologies that maximize intra-node communication using high-bandwidth NVLink, while leveraging dedicated NICs for inter-node traffic—optimizing both bandwidth and latency for collective operations such as AllReduce.
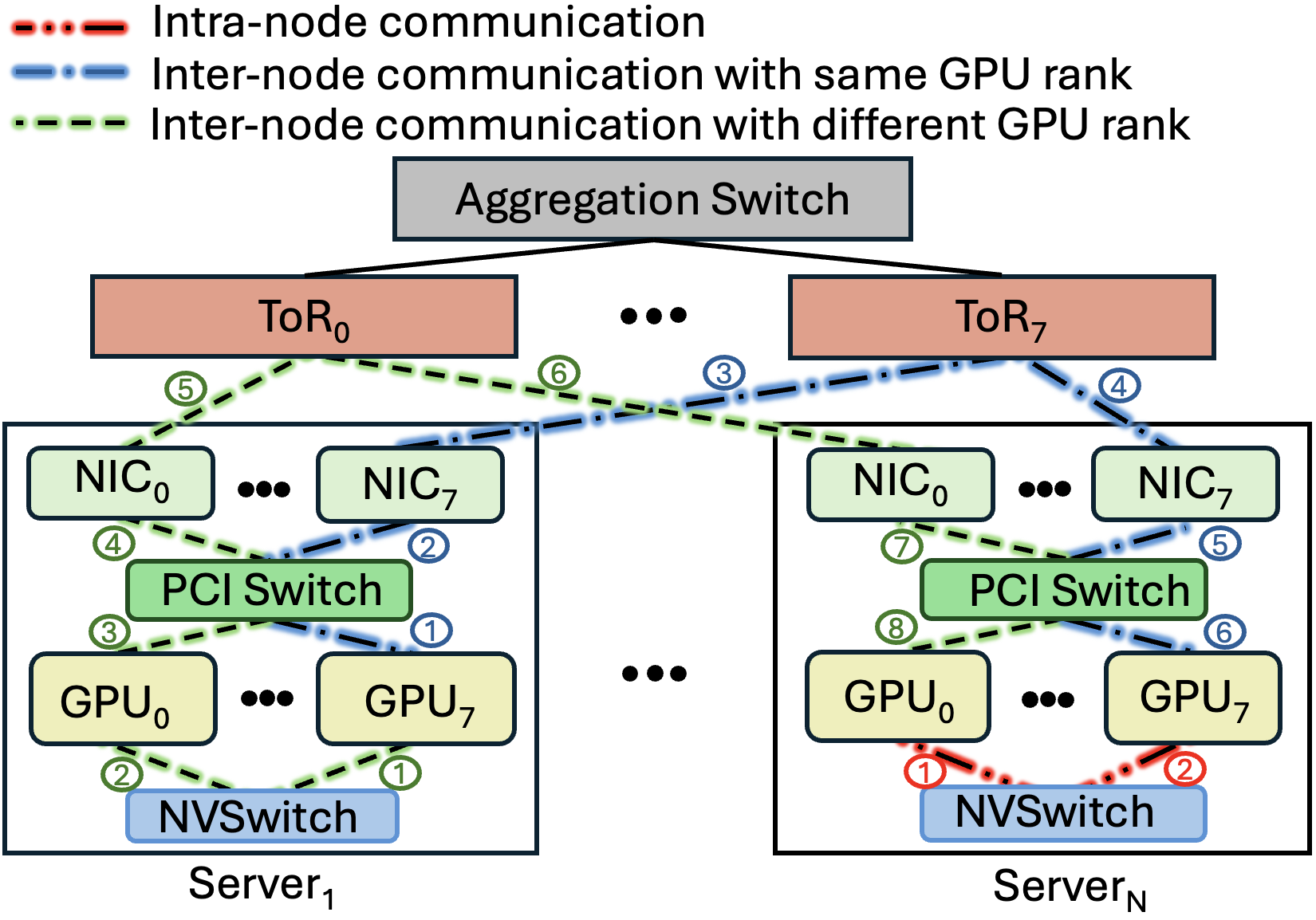
Figure 2: Rail-only topology for LLM training (intra-node and inter-node communication patterns).
Distributed LLM training utilizes hybrid schemes of Data, Pipeline, and Tensor Parallelism, with communication patterns determined by parallelism type and degree. Non-uniform device groupings (e.g., mixing H100 and A100 GPUs across nodes) introduce asymmetric communication/computation loads, impacting both efficiency and correctness. Heterogeneity-aware workload partitioning and resharding are essential to avoid synchronization stalls and shape mismatches during collective operations.
Simulator Design and Abstractions
This work extends the SimAI simulator’s architecture, introducing key abstractions:
- Custom Device Groups: User-defined mixes of GPU types for each parallelism group.
- Hybrid Parallelism: Fine-grained mapping of TP/DP/PP configurations to arbitrary device groupings.
- Topology/Network Specification: Explicit description of intra-node (PCIe/NVLink/NVSwitch) and inter-node (NIC/RDMA) connectivity, bandwidth, and latency.
Simulation layers include:
- Input Layer: Accepts granular device, parallelism, and topology configs.
- Workload Layer: Profiles per-device compute; generates heterogeneous workload traces.
- System Layer: Schedules events, manages device groups, orchestrates parameter resharding, and computes logical communication graphs.
- Network Layer: Employs ns3 module to instantiate, calibrate, and simulate interconnect delays and bandwidth, specifically accounting for device and link heterogeneity.
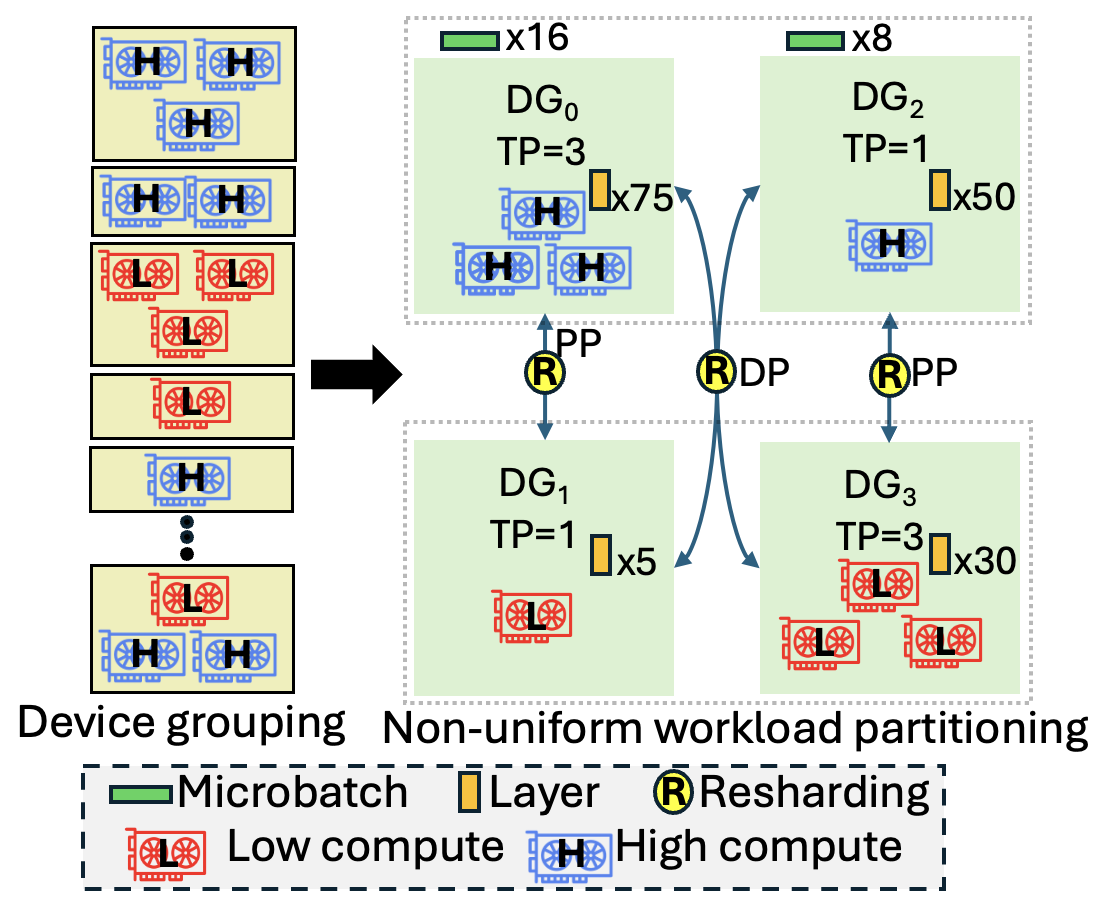
Figure 3: Example workflow of a heterogeneity-aware distributed training solution.
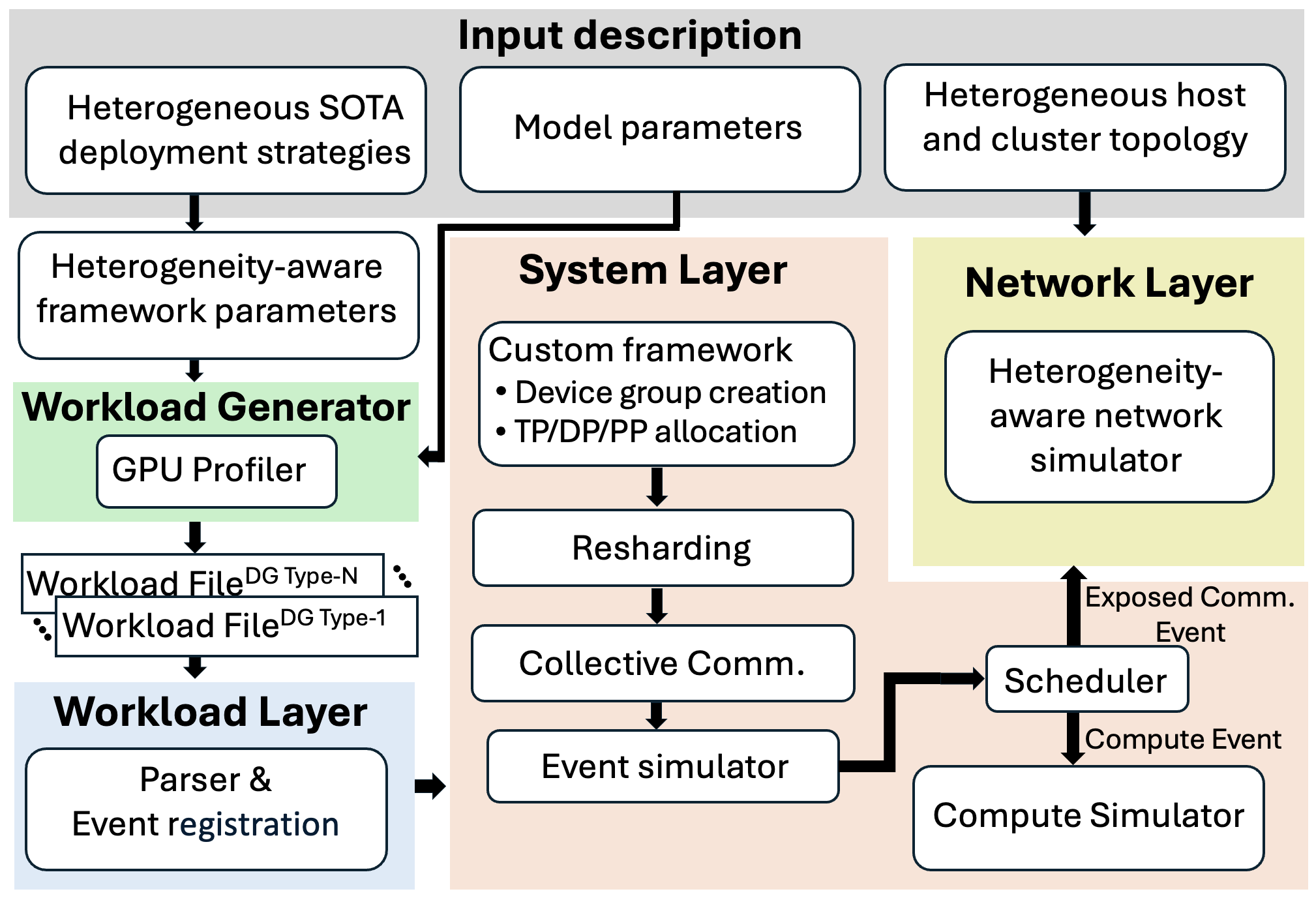
Figure 4: Design of heterogeneity-aware LLM training simulator.
Empirical Results
Compute Heterogeneity
The layer-wise compute profiling reveals pronounced degradation in MLP computation time when assigned to legacy (A100) GPUs—up to 3×–4× slower relative to H100. Attention layer computes see 1.9× slowdowns (Figure 5). Although embedding layer slowdowns are significant (36.1×), their infrequency renders optimization less critical. Strategic placement of compute-intensive layers on high-FLOPS devices maximizes throughput and highlights the necessity for heterogeneity-aware mapping during deployment.
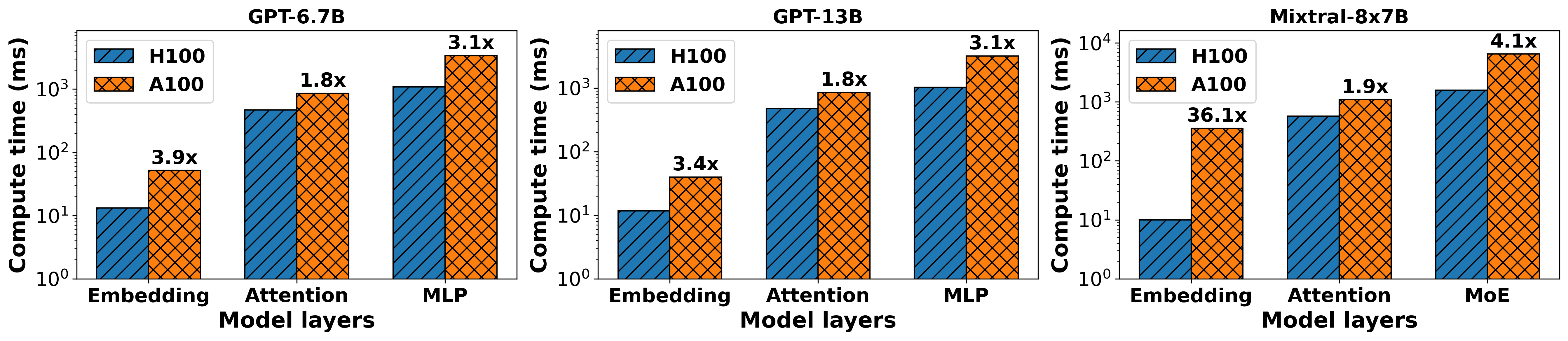
Figure 5: Per-layer compute time for GPT6.7B, GPT13B, and Mixtral-8x7B across H100 and A100 GPUs.
Interconnect Heterogeneity
Analyzing flow completion times (FCT) for AllReduce and other collective operations shows dramatic disparities across deployment configurations (Figure 6). Mixed Ampere/Hopper clusters (50%/50%) incur up to 25.3× degradation in tail FCT for GPT-13B relative to pure Ampere, with smaller but non-negligible effects for other models. As collective communication often determines iteration completion, these results emphasize the critical role of optimized device/interconnect placement and topology mapping.
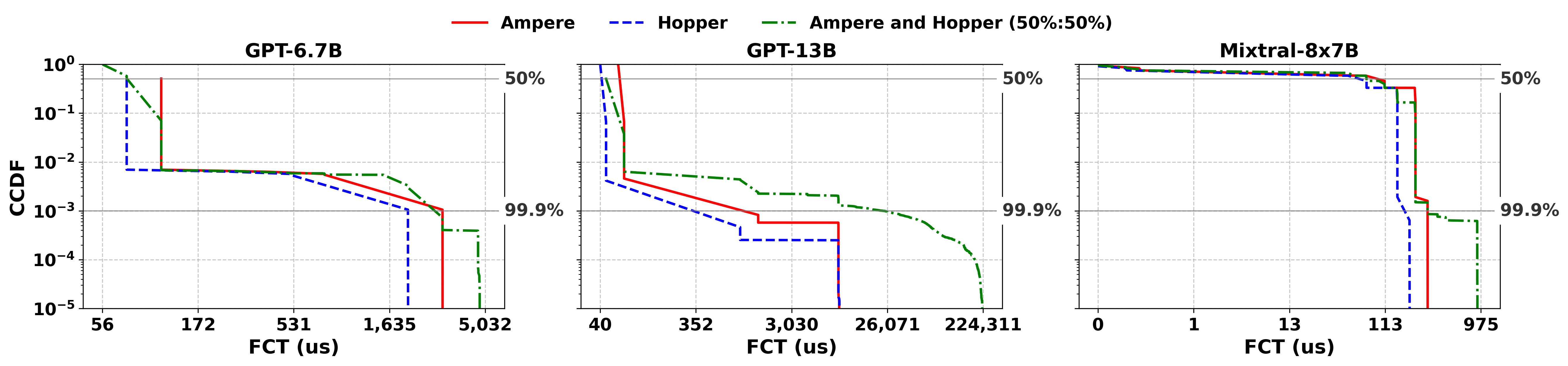
Figure 6: FCT distribution for GPT-6.7B, GPT-13B, and Mixtral-8x7B in homogeneous/heterogeneous clusters.
Practical and Theoretical Implications
The proposed simulator empowers researchers and practitioners to:
- Quantitatively model the impact of compute and network heterogeneity on distributed LLM training.
- Synthesize deployment plans that minimize synchronization stalls, maximize utilization, and reduce tail latency.
- Develop heterogeneity-aware scheduling, resharding, and parallelism strategies, advancing the state-of-the-art for cost-effective and scalable LLM infrastructure.
The approach enables precise evaluation and optimization of hybrid-parallel deployments, including model/data/tensor partitioning, resharding strategies, and topology-aware collective communication, facilitating adaptive orchestration in dynamic, multi-tenant and transitional environments.
Future Directions
Immediate extensions include expanding simulator support to inference workloads, further enhancing device and interconnect abstraction granularity, and automating optimal deployment plan synthesis. Integration of additional optimization techniques targeting computation-communication overlap, adaptive hybrid parallelism mapping, and vendor-agnostic collective communication algorithms will be essential in accommodating forthcoming architectural heterogeneity and diverse AI accelerator topologies.
Conclusion
This work fills a critical gap by designing and evaluating a heterogeneity-aware, full-stack LLM training simulator. Empirical results underscore the significant impact of heterogeneous compute and network environments on training efficiency. The proposed abstractions and framework enable robust modeling of practical deployment scenarios, providing actionable guidance for researchers and cluster operators tasked with optimizing distributed LLM training performance and resource utilization (2508.05370).