- The paper introduces a heterogeneity-aware framework that automates parallel training for deep learning on diverse GPU architectures.
- It employs a fine-grained planner, adaptive 1F1B scheduling, and zero-redundant profiling to achieve 1.3 to 1.6 times higher throughput.
- Experimental results demonstrate that HAPT scales robustly, maximizing resource utilization even in clusters with variable interconnect speeds.
HAPT: Heterogeneity-Aware Automated Parallel Training on Heterogeneous Clusters
Introduction
The increasing complexity and scale of deep learning models necessitate efficient training strategies in environments with heterogeneous hardware. The paper "HAPT: Heterogeneity-Aware Automated Parallel Training on Heterogeneous Clusters" proposes an automated parallel training framework tailored for such environments. HAPT addresses inefficiencies in existing frameworks by intelligently planning inter-operator parallel strategies and adopting a heterogeneity-aware scheduler, striving to maximize resource utilization across diverse GPU architectures.
Framework and Methodology
Fine-Grained Planner
HAPT introduces a novel planner for inter-operator parallel strategies that operate at a finer layer granularity. This planner intelligently partitions computational graphs into structural layers, leveraging the repetition within model architectures to minimize profiling overhead. By exploring this refined search space, HAPT aligns the workload more precisely with the computational capabilities of heterogeneous accelerators.
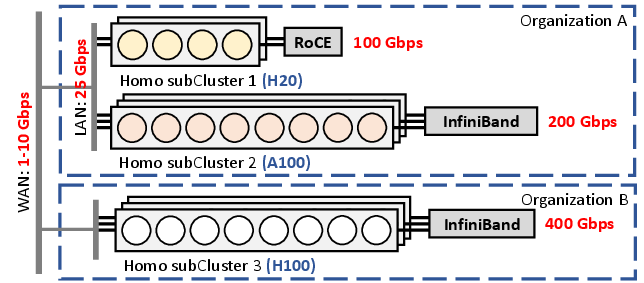
Figure 1: Example heterogeneous cluster composed of multiple homogeneous subclusters, with fast interconnects within subclusters but slower interconnects across them.
Heterogeneity-Aware Scheduling
The framework employs a heterogeneity-aware 1F1B scheduler that dynamically adjusts microbatch execution timing based on communication latencies. This scheduling strategy optimizes the overlap between computation and communication, aiming to achieve minimal memory overhead while hiding network latency effectively.
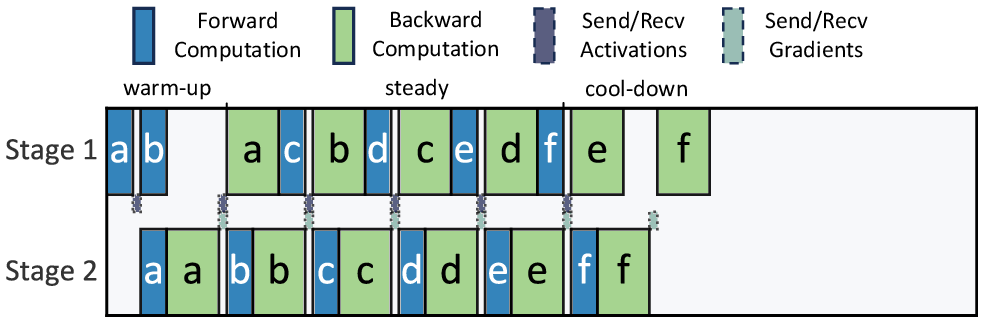
Figure 2: Classic 1F1B pipeline scheduler.
Zero-Redundant Profiling
To enhance profiling efficiency, HAPT implements a zero-redundant approach. By recognizing repeated modules within a model's computational graph, only unique configurations are profiled, significantly reducing redundant profiling computations.
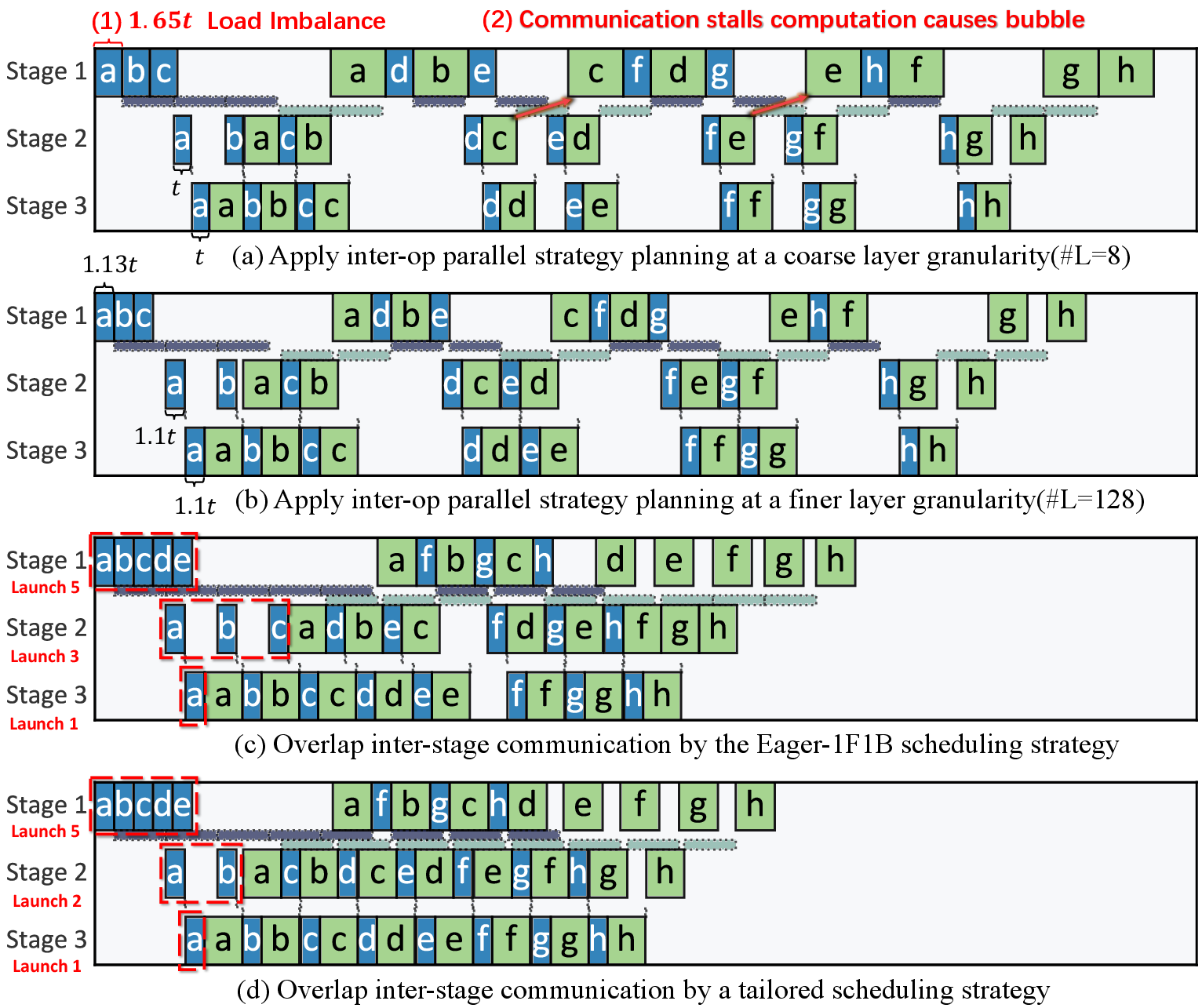
Figure 3: Pipeline timeline of case studies.
Evaluation and Results
HAPT has demonstrated substantial improvements over existing frameworks like Alpa and HexiScale, achieving 1.3 to 1.6 times higher throughput in tests across heterogeneous configurations. This performance gain is attributed to HAPT's strategic planning and efficient scheduling, which collectively harness the full potential of diverse hardware resources.
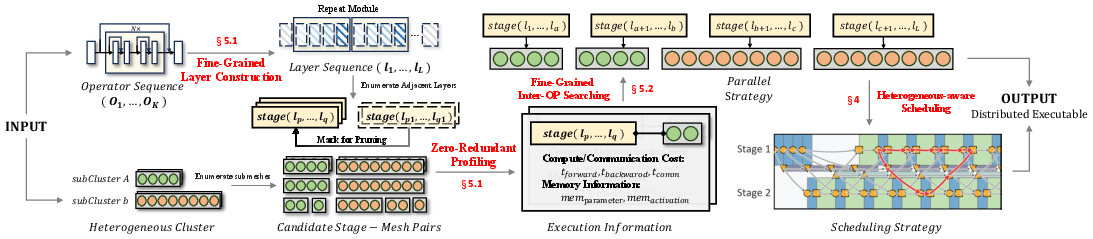
Figure 4: Overview of Hapt workflow.
Scalability and Robustness
The framework's effectiveness is particularly evident when deployed in larger clusters, maintaining robust performance even when interconnect speeds vary significantly, as shown in additional comparative studies.
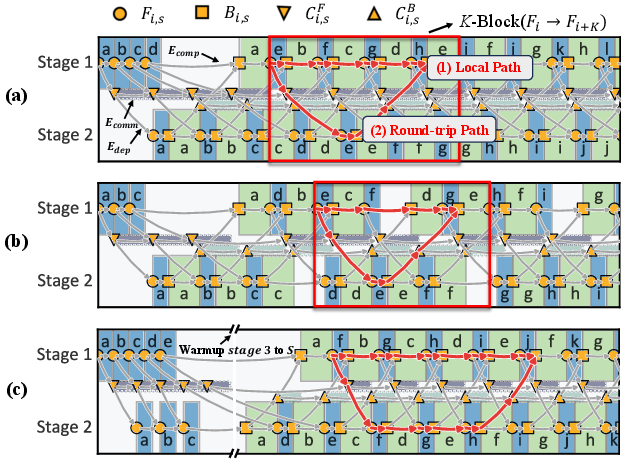
Figure 5: DAG representation of the pipeline execution. (a) Two-stage homogeneous case where the local path dominates K-block latency. (b) Two-stage homogeneous case where the round-trip path dominates K-block latency.
Implications and Future Work
The development of HAPT signifies an important step towards optimizing deep learning training in heterogeneous environments. By strategically utilizing both intra- and inter-operator parallelism, the framework offers an efficient solution to the challenges posed by hardware diversity. Future work may extend these methodologies to emerging AI models and novel accelerator architectures, further enhancing the adaptability and scalability of distributed AI training systems.
Conclusion
HAPT revolutionizes automated parallel training in heterogeneous clusters by integrating a nuanced understanding of hardware characteristics with advanced scheduling mechanisms. Through its innovative planning and scheduling algorithms, the framework not only enhances performance and load balance but also sets a new benchmark for efficiency in heterogeneous deep learning systems.