- The paper introduces HetCCL, a vendor-agnostic collective communication layer that enables transparent mixed-vendor GPU support for LLM training.
- It employs an abstracted runtime API and multi-vendor device code compilation to integrate seamlessly with existing deep learning frameworks.
- Performance evaluations show near-native throughput and up to 2.97x training speedup in heterogeneous clusters compared to single-vendor setups.
HetCCL: Accelerating LLM Training on Heterogeneous GPU Clusters
Introduction
The evolution of LLMs towards ever-growing parameter counts and higher resource demands has necessitated the formation of heterogeneous GPU clusters, comprising accelerators from multiple vendors. Conventional distributed deep learning frameworks are tightly integrated with vendor-specific collective communication libraries (CCLs), primarily NCCL for NVIDIA and RCCL for AMD, resulting in an inability to leverage mixed-vendor deployments for a single job. The "HetCCL: Accelerating LLM Training with Heterogeneous GPUs" (2601.22585) paper introduces HetCCL, a CCL designed to enable transparent and efficient collective communication across both NVIDIA and AMD GPUs without requiring modification to drivers, runtimes, compilers, or application code.
Communication Mechanisms and Design Insights
Modern distributed training architectures rely on high-throughput collective operations (All-Reduce, All-Gather, Reduce-Scatter) for synchronization and aggregation of tensors. Interconnects such as PCIe, InfiniBand (IB), and RDMA protocols are leveraged to accelerate inter-node data movement. The standard approach for inter-node GPU communication traditionally involves host-staging, incurring significant latency and bandwidth overhead.
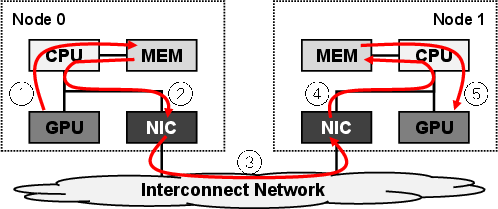
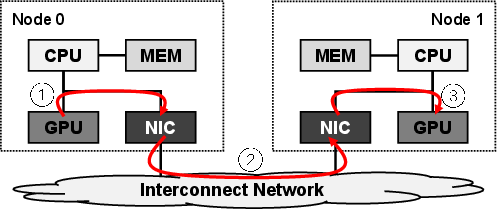
Figure 1: Host-staged communication (without RDMA) forces additional memory copies and constrains bandwidth between nodes.
HetCCL capitalizes on the capability of contemporary NICs to directly access device memory via RDMA (GPUDirect for NVIDIA, DirectGMA for AMD), abstracting away vendor-specific details at the RDMA layer. Crucially, once device buffers are registered with the NIC, the underlying RDMA stack is vendor-agnostic—no driver changes or data layout transformations are necessary.
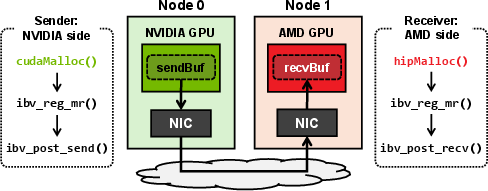
Figure 2: RDMA-enabled direct communication between heterogeneous GPUs using vendor-specific runtime allocations and IB Verbs for data transfer.
Architecture and Implementation
HetCCL decouples collective coordination from vendor-specific execution. Vendor-local collectives are executed using existing NCCL and RCCL backends, maintaining performance parity in homogeneous setups. Two principal mechanisms underpin HetCCL's architecture:
- Runtime API Abstraction: A layer (TACC) unifies CUDA (NVIDIA) and HIP (AMD) runtime APIs under a single function table, resolving platform-dependent calls dynamically.
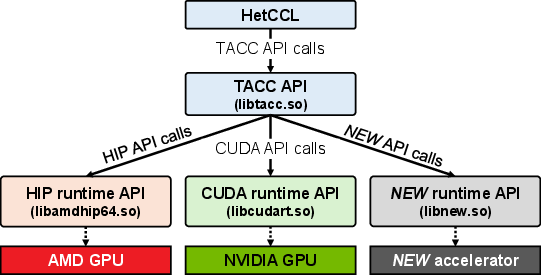
Figure 3: Abstraction layer maps platform-independent TACC APIs to vendor-specific runtime functions.
- Multi-Vendor Device Code Compilation: GPU kernels are isolated into backend-specific shared libraries, compiled independently for each platform (nvcc for CUDA, hipcc for HIP), and loaded at runtime.
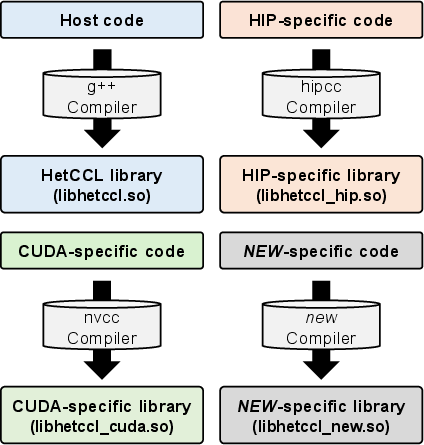
Figure 4: HetCCL’s compilation workflow produces coexisting CUDA and HIP device binaries for dispatch.
Integration into existing deep learning pipelines is achieved transparently via symbol interception, typically using LD_PRELOAD, allowing replacement of NCCL/RCCL symbols with HetCCL equivalents without code modification.
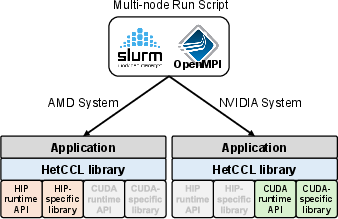
Figure 5: HetCCL deployment in a multi-node, multi-vendor GPU cluster, loading necessary backends per node.
Point-to-Point RDMA Bandwidth
HetCCL demonstrates RDMA-enabled communication that matches or surpasses vendor-optimized homogeneous baselines. In heterogeneous (NVIDIA↔AMD) configurations, communication bandwidth is bounded by the slower node but close to the maximum achievable by the fastest endpoint.
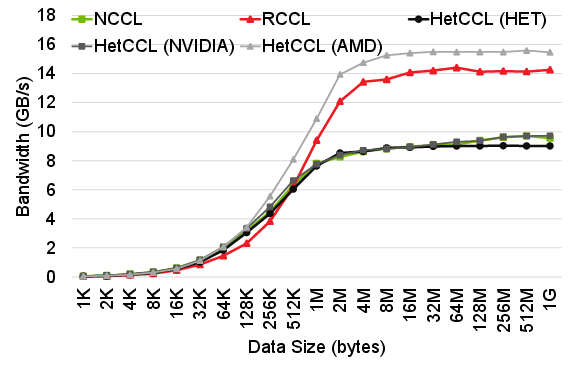
Figure 6: Comparative performance of RDMA point-to-point transfer in homogeneous and heterogeneous settings.
Collective Communication
Across representative collectives (All-Reduce, All-Gather, Reduce-Scatter), HetCCL attains near-native performance in both homogeneous and heterogeneous cluster configurations. In mixed-vendor execution, bandwidth and scaling characteristics closely follow those of the bottleneck vendor library, confirming HetCCL’s effective utilization of vendor-specific optimizations.
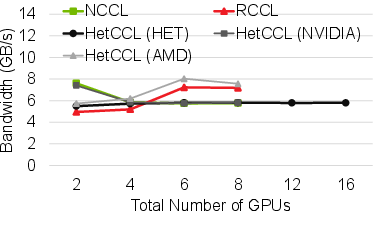
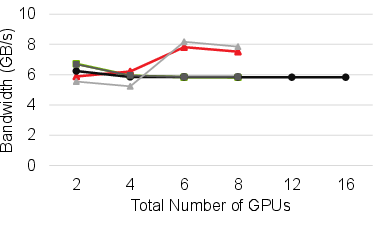
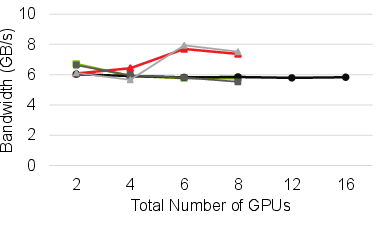
Figure 7: All-Reduce bandwidth: HetCCL scales to mixed-vendor clusters, bounded only by slowest device’s performance.
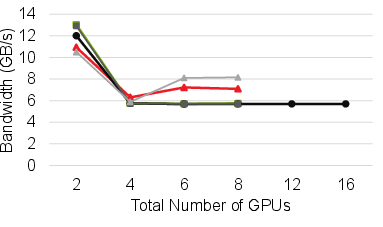
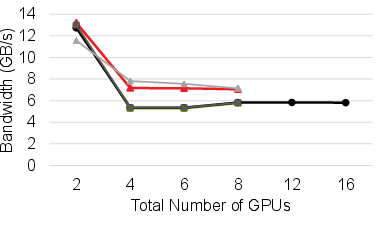

Figure 8: Reduce operation compared across NCCL, RCCL, and HetCCL in various cluster topologies.
LLM Training Throughput
End-to-end experiments with GPT and LLaMA models (up to 3B parameters) reveal that HetCCL enables linear scaling as GPU count doubles across nodes with 4/8 NVIDIA and 4/8 AMD GPUs. Mixed-vendor clusters achieve up to 2.97x speedup over single-vendor (AMD) training and 97% efficiency compared to the aggregate of homogeneous runs. Straggler effects are mitigated using throughput-proportional micro-batch assignments, determined via a short profiling phase.
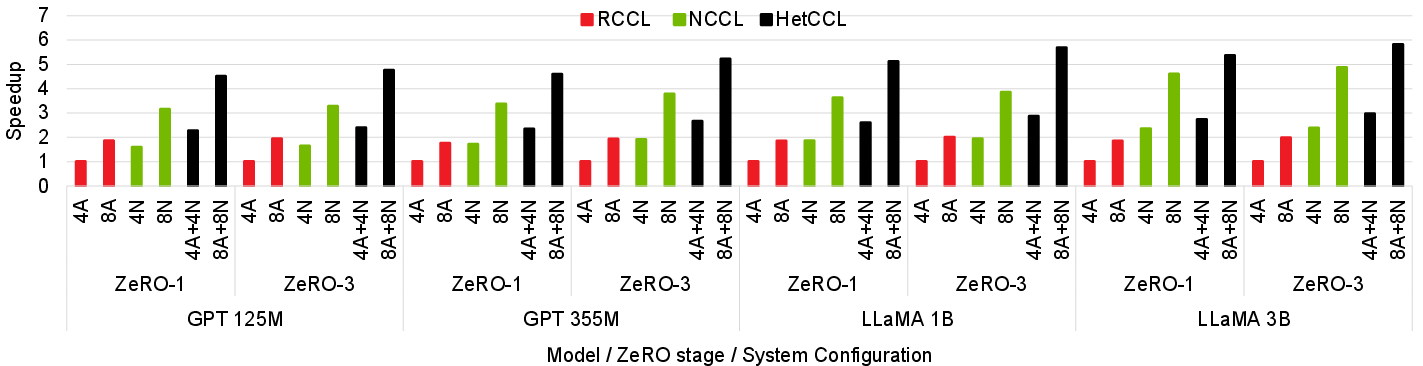
Figure 9: Training speedup for LLMs: mixed-vendor cluster using HetCCL outperforms vendor-specific baselines by aggregating heterogeneous compute.
Model Fidelity
Loss convergence experiments confirm that using HetCCL for cross-vendor training exhibits negligible divergence in loss and achieves final model states consistent with pure NCCL or RCCL runs. Relative differences in loss (<7×10−3) are below BF16 machine epsilon, ensuring numerical integrity.
Implications and Future Directions
HetCCL represents a significant extension of the feasible hardware landscape for LLM and distributed DL training. By abstracting collective communication across heterogeneous GPUs, practitioners are empowered to utilize existing hardware to full capacity, combine legacy and new accelerators, and reduce procurement/capacity planning constraints.
Practical implications include:
- Immediate drop-in scalability for clusters incrementally expanded with mixed-vendor nodes.
- Lower total training cost and GPU-hour expenditure owing to improved resource utilization.
- Feasible deployment of larger batch sizes, parallelism strategies, and model/family combinations without code changes.
Theoretical implications call for reexamination of parallelism strategies, collective scheduling, and resource-aware algorithms in settings where heterogeneity is not limited to device capabilities but extends to vendor-specific architectural and software stack nuances.
Future work must extend HetCCL beyond inter-node heterogeneity towards intra-node mixed-vendor contexts, dynamic load balancing, beyond offline profiling, and performance validation at hyper-scale (≫16 GPUs, ≥100B parameters). Integration with emerging CCLs, accelerator types (NPUs, FPGAs), and cluster schedulers will further catalyze research and practical adoption.
Conclusion
HetCCL enables, for the first time, efficient and transparent collective communication for mixed-vendor GPU clusters in distributed deep learning frameworks. Maintaining near-native performance in homogeneous cases and scaling robustly in heterogeneous environments, HetCCL unlocks hardware flexibility for large-scale LLM training without any requirement for application or driver changes. This paradigm shift in CCL design opens the door to maximal resource aggregation, efficient scheduling, and new direction in heterogeneity-aware distributed machine learning research.