- The paper introduces a heterogeneous training framework that unifies SparseLoCo with subspace pipeline compression to drastically reduce inter-node communication during LLM pre-training.
- It achieves high compute utilization—even over 97% in low-bandwidth settings—while controlling loss degradation across models ranging from 178M to 70B parameters.
- The approach flexibly integrates resource-limited nodes with high-bandwidth clusters, fostering scalable, decentralized, and democratized LLM pre-training.
Heterogeneous Low-Bandwidth Pre-Training of LLMs
Introduction and Motivation
Scalability and decentralization remain central challenges for LLM pre-training, as current practices are constrained by high communication bandwidth requirements inherent to distributed model and data parallelism. The paper "Heterogeneous Low-Bandwidth Pre-Training of LLMs" (2601.02360) addresses these challenges by proposing a heterogeneous distributed training protocol that enables scalable pre-training of LLMs using a mix of high-bandwidth and low-bandwidth resources, including resource-limited participants with ordinary networking capabilities.
The proposed framework extends SparseLoCo, a communication-efficient data-parallel training scheme that leverages infrequent model synchronization and pseudo-gradient sparsification, enabling effective use of low-bandwidth workers. The authors compose SparseLoCo with model parallelism through pipeline stage partitioning, leveraging subspace activation and gradient compression to minimize inter-stage communication overhead. The resulting system supports arbitrary mixtures of traditional datacenter clusters and Internet-connected, bandwidth-constrained participants, each contributing via the most effective communication mode available to them.
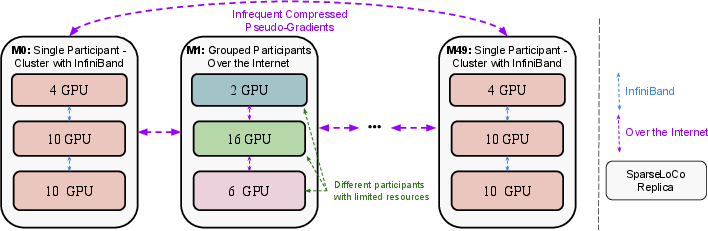
Figure 1: This schematic illustrates the heterogeneous training protocol, in which high-bandwidth clusters host full replicas, and resource-limited participants collaborate via pipeline parallelism and compressed inter-stage communication. SparseLoCo enables efficient synchronization and aggregation across all groups.
Method: Heterogeneous SparseLoCo with Pipeline Compression
The methodological centerpiece is the unification of two communication-efficient strategies: SparseLoCo for data-parallel replica synchronization, and Subspace Networks' activation/gradient compression for pipeline parallelism within model replicas formed by bandwidth-limited groups. SparseLoCo uses local updates for H steps on each replica, then synchronizes model parameters by (i) transmitting only the top-k pseudo-gradient elements per chunk (sparsification), and (ii) employing error feedback memory to prevent optimization drift.
Within resource-limited groups forming a pipeline-parallel replica, inter-stage activations and their corresponding gradients are projected into a k-dimensional subspace (k≪d), using an orthonormal basis shared among pipeline stages. This yields strong reductions in cross-stage communication, with the tradeoff governed by the compression ratio k/d. Notably, the framework supports heterogeneous configurations in which some replicas (e.g., high-speed datacenter clusters) operate without subspace projection to avoid accuracy loss, while others (e.g., Internet-linked nodes) use aggressive compression to meet bandwidth constraints.
Specialized care is given to token embedding synchronization across these heterogeneous replicas, with projection and error accumulation steps ensuring embedding consistency and minimizing bias introduced by the mixed communication strategies.
Experimental Evaluation
The authors present a comprehensive experimental suite on transformer models spanning 178M, 512M, and 1B parameters, benchmarked against large-scale pretraining corpora (DCLM, C4). The results validate that combining SparseLoCo and subspace pipeline compression yields minimal degradation in final loss (e.g., <4% at 87.5% compression for a 512M model) relative to uncompressed SparseLoCo, while enabling high compute utilization under tight bandwidth caps.
Evaluation on 70B models demonstrates that subspace compression enables greater than 97% compute utilization at 1Gbps pipeline bandwidth and remains practical down to 100Mbps without bottlenecking training, whereas conventional pipeline parallelism would fail in these settings.
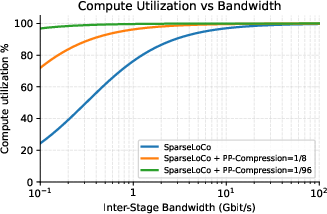
Figure 2: Compute utilization as a function of inter-stage bandwidth, confirming that subspace-based pipeline compression achieves near-optimal utilization even in low-bandwidth regimes for large models.
Crucially, heterogeneous configurations, where only bandwidth-constrained replicas use subspace compression, consistently outperform uniform compression, particularly at high compression rates. For instance, at 99.9% compression (i.e., k/d=1/768), the heterogeneous approach reduces the relative final loss degradation from 12.4% to 9.8% for a 512M parameter model, demonstrating the advantage of mixing compressed and uncompressed groups under SparseLoCo synchronization. Extending token budgets recovers most residual loss, confirming that the increased throughput afforded by higher compute utilization directly enables recovery of baseline performance via additional training.
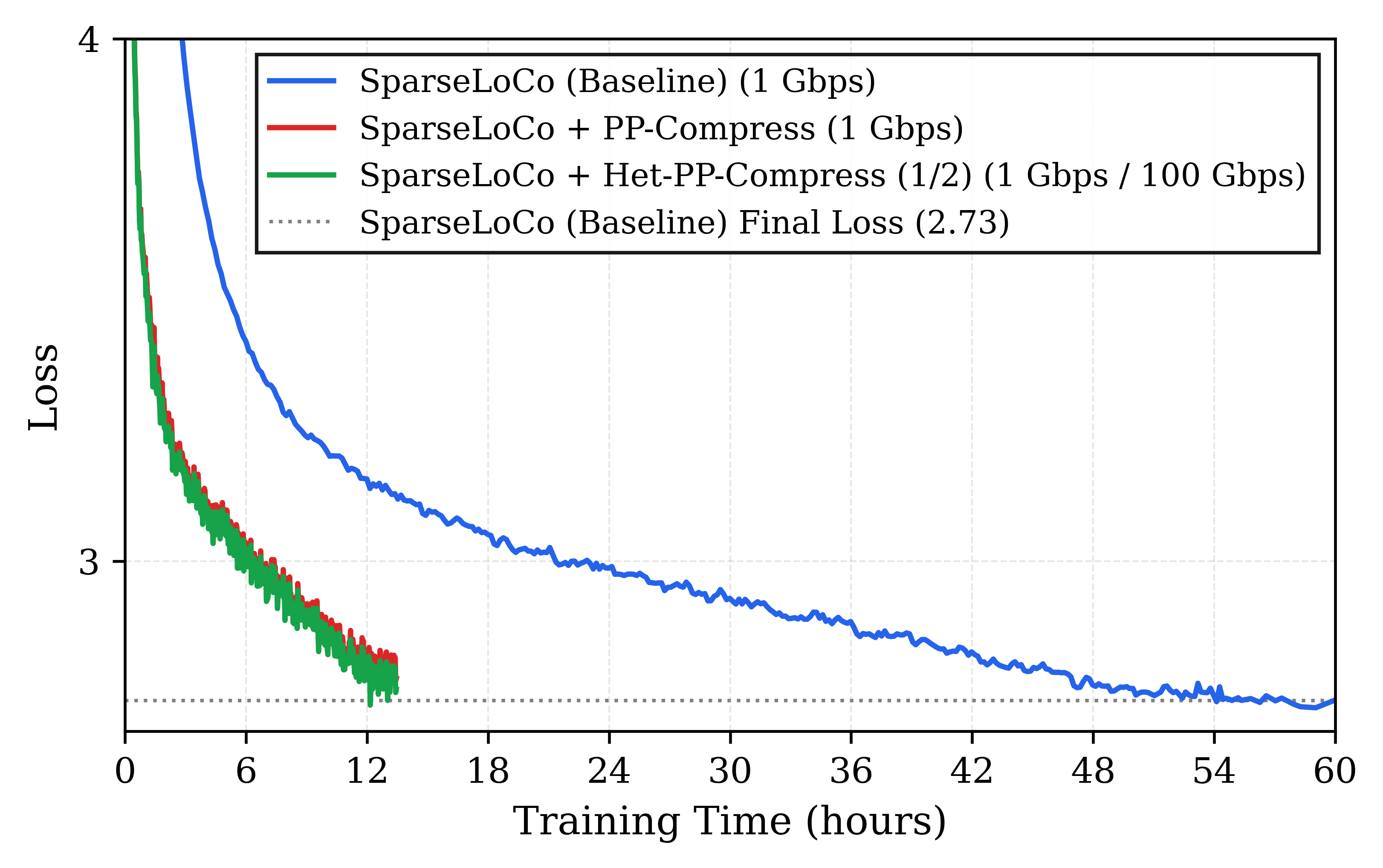
Figure 3: Final loss for 512M parameter models under increased token budgets and compressed training, demonstrating the effectiveness of additional training iterations in closing accuracy gaps introduced by higher compression.
Ablations highlight the importance of token-embedding adaptation in heterogeneous settings and demonstrate that dynamic subspace adaptation and weight projection are superfluous for SparseLoCo-based training. A further comparison with traditional AdamW-based homogeneous data parallelism shows that the heterogeneous advantage is unique to SparseLoCo's multi-step local optimization and error feedback; with AdamW, introducing heterogeneity is detrimental.
Theoretical and Practical Implications
Theoretical: The results indicate that aggregation bias from subspace compression can be partially cancelled by including uncompressed replicas during synchronization, with the degree of correction proportional to the fraction of uncompressed workers. The bias amplification effect is tied to the number of local updates between synchronizations (H) and the compression aggressiveness, establishing a direct theoretical rationale for the benefits of heterogeneity in the replica set.
Practical: These findings open the door to scalable global LLM pre-training, leveraging a hybrid pool of computational nodes including both high-performance clusters and opportunistically available, bandwidth-limited hardware. The flexibility in replica construction aligns well with federated and decentralized AI paradigms and could democratize LLM training participation. It also provides a means to utilize surplus or opportunistic compute where interconnects would otherwise be prohibitive.
Furthermore, the composability of these strategies with additional inner-optimization speedups or orthogonal communication-efficient protocols (quantization, further sparsification, adaptive learning rates) is straightforward, enabling layered enhancements for diverse hardware environments.
Conclusion
The paper establishes a principled and practical framework for the heterogeneous, low-bandwidth pre-training of LLMs, marrying SparseLoCo's local-update/gradient-sparsification strategy with efficient pipeline compression for model-parallel groups. The proposed approach empirically maintains strong training efficiency and minimal accuracy degradation under challenging bandwidth conditions, while its theoretical underpinnings clarify the source of the heterogeneous advantage. The framework's adaptability to global, open-participation settings positions it as a viable path forward for scalable, democratic large model pre-training in both current and future AI infrastructures.