- The paper introduces two curated datasets, TextbookReasoning with 650k questions and MegaScience with 1.25M instances, that advance scientific reasoning in LLMs.
- Using dual extraction and advanced LLM decontamination techniques, the methodology ensures high-quality, diverse, and unique Q-A pairs from complex textbook content.
- Evaluation with models like Llama3.1 and Qwen2.5 demonstrates superior metrics and effective trade-offs between performance and inference efficiency.
MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning
Introduction
The development of post-training datasets for scientific reasoning has been relatively underexplored, especially when compared to areas like mathematics and coding. The "MegaScience" paper addresses this gap by introducing two significant datasets: TextbookReasoning and MegaScience. These datasets are designed to enhance scientific reasoning by providing high-quality data extracted from university-level textbooks and curated through rigorous methodologies.
TextbookReasoning Data Curation
TextbookReasoning comprises 650k reasoning questions extracted from approximately 12k university-level textbooks across seven scientific disciplines, including physics, chemistry, and medicine. The data curation pipeline involves several sophisticated steps:
- Textbooks Collection and Digitization: The raw material comprises PDF documents converted into machinable text formats.
- Dual Q-A Pairs Extraction: Utilizing a high-standard and low-standard extraction method ensures a comprehensive mining of complete Q-A pairs from the text, enabling the capture of complex questions at varying difficulty levels.
- Deduplication and Refinement: Locality-sensitive hashing techniques and advanced LLM-based methods refine and deduplicate the data, ensuring uniqueness and quality.
- LLM-based Decontamination: To ensure the integrity of benchmark evaluations, extensive decontamination is performed to eliminate any overlap with existing benchmarks using LLM-based checks for semantic similarity.

Figure 1: The pipeline of TextbookReasoning data curation.
MegaScience Data Curation
MegaScience is a large-scale mix of open-source datasets, totaling 1.25 million instances. Unlike conventional methods, MegaScience employs strategic data selection and rigorous benchmarking to produce a high-quality dataset. It includes instances chosen through length-based response selection and difficulty-aware selection methods:
- Data Selection and Annotation: To maintain high quality, only the most challenging and informative instances are selected from publicly available datasets, supplemented with detailed step-by-step solutions where applicable.
- Scaling and Benchmarking: A comprehensive evaluation framework covering diverse benchmarks and question types ensures robust assessment and scalability of the datasets.
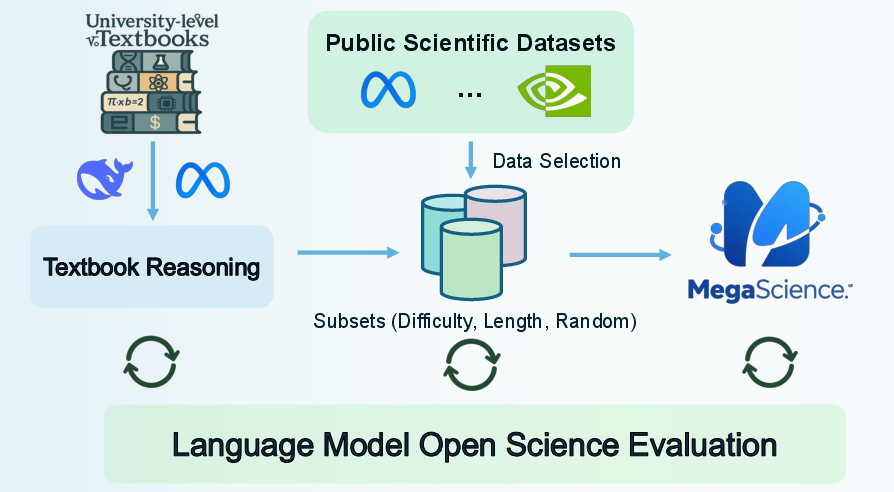
Figure 2: The overall of MegaScience datasets.
Supervised Finetuning and Evaluation
The efficacy of the datasets is demonstrated through supervised fine-tuning experiments on various LLM series, such as Llama3.1 and Qwen2.5. The results indicate that models trained on MegaScience outperform their instruction-tuned counterparts, particularly evident in larger and stronger models.
- Performance Metrics: MegaScience showed enhanced performance by achieving superior metrics on both general and specific reasoning tasks, highlighting its potential to push the frontier in scientific reasoning.
- Trade-off Analysis: The analysis highlights the trade-off between model performance and inference efficiency, demonstrating that MegaScience facilitates concise yet effective training responses, thereby improving both efficiency and performance.
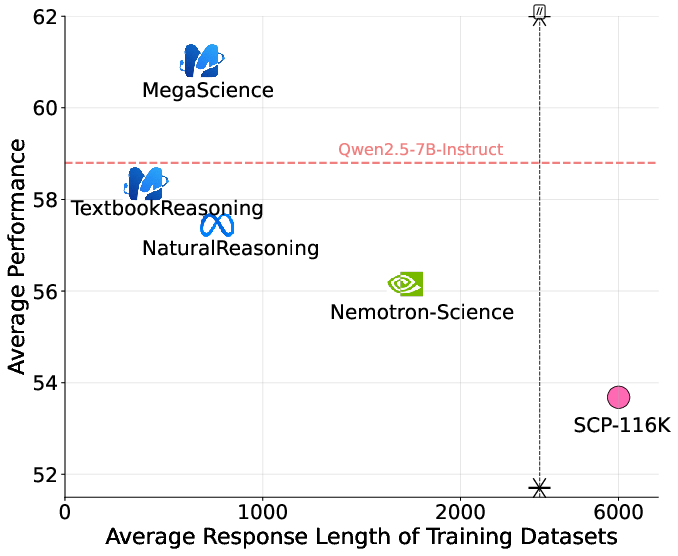
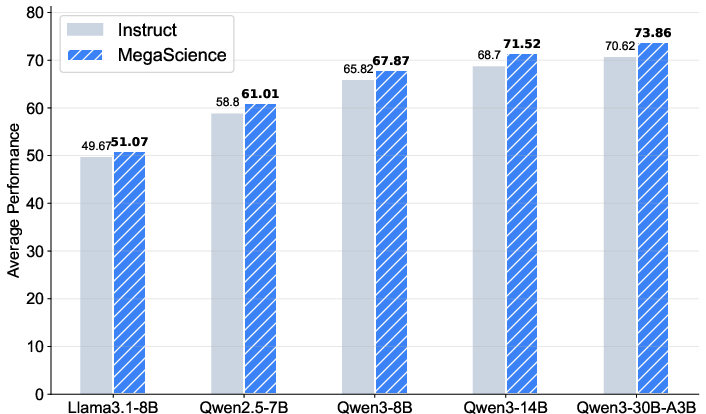
Figure 3: Trade-off between model performance and inference efficiency (average response length) on Qwen2.5-7B.
Implications and Future Work
The results suggest that carefully curated datasets like MegaScience can significantly advance scientific reasoning capabilities in LLMs. Potential future directions include leveraging reinforcement learning (RL) to further enhance these reasoning capabilities and exploring the benefits of mid-training stages in RL environments.
Conclusion
"MegaScience" significantly contributes to the field by providing high-quality, scalable datasets that enhance scientific reasoning through strategic data curation and rigorous evaluation. The release of their pipeline, datasets, and models aims to aid the community in advancing scientific reasoning research, opening avenues for innovations in AI-driven scientific discovery and learning.