SciQAG: A Framework for Auto-Generated Science Question Answering Dataset with Fine-grained Evaluation
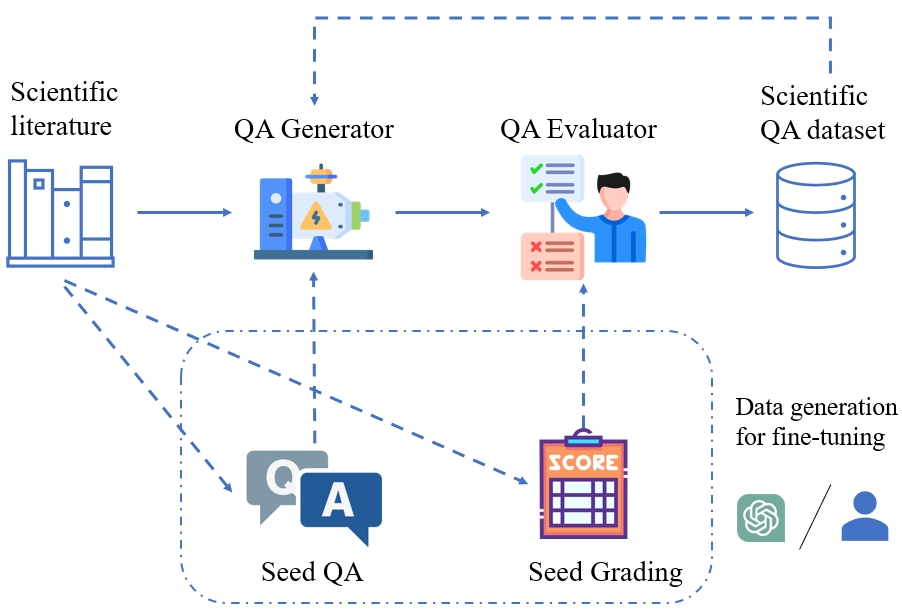
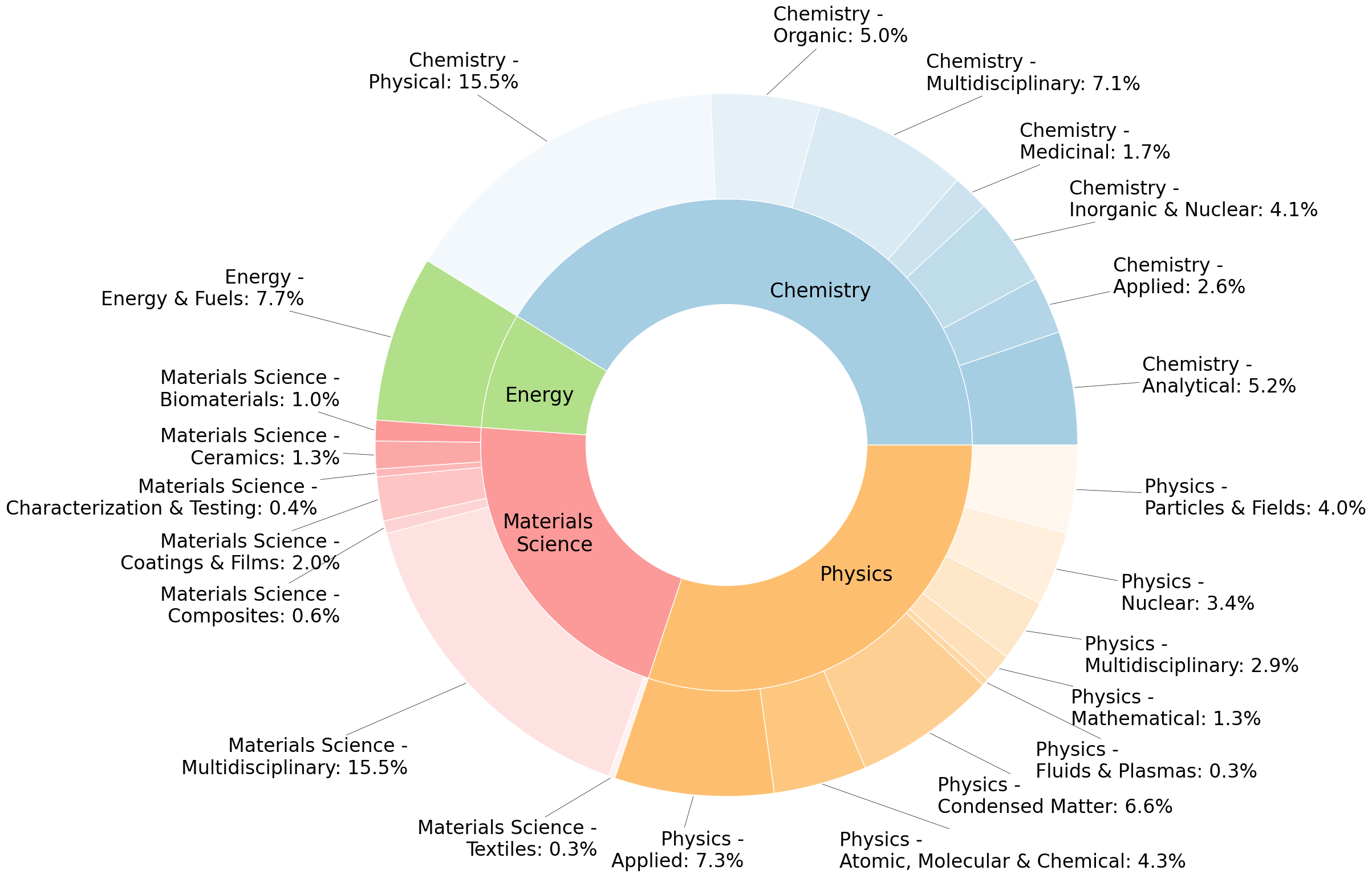
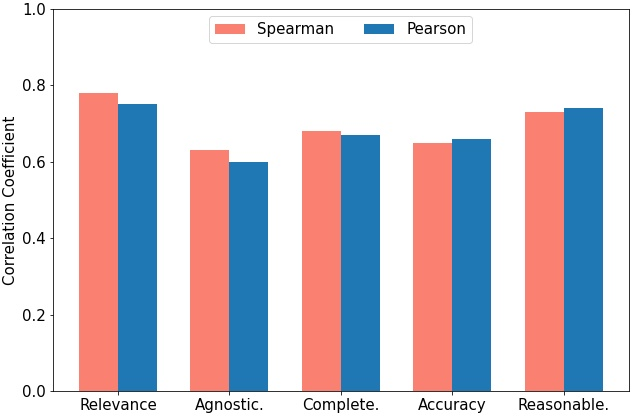
Abstract: We introduce SciQAG, a novel framework for automatically generating high-quality science question-answer pairs from a large corpus of scientific literature based on LLMs. SciQAG consists of a QA generator and a QA evaluator, which work together to extract diverse and research-level questions and answers from scientific papers. Utilizing this framework, we construct a large-scale, high-quality, open-ended science QA dataset containing 188,042 QA pairs extracted from 22,743 scientific papers across 24 scientific domains. We also introduce SciQAG-24D, a new benchmark task designed to evaluate the science question-answering ability of LLMs. Extensive experiments demonstrate that fine-tuning LLMs on the SciQAG dataset significantly improves their performance on both open-ended question answering and scientific tasks. To foster research and collaboration, we make the datasets, models, and evaluation codes publicly available, contributing to the advancement of science question answering and developing more interpretable and reasoning-capable AI systems.
- Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan. Association for Computational Linguistics.
- Florian Boudin. 2016. pke: An open source Python-based keyphrase extraction toolkit. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: System Demonstrations, pages 69–73, Osaka, Japan.
- TopicRank: Graph-based topic ranking for keyphrase extraction. In International joint conference on natural language processing (IJCNLP), pages 543–551.
- Evaluating question answering evaluation. In Proceedings of the 2nd Workshop on Machine Reading for Question Answering, pages 119–124, Hong Kong, China. Association for Computational Linguistics.
- LongLoRA: Efficient fine-tuning of long-context large language models.
- PaLM: Scaling language modeling with pathways.
- Sentence mover’s similarity: Automatic evaluation for multi-sentence texts. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2748–2760, Florence, Italy. Association for Computational Linguistics.
- Tri Dao. 2023. FlashAttention-2: Faster attention with better parallelism and work partitioning.
- Automatic question generation and answer assessment: A survey. Research and Practice in Technology Enhanced Learning, 16(1):1–15.
- A dataset of information-seeking questions and answers anchored in research papers. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4599–4610, Online. Association for Computational Linguistics.
- Towards wafer-size graphene layers by atmospheric pressure graphitization of silicon carbide. Nature Materials, 8(3):203–207.
- Mol-Instructions – A large-scale biomolecular instruction dataset for large language models. In 12th International Conference on Learning Representations.
- Alloys of platinum and early transition metals as oxygen reduction electrocatalysts. Nature Chemistry, 1(7):552–556.
- Mixtral of experts.
- What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14).
- PubMedQA: A dataset for biomedical research question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567–2577, Hong Kong, China. Association for Computational Linguistics.
- Biomedical question answering: A survey of methods and datasets. In Fourth International Conference On Intelligent Computing in Data Sciences (ICDS), pages 1–8.
- Evaluating open-domain question answering in the era of large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5591–5606, Toronto, Canada. Association for Computational Linguistics.
- LIQUID: A framework for list question answering dataset generation. arXiv preprint arXiv:2302.01691.
- QASA: Advanced question answering on scientific articles. In Proceedings of the 40th International Conference on Machine Learning.
- How long can open-source LLMs truly promise on context length?
- Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Processing Systems.
- Can a suit of armor conduct electricity? A new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, Brussels, Belgium. Association for Computational Linguistics.
- FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, Singapore. Association for Computational Linguistics.
- Nikahat Mulla and Prachi Gharpure. 2023. Automatic question generation: A review of methodologies, datasets, evaluation metrics, and applications. Progress in Artificial Intelligence, 12(1):1–32.
- GPT-4 technical report.
- Information retrieval and question answering: A case study on COVID-19 scientific literature. Knowledge-Based Systems, 240:108072.
- Hariom A. Pandya and Brijesh S. Bhatt. 2021. Question answering survey: Directions, challenges, datasets, evaluation matrices.
- Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- MAUVE: Measuring the gap between neural text and human text using divergence frontiers. In Advances in Neural Information Processing Systems.
- SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
- DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506.
- Evaluating LLMs on document-based QA: Exact answer selection and numerical extraction using cogtale dataset.
- Data augmentation for intent classification with off-the-shelf large language models. In Proceedings of the 4th Workshop on NLP for Conversational AI, pages 47–57, Dublin, Ireland. Association for Computational Linguistics.
- ScienceQA: A novel resource for question answering on scholarly articles. International Journal on Digital Libraries, 23(3):289–301.
- HoneyBee: Progressive instruction finetuning of large language models for materials science. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5724–5739, Singapore. Association for Computational Linguistics.
- Not all metrics are guilty: Improving NLG evaluation with LLM paraphrasing.
- Llama 2: Open foundation and fine-tuned chat models.
- Automatic question answer generation using T5 and NLP. In International Conference on Sustainable Computing and Smart Systems, pages 1667–1673.
- Improving text embeddings with large language models.
- Self-Instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560.
- Self-Instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, Toronto, Canada. Association for Computational Linguistics.
- Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc.
- Crowdsourcing multiple choice science questions. In Proceedings of the 3rd Workshop on Noisy User-generated Text, pages 94–106, Copenhagen, Denmark. Association for Computational Linguistics.
- LLM-powered data augmentation for enhanced cross-lingual performance. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 671–686, Singapore. Association for Computational Linguistics.
- DARWIN series: Domain specific large language models for natural science.
- GPT3Mix: Leveraging large-scale language models for text augmentation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 2225–2239, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- BERTScore: Evaluating text generation with BERT. In International Conference on Learning Representations.
- Judging LLM-as-a-judge with MT-bench and Chatbot Arena. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

