- The paper introduces MatVQA, a benchmark that evaluates multimodal reasoning in materials science through an automated pipeline.
- The paper demonstrates that current MLLMs underperform, with the best model achieving only 51.9%, underscoring significant challenges in visual-scientific reasoning.
- The paper’s ablation studies reveal that language and caption shortcut removals lead to substantial accuracy drops, emphasizing the need for deeper reasoning capabilities.
MatVQA: A New Benchmark for Visual-Scientific Reasoning in Materials Science
The paper "Seeing Beyond Words: MatVQA for Challenging Visual-Scientific Reasoning in Materials Science" (2505.18319) introduces MatVQA, a novel benchmark designed to evaluate multimodal reasoning capabilities of MLLMs in materials science. The benchmark addresses limitations in existing datasets like MaScQA (Sawada, 2024) and SciQA (Suzuki, 2023), which primarily focus on text-based question answering and neglect the visual complexity inherent in materials research. MatVQA distinguishes itself by focusing on complex, multi-step reasoning grounded in scientific principles and demanding fine-grained visual perception of material imagery.
Construction of the MatVQA Dataset
The MatVQA dataset comprises 1325 questions generated through an automated pipeline called MArxivAgent. This pipeline leverages recent materials science literature from arXiv and employs an iterative process to eliminate textual shortcuts, ensuring that MLLMs must perform detailed visual analysis. A random 20\% of the generated MCQs are vetted by domain experts to ensure quality. The questions are categorized into four structure-property-performance (SPP) reasoning tasks: Quantitative SPP, Comparative SPP, Causal SPP, and Hypothetical variation. These tasks are designed to mirror the types of questions materials scientists encounter when characterizing, designing, and optimizing materials.
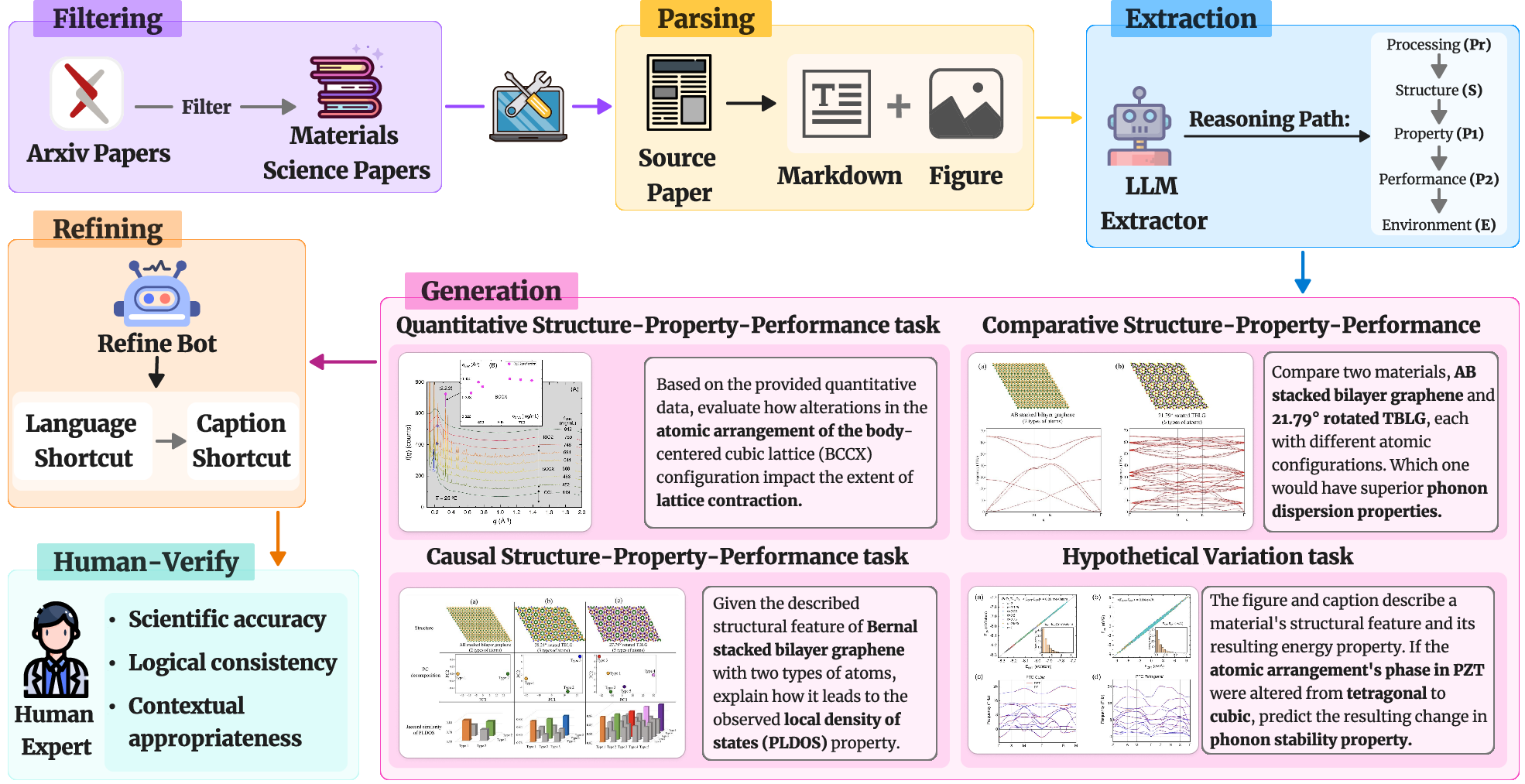
Figure 1: Construction Pipeline of MatVQA.
The MArxivAgent pipeline consists of three main stages: (i) extraction of reasoning paths from scientific literature, (ii) iterative removal of language shortcuts, and (iii) subsequent removal of caption shortcuts. The language and caption shortcut removal steps are critical for ensuring that the questions require genuine visual reasoning rather than relying on superficial textual cues. This is achieved by an iterative process where an evaluator agent attempts to answer the MCQ using only the stem and options, or the stem, options, and caption without the image. Success in either mode triggers a rewriter that removes or rephrases the incriminating text, while a consistency checker ensures fidelity to the original scientific claim.
MArxivAgent Pipeline
The MArxivAgent pipeline (Figure 2) automates the generation of challenging multiple-choice questions (MCQs) from arXiv materials science papers. The pipeline first extracts figures and captions using Marker from a corpus of 500 materials science articles published in 2024. It then harvests the surrounding textual context for each figure. To generate questions that probe complex reasoning over scientific figures, MArxivAgent derives the most comprehensive reasoning chain from the provided caption and its surrounding context. This chain is structured around five core componentsâStructure (S), Property (P), Performance (Pe), Processing (Pr), and Environment (E)âwith an emphasis on modeling their interrelationships. The MatOnto ontology is used to ensure consistent identification of these elements. To ensure the extracted reasoning chains align with the paper, the confidence of each reasoning step is verified by further retrieving the evidence in the original paper text, which makes the generated reasoning chain verifiable.
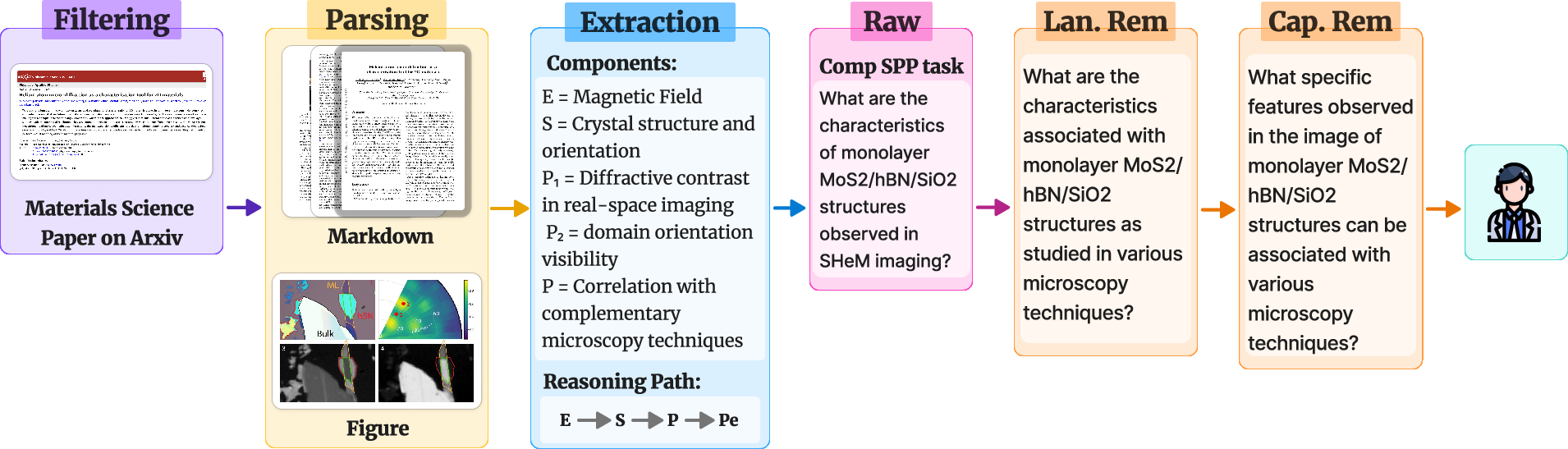
Figure 2: MArxivAgent Pipeline for MCQ automatically Generation. "Lan. Rem" represents the question after langauge shortcut removal. "Cap. Rem" represents the question after removing caption.
Given a figure, its caption, and the verified reasoning path, the agent generates task-specific questionsâcausal, hypothetical, comparative, or quantitativeâand rewrites them in MCQ format. The two-stage refinement process (summarized in Algorithm 1 in the paper) then removes language and caption shortcuts. The language shortcut removal follows the method in MicroVQA (Burgess et al., 17 Mar 2025) to increase MCQ complexity. The rewriter agent revises the original question and distractors to invalidate the language strategies. An LLM checker is applied to ensure semantic equivalence with the original pair, avoiding significant changes to the revised question-answering pairs.

Figure 3: Evolution of a sample question through the two-stage shortcut removal process. The figure shows the transformation from: the initial 'Raw Sample,' to after 'Language Shortcut removal', and finally to after 'Caption Shortcut removal'.
Benchmarking Results and Analysis
The authors evaluated 17 open- and closed-source MLLMs on MatVQA, comparing their performance against human experts and vision-LLM baselines. The results revealed substantial gaps in current multimodal reasoning capabilities. The highest overall performance was achieved by Claude-3.7-Sonnet at 51.9%. The domain-specific model MOL-VL-7B showed the lowest overall performance across all categories at 23.6%, possibly because it is finetuned for optical chemical structure understanding which biases the output for the MatVQA data. The uniformly low accuracy proves that MatVQA is challenging for both LLMs and small LLMs.
Performance varied significantly across the four SPP tasks. The models generally performed better on Causal SPP questions and worse on Hypothetical Variation questions. This suggests that MLLMs still struggle with tasks requiring counterfactual reasoning and the ability to predict the outcomes of untested structural modifications.
Ablation studies demonstrated that both language and caption refinement stages significantly reduce model accuracy, compelling a deeper level of reasoning. Language shortcut removal decreases accuracy by approximately 12% on average. Caption shortcut removal instigates a more substantial performance decline, with an additional average accuracy drop of approximately 19% from language removal.

Figure 4: Representative Examples for varies material science domain.
Error analysis revealed three primary error types: Visual Perception Error, Material Knowledge Misunderstanding, and Reasoning Wrong Judgement. Visual Perception Errors occur when the model extracts incorrect information from the figure itself. Material Knowledge Misunderstanding arises when the model's reasoning is based on a faulty scientific premise. Reasoning Wrong Judgement occurs when the model's logic falters even after perceiving the data correctly.

Figure 5: Error sample for Material Knowledge Misunderstanding error type, the response missed catalytic know-howânamely the Sabatier optimum and the distinction between Feâsupport binding vs. NH3.

Figure 6: Error sample for Reasoning-Wrong-Judgement error type. In this example, optical control schemes exploit those extra SOC-enabled orbital channels; the richer the texture, the more knobs you have. Therefore the figure is telling us that ferromagnetic fcc Ni, with its unique textural signature, offers superior optical-manipulation capability compared with the non-relativistic case. The respondent saw the figure correctly (they talked about peaks and SOC). They knew material concepts (spin-orbit coupling, ferromagnetism). The failure happened in the decision step: they judged âpeak shapeâ to be the decisive cue and ignored the more salient texture/colour contrast that the question emphasised.
Conclusion
MatVQA represents a valuable contribution to the field by providing a challenging and relevant benchmark for evaluating MLLMs in materials science. The automated MArxivAgent pipeline ensures scalability and adaptability, with the potential for application across diverse scientific fields. Future work includes expanding MatVQA to approximately 12,000 questions and extending it to areas like 3D crystal structures. This will be crucial for advancing MLLMs that can truly understand and reason about visually rich scientific data, thereby fostering their meaningful contribution to materials research.