- The paper introduces MMSciBench, a benchmark evaluating LLMs and LVLMs on Chinese multimodal math and physics tasks using both multiple-choice and open-ended formats.
- It employs a hierarchical taxonomy with human-annotated difficulty levels to rigorously assess performance in text-only versus text-image modalities.
- Experiments show state-of-the-art models achieving up to 63.77% accuracy, highlighting significant room for improvement in visual and complex scientific reasoning.
MMSciBench: Benchmarking LLMs on Chinese Multimodal Scientific Problems
Introduction
"MMSciBench: Benchmarking LLMs on Chinese Multimodal Scientific Problems" introduces the MMSciBench benchmark to assess LLMs' (LLMs) and vision-LLMs' (LVLMs) capabilities in mathematical and physical reasoning within multimodal settings. This text-image benchmark is intended to fill gaps in current scientific evaluation practices, offering difficulty levels and a structured taxonomy of problems.
MMSciBench Overview
MMSciBench provides a comprehensive evaluation framework combining multiple-choice questions (MCQs) and open-ended question-answer pairs (Q{content}A) for math and physics. It includes text-only and text-image formats, allowing the direct comparison of models on unimodal versus multimodal tasks.
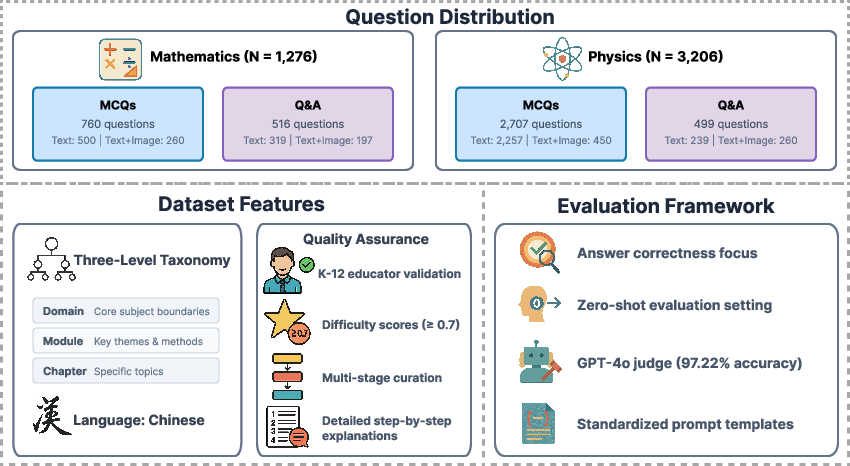
Figure 1: The overview of MMSciBench, describing the question distribution, dataset features, and the evaluation framework.
In addition to the extensive dataset collection process which ensures quality and rigor, this benchmark is paired with a hierarchical taxonomy categorizing scientific concepts into Domain, Module, and Chapter. The multimodal nature of the dataset is designed to enable a rigorous evaluation of models' scientific reasoning, with human-annotated difficulty levels guiding this evaluation.
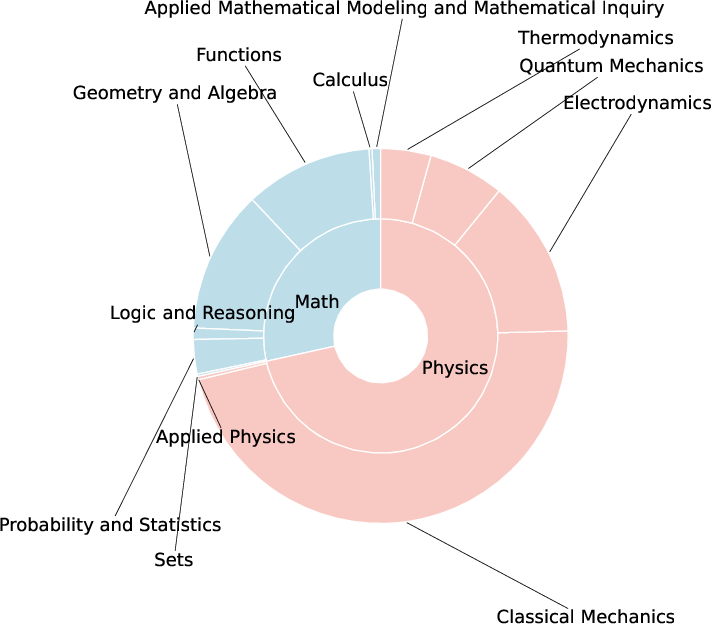
Figure 2: The distribution of data in MMSciBench according to the first-level key knowledge points for each subject.
Evaluation and Analysis
The benchmark was tested using state-of-the-art LVLMs, including Gemini 1.5 Pro 002, Qwen2-VL-72B-Instruct, and Claude 3.5 Sonnet, alongside two math-specialized LLMs. Through these experiments, MMSciBench highlights key challenges facing current models, particularly the degradation of performance in open-ended tasks, visual-textual integration limitations, and struggles with complex reasoning.
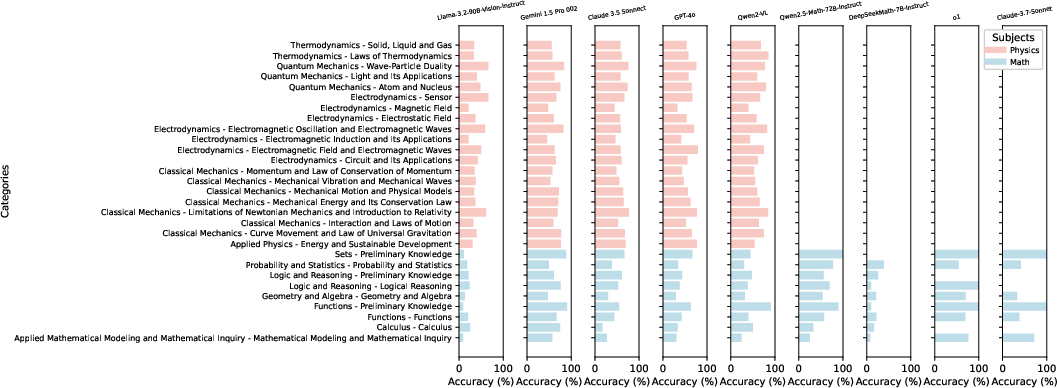
Figure 3: Accuracies of models across different key knowledge points.
For instance, the best model achieved only 63.77% accuracy, noticeably struggling with multimodal tasks. Performance notably declined in open-ended problem-solving and visual reasoning, demonstrating the issues these AI models face in integrating visual context and maintaining accuracy in more complex tasks.
Implementation Considerations
MMSciBench is deployed with an open-source codebase, and datasets are accessible via Hugging Face, facilitating reproducibility and further exploration by the scientific community. The involvement of GPT-4o as an automated evaluator exemplifies the integration of existing resources to ensure consistent assessment. However, model failure to adhere to specified output formats suggests the need for robust prompting strategies to streamline model assessment.
Conclusion
MMSciBench sets a rigorous standard for evaluating LLM and LVLM performance in multimodal scientific reasoning. The finding that current models have significant room for improvement, especially in visual reasoning, establishes MMSciBench as a critical tool for both AI research and the development of models capable of sophisticated scientific understanding. Going forward, MMSciBench serves as both a challenge and a path forward for refining AI's capabilities in practical and theoretical scientific applications.