- The paper introduces a dynamic visual workspace that enables AI to manipulate images for richer, multimodal reasoning.
- It proposes a three-stage roadmap transitioning from static image description to active, structured visual cognition.
- The paper discusses practical applications and theoretical implications that bridge traditional text-based analysis with interactive visual reasoning.
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
The paper "Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers" (2506.23918) presents a comprehensive survey and conceptual framework for the emerging paradigm of "Thinking with Images". This paradigm represents a shift from conventional text-centric reasoning to an approach where models leverage visual information as a dynamic and manipulable cognitive workspace. The paper outlines this paradigm through a three-stage roadmap of increasing cognitive autonomy, enhancing our understanding of multimodal AI's capabilities and its trajectory toward human-aligned thought processes.
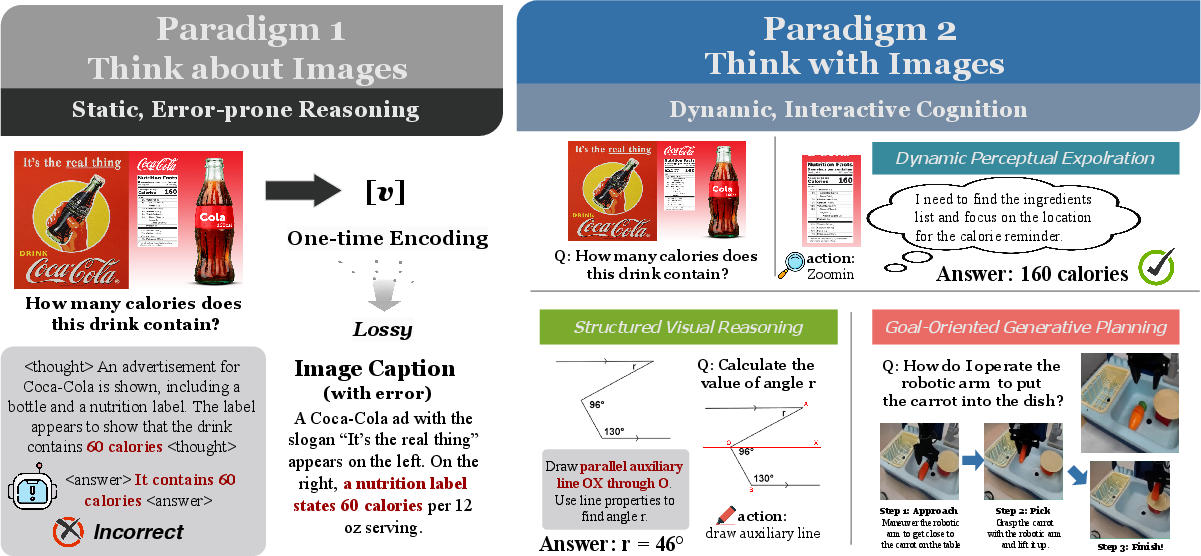
Figure 1: Conceptual comparison of Thinking about Images'' versusThinking with Images''. Paradigm 1 shows a failure case of static, error-prone reasoning. Paradigm 2 demonstrates dynamic cognition through three key capabilities: dynamic perceptual exploration, structured visual reasoning, and goal-oriented generative planning. The shift highlights the fundamental transition from static, perceptual input to a dynamic, manipulable cognitive workspace.
Introduction
The development of Large Multimodal Models (LMMs) signifies a key advancement in AI capabilities. However, traditional approaches like Chain-of-Thought (CoT) within a solely text-based framework expose limitations, such as a semantic gap between the high-dimensional perceptual data and the discrete symbolic nature of language. This gap results in perceptual information being reduced to static features, hindering the capacity for deep, iterative visual reasoning required for tasks demanding dynamic engagement like physical reasoning. Models remain limited by being restricted to "thinking about images" within a textual framework.
Figure 1: Conceptual comparison of Thinking about Images'' versusThinking with Images''. Paradigm 1 shows a failure case of static, error-prone reasoning. Paradigm 2 demonstrates dynamic cognition through three key capabilities: dynamic perceptual exploration, structured visual reasoning, and goal-oriented generative planning. The shift highlights the fundamental transition from static, perceptual input to a dynamic, manipulable cognitive workspace.
Recent advancements suggest an evolutionary shift where AI no longer merely describes visual stimuli, but actively reasons with them as manipulable elements within a dynamic visual workspace, starting to ``think with images''. This nascent paradigm shows promise for yielding advanced multimodal reasoning aligning AI closer to human-like cognitive processes.
\subsection{Implications and Future Directions}
\label{ssec:implications_futures}
The ``Thinking with Images'' paradigm introduces substantial new capabilities and presents both practical opportunities and fundamental theoretical implications for artificial intelligence.
\paragraph{Practical Impacts.}
In real-world scenarios, models capable of thinking with images have transformative potential across domains like scientific research, healthcare, education, and robotics, as discussed with examples like Visual Sketchpad for interactive tutoring and Genie for video-based reasoning. The critical practical insight lies in this paradigm empowering AI agents to move beyond passive processing to active problem solving. That said, translating this potential to practice requires addressing the efficiency and verifiability challenges previously outlined.
\paragraph{Theoretical Implications.}
Theoretically, this paradigm compels us to reconsider the role of imagery in artificial and human cognition~\citep{Chernyshev-umath-arxiv-2024}. The act of manipulating and imagining images as thinking steps suggests a more intricate model of multimodal reasoning~\citep{Yang2024Learning}. This idea aligns multimodal models closer to theories of embodied and simulation-centered human cognition, in which thought is grounded in the dynamic exploration and transformation of visual content~\citep{Zawalski2025Robotic}. Pursuing this cognitive intimacy will require substantial architectural innovations that combine vision and reasoning.
\paragraph{Speculation on AI Developments.}
Looking forward, envision novel applications and experiments that rely on multimodal reasoners. One key area lies in real-time collaboration. Future AI systems could integrate directly with our cameras, using their own imaginative power and visual reasoning to assist us on the fly. For example, a system might observe a mechanic working on an engine and display interventions as visual aids to guide repairs, using augmented reality or heads-up displays. Alternatively, it could simulate entire manufacturing processes, offering new designs and predicting outcomes by reasoning within multiple interleaved visual modalities like diagrams, sketches, and 3D models.
Furthermore, building upon this ability for imagination, future AI systems could develop the capacity for higher-order multimodal simulation: imagining and generating entire new visual narratives and experiences~\citep{Singhal2023Large, wu-TableBench-aaai-2025, Peng-XRPI-arxiv-2025, Pan-cranard-arxiv-2025}. This could pave the way for data-driven creativity in art, entertainment, and design, analogous to human visual art, writing, or architecture. These speculative frontiers would redefine AI as a medium for creative invention, a tool for strategic thought, and a partner in discovery.
Conclusion
The paper presents a structured and comprehensive survey of the "Thinking with Images" paradigm, documenting its emergence, core contributions, challenges, and transformative potential for multimodal reasoning. While we still stand on the frontier of this evolution, clear pathways have emerged for imbuing LMMs with advanced, human-like visual cognition through the internal generation, manipulation, and systematic evaluation.
Future research in this domain holds the promise of transforming LMMs from static reasoners to fully fledged visual thinkers. This synthesis of vision and reasoning capabilities would unlock profound new applications, from dynamic GUIs and interactive science tools to autonomous robots equipped with an internal ``Mind's Eye''. It challenges us to rethink the nature of reasoning and visual understanding, pushing the frontier of AI toward truly general and human-aligned intelligence. The essay closes by emphasizing that realizing this vision requires a joint advancement of methodologies and infrastructure, enabled by continuous innovation in computational efficiency, safety, and evaluation methodologies.