Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Abstract: "Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of LLMs and Vision LLMs (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.


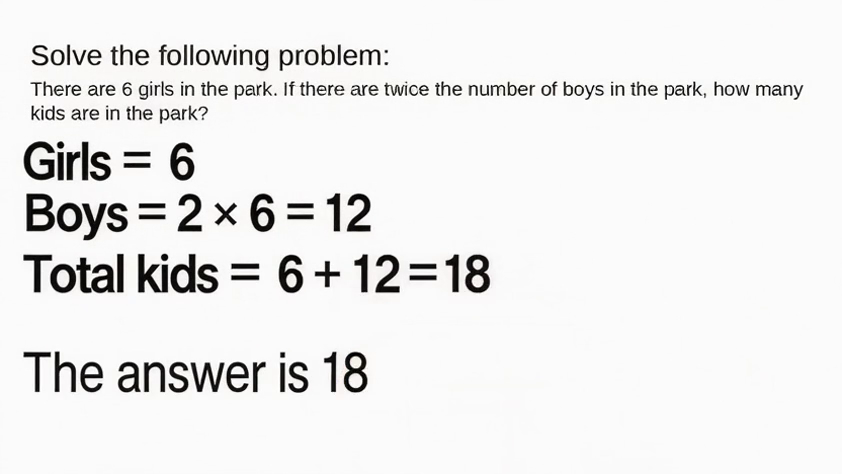



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
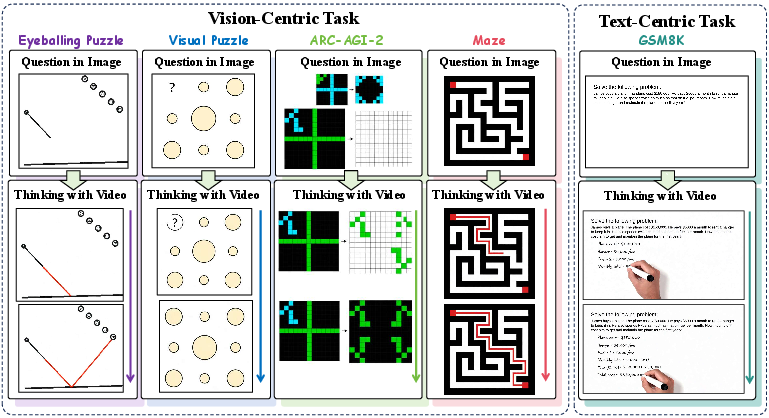
This paper introduces a new idea for how AI can “think”: instead of only thinking with text (words) or images (single pictures), it argues that AIs should “think with video.” Videos can show motion, step-by-step changes, and even include text written inside the frames. The authors test this idea using a video-generating model called Sora-2 and a new set of tasks they created, called VideoThinkBench, to see how well “thinking with video” works for both visual puzzles and text-based problems.
Key Questions the researchers asked
- Can making and using videos help an AI reason better than just using text or images?
- Can a video model solve visual tasks that involve geometry, patterns, and spatial reasoning?
- Can the same video model also do well on text and multimodal (text + image) problems?
- Do techniques like “few-shot learning” (learning from a few examples) and “self-consistency” (trying multiple times and picking the most consistent answer) improve a video model’s performance?
- Is the strong performance due to memorizing test data, or is it genuine reasoning ability?
- Where do the model’s text-based reasoning skills come from within its pipeline?
How did they study it?
The authors built a benchmark—think of it like a big, organized test set—called VideoThinkBench. It has two types of tasks:
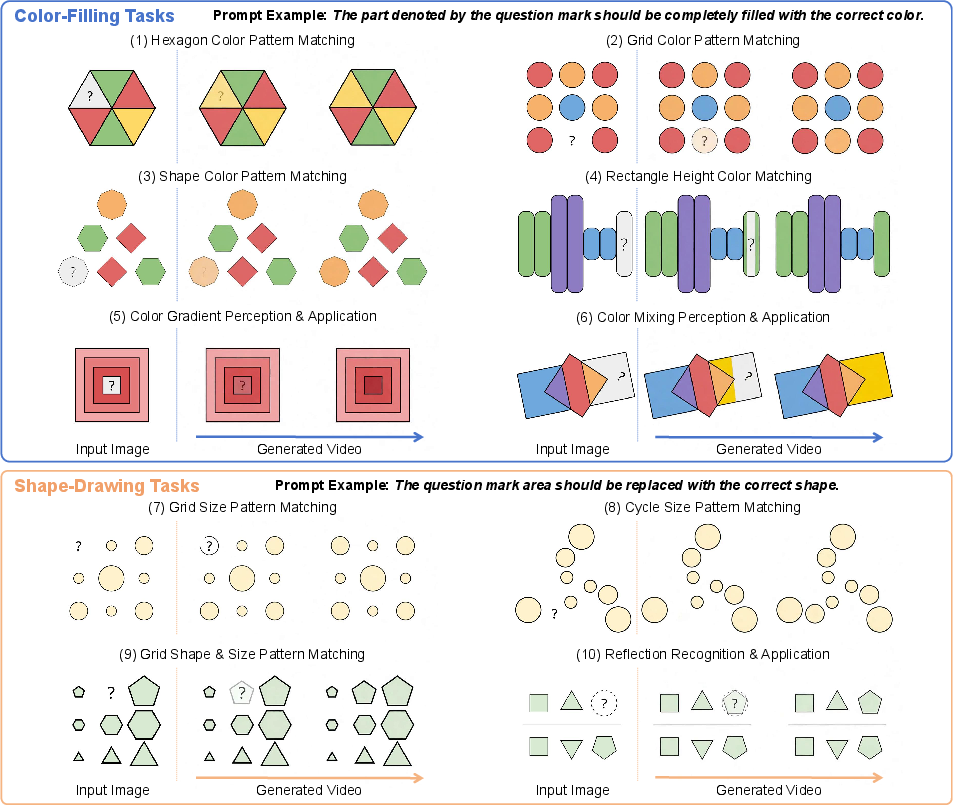
- Vision-centric tasks: These are mostly about seeing and drawing to solve puzzles.
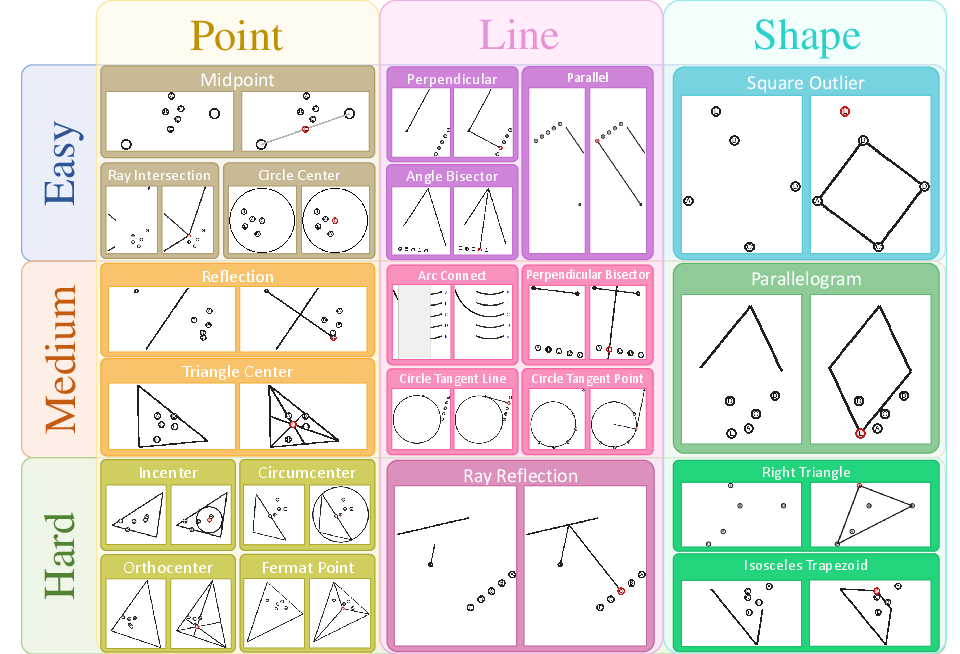
- Eyeballing puzzles (estimate and mark points, lines, or shapes in geometry)
- Visual pattern puzzles (fill the right color or draw the right shape based on patterns)
- ARC-AGI-2 (find rules from examples and apply them to new cases)
- Mazes (navigate paths; details in the appendix of the paper)
- Text-centric tasks: These are mostly about reading and reasoning with words or a mix of words and pictures.
- Math and general knowledge problems (from well-known benchmarks like GSM8K, MATH, MMLU, MathVista, MMMU, etc.)
How they measured performance:
- Sora-2 outputs a video and audio. The team checked:
- The last video frame (what’s written at the end)
- Multiple frames across the video (to see a “majority” choice over time)
- The audio (the spoken final answer, transcribed to text)
- For text tasks, they used an “LLM-as-a-Judge” approach, which is like asking a strong AI to grade the answers fairly.
- For ARC-AGI-2 and other visual tasks, they used automated checks (for example, comparing pixel colors in grids) and sometimes manual review.
- They tested “few-shot learning” by giving Sora-2 either one example or all available examples, and saw how that changed results.
- They tested “self-consistency” by generating several videos and choosing the most consistent answer, similar to taking multiple attempts and trusting the most common outcome.
Main findings and why they matter
- Videos help with spatial reasoning:
- On geometry-style eyeballing puzzles, Sora-2 was often as good as or better than leading vision-LLMs. It could draw lines, mark points, and simulate ray reflections to figure out answers.
- Using multiple frames (not just the last frame) improved accuracy, showing that the “story over time” in the video carries useful reasoning information.
- Pattern puzzles: Sora-2 could often recognize and apply color/shape/size patterns (like symmetry and gradients) and got close to top models in some tasks.
- Text and multimodal reasoning: Surprisingly strong
- On math word problems like GSM8K and MATH, Sora-2’s spoken answers (audio) were very strong—close to or sometimes comparable with top models on these subsets.
- On multimodal benchmarks (mixing images and text), Sora-2 also did well, especially when evaluating the audio answers.
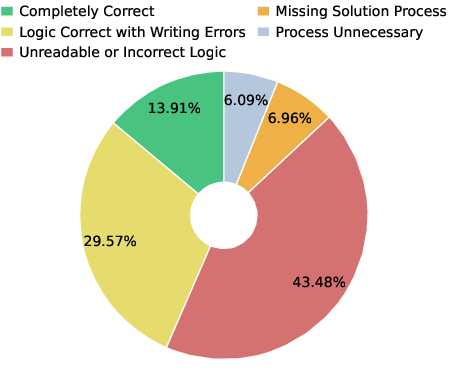
- However, its written reasoning inside the video was often messy or hard to read, even when the final answer was correct. So the model might “know” the answer but struggle to present a clean, step-by-step written solution.
- Few-shot learning helps:
- Sora-2 performed better when given multiple examples to learn the pattern (few-shot) than when given only one example (1-shot). This suggests it can learn from context like modern LLMs do.
- Self-consistency helps:
- Generating multiple videos and picking the most consistent answer raised accuracy a lot. This shows that “try several times and vote” is a powerful technique for video-based reasoning too.
- ARC-AGI-2:
- Strict accuracy was low (like other models), but manual review found Sora-2 frequently produced “mostly correct” outputs—close to the right rule—suggesting early signs of abstract pattern understanding.
- Not just memorizing:
- They changed numbers and details in math problems and saw Sora-2’s performance stay similar. That makes test set leakage (memorization of exact answers) less likely.
What does this mean for the future?
- Thinking with video could be a strong, unified way for AI to reason, because videos:
- Show movement and changes over time
- Can combine visuals and text in one place
- Better match how humans imagine and sketch solutions
- Practical impact:
- Education: AI tutors could “show their work” by drawing steps in a video, not just writing text.
- Science and engineering: Models could simulate processes (like physics or geometry) visually to help with design and problem solving.
- Robotics and planning: Videos could encode step-by-step actions and adjustments, making planning more natural.
- What still needs work:
- Clear, correct written reasoning inside videos (the “explain your steps” part) needs improvement.
- Better tools to grade video reasoning and reduce noise (for example, last-frame glitches).
- More research on test-time methods (like self-consistency) for video models, and on how prompt rewriting or submodules contribute to text reasoning.
In short, this paper’s tests suggest that video generation models like Sora-2 can reason about both pictures and words in a unified way. While not perfect, “thinking with video” looks like a promising direction for building AI that understands and explains problems more like we do—through drawing, movement, and step-by-step visual stories.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, articulated to guide future research.
- Attribution of gains to “video thinking”: The paper does not isolate the contribution of video generation versus auxiliary components (e.g., a suspected prompt-rewriter). Ablations are needed that (i) remove or replace the rewriter, (ii) compare video-only versus text-only pipelines under identical prompts, and (iii) quantify how much each component drives accuracy.
- Fairness and consistency of evaluation across models: Sora-2 and VLM baselines are tested under different output modalities, prompts, and sometimes with multiple-choice options for VLMs but not for Sora-2. A standardized protocol (same inputs, modalities, attempts, options, and time budgets) is needed to make cross-model comparisons fair and reproducible.
- Reliance on LLM-as-a-Judge without robust validation: GPT-4o is used to score last-frame images and transcribed audio, but there is no systematic quantification of judge reliability across tasks, error modes, or adversarial cases. A calibrated evaluation with human annotations, inter-rater agreement, and judge error analysis is needed.
- Audio transcription risk: Accuracy hinges on Whisper-1 transcription of phonetic outputs and spoken answers, yet the paper does not measure word error rates, misclassification rates, or robustness to noise/voice variation. Experiments should quantify transcription-induced errors and evaluate more robust ASR or constrained vocabularies.
- Unverified or partially manual scoring for visual puzzles: The “Diff” metric is introduced, but best-frame selection and manual adjudication introduce subjectivity. A fully automatic, reproducible scoring pipeline (with transparent code, thresholds, and uncertainty estimates) is needed for all visual-puzzle tasks.
- Temporal reasoning is asserted but not rigorously assessed: Most tasks are static geometry/pattern puzzles solved by drawing; few explicitly require reasoning over dynamics (e.g., kinematics, causality, temporal dependencies). Benchmarks should include controlled dynamic tasks (physics simulations, temporal logic, multi-step processes) to validate temporal reasoning claims.
- Self-consistency and test-time scaling not systematically explored: Improvements are shown on a single puzzle and limited settings. Broader studies should analyze returns versus cost (number of frames and retries), variance across tasks, diminishing returns, and parity with equal test-time budgets for all baselines.
- Few-shot learning analysis lacks standardized partial-credit metrics: ARC-AGI-2 evaluation is mostly exact-match, with ad hoc “mostly/partially correct” labels. A principled, task-agnostic partial-credit metric (e.g., pixel IoU, rule-consistency measures) and instruction-following diagnostics are needed.
- Instruction-following failures (“did nothing”): Large fractions of ARC-AGI-2 attempts fail to act on the output region. The paper does not quantify instruction adherence nor test prompt designs that improve action localization. Experiments should measure and reduce these failures via better UI cues, spatial constraints, or step-by-step controllers.
- Data leakage analysis is inconclusive: “Derived” problems were generated by other LLMs with similar structures, which may lower difficulty or bias to model priors. Stronger leakage controls should include human-authored variants, held-out domains, and task rephrasings that break template-level similarity.
- Source of text-centric ability remains speculative: The suggestion that a prompt rewriter may solve text tasks is not substantiated. Traceable logs, intermediate outputs, and controlled substitutions (e.g., using weaker/stronger rewriters) are needed to identify where problem solving occurs in the pipeline.
- Video-to-text reasoning fidelity is weak: The model often produces correct answers with unreadable or incoherent written processes. Formal measures of explanation quality (legibility, logical consistency, step alignment), OCR quality, and alignment between audio and visual reasoning are missing.
- OCR and text rendering robustness not characterized: Video-written answers may suffer from font, size, contrast, or compression issues. The paper lacks OCR robustness tests across fonts, resolutions, color schemes, and frame durations.
- Generalization across video generators: Findings are based on Sora-2 only. It is unclear whether “thinking with video” transfers to other video models (open-source or proprietary). Cross-model evaluations are needed to assess paradigm generality.
- Compute, latency, and energy costs: Video generation is computationally heavy compared to text-only CoT. No measurements are provided for runtime, energy, or cost per problem, nor comparisons of cost-adjusted accuracy versus baselines.
- Robustness to visual noise and distribution shift: The benchmarks do not probe resilience to image/video noise, occlusion, clutter, camera motion, or adversarial perturbations. Stress tests should quantify robustness and failure modes under realistic conditions.
- Task diversity and scalability: Vision-centric tasks emphasize geometry and simple patterns; text-centric tasks rely on subsets. The coverage of disciplines, real-world scenes, and complex multimodal workflows is limited. Larger, more diverse, and standardized datasets are needed.
- Benchmark reproducibility and licensing specifics: While code/datasets are referenced, key details (licenses, exact versions, seed management, and environment configs) are not fully documented in the main paper. Clear reproducibility artifacts are needed.
- Evaluation granularity for temporal consistency: The Major-Frame approach excludes “None” options and aggregates frames without analyzing temporal stability or flip-flopping. Metrics for temporal consistency, frame-level stability, and confidence calibration should be introduced.
- Impact of prompt design and UI affordances: The paper reports large sensitivity to prompts but lacks systematic prompt ablations (structure, length, visual guides, audio instructions). A prompt taxonomy and ablation study would clarify best practices.
- Integration mechanisms for multimodal fusion: Claims of unified multimodal reasoning rely on text embedded in video frames; there is no evidence of internal multimodal representation fusion or causal use of video dynamics. Experiments (e.g., occlusion tests, controlled removal of text overlays, causal mediation analysis) are needed to show genuine fusion.
- Partial correctness and rule extraction in ARC-AGI-2: “Mostly correct” cases suggest rule understanding but execution flaws. Methods to disentangle rule extraction from rendering/execution (e.g., symbolic outputs before video rendering) could pinpoint where errors arise.
- Mismatch between audio and video answers: The frequent audio > video accuracy gap is noted, but the causes (rendering, OCR, timing, truncation) are not quantified. A systematic diagnosis with synchronized frame–audio alignment and controlled timing constraints is required.
- Human-alignment validation is underspecified: The appendix mentions human alignment checks, but the main text lacks details on protocols, agreement metrics, sample sizes, and discrepancies with GPT-4o judging.
- Practical applications and task design: The paper motivates “dynamic reasoning,” yet evaluation tasks are mostly synthetic. Real-world tasks (e.g., procedural instructions, robotics-freeform planning, multi-step visual workflows) should be designed to test practical benefits of video reasoning.
- Safety, reliability, and failure handling: The paper does not address how video reasoning handles incorrect drawings, hallucinated overlays, or misleading visual artifacts. Methods for uncertainty estimation, post-hoc verification, and error recovery in video outputs are needed.
- Theoretical framing of why video helps: Beyond empirical claims, there is no formal framework explaining when and why video generation improves reasoning over text/images. A theory or set of hypotheses with testable predictions would guide task selection and model design.
Practical Applications
Practical Applications of “Thinking with Video” (from the paper’s findings, methods, and innovations)
Below are actionable use cases grouped by their deployability horizon. Each item names target sectors, suggests concrete tools/products or workflows, and lists key dependencies/assumptions that affect feasibility.
Immediate Applications
Industry
- Video whiteboard solvers for spatial tasks (geometry, layout, simple physics)
- Sectors: software, engineering/CAD, design, manufacturing training
- What: A “video chain-of-thought” assistant that draws rays, bisectors, midpoints, or construction lines to solve and explain spatial puzzles or quick layout checks; embedded in CAD or design tools for rapid sanity checks and tutorials.
- Dependencies/assumptions: Access to a capable video generator (e.g., Sora-2-like), robust last-frame/major-frame extraction, audio transcription; tolerance for occasional drawing/writing errors; latency acceptable for interactive design workflows.
- Self-consistency test-time scaling for video model outputs
- Sectors: AI/ML platforms, QA, enterprise AI ops
- What: Wrap video generation with multi-try “major-frame” and majority-vote aggregation to boost reliability on verifiable tasks (e.g., eyeballing puzzles, color/shape fills), then serve as a reliability layer in production.
- Dependencies/assumptions: Budget for extra inference; orchestration tooling; evaluation harnesses that can parse frames and aggregate across tries.
- Verifiable video QA harness for model evaluation
- Sectors: AI evaluation, MLOps, benchmarking vendors
- What: Adopt VideoThinkBench-like pipelines (eyeballing/visual puzzles, “Diff” metric, LLM-as-judge for audio/text) to continuously validate model updates and regressions for video-capable systems.
- Dependencies/assumptions: Stable evaluation code, careful prompt hygiene; LLM-as-judge alignment checks; reproducible sampling.
- Audio-first answer channels for numerical and factual tasks
- Sectors: customer support, analytics assistants, BI tools
- What: Favor audio delivery of final answers (with on-screen sketching) since audio accuracy exceeded written video text in the paper; combine with voice-to-text for logs.
- Dependencies/assumptions: High-quality speech generation and transcription; UX that accommodates audio in work contexts.
Academia
- Research toolkit for multimodal reasoning with temporal scratchpads
- Sectors: academic AI labs
- What: Use VideoThinkBench, “Diff” metrics, major-frame evaluation, and self-consistency wrappers to study temporal reasoning, failure modes, and few-shot video in-context learning.
- Dependencies/assumptions: Public availability of datasets, reproducible seeds; compute for multi-try evaluation.
- Programmatic generation of verifiable vision tasks
- Sectors: computer vision, cognitive science
- What: Extend auto-generated eyeballing/maze-like tasks for controlled experiments on spatial cognition and induction with verifiable grading.
- Dependencies/assumptions: Open code for task synthesis; standardized palettes and annotations.
Policy and Standards
- Procurement and benchmarking guidelines for video reasoning systems
- Sectors: public sector IT, standards bodies
- What: Require temporal-consistency metrics, multi-try self-consistency, and verifiable task suites (e.g., eyeballing/ARC-style) in RFPs and model audits.
- Dependencies/assumptions: Agreement on public benchmarks; clarity about acceptable compute costs for test-time scaling.
Daily Life
- Visual explainers for math and puzzles (tutoring and hobby apps)
- Sectors: education/EdTech, consumer apps
- What: Quick “chalkboard video” solutions for K–12/college math and brainteasers that show drawing steps and narrate final answers.
- Dependencies/assumptions: Guardrails for correctness; content moderation; affordable inference on consumer hardware or cloud.
- Step-by-step visual guides for DIY tasks
- Sectors: consumer how-to, support content
- What: Generate short videos that draw over images to illustrate procedures (e.g., measure, align, mark, cut) with spoken final instructions.
- Dependencies/assumptions: Reliability in spatial overlays; short-latency generation; disclaimers for safety-critical tasks.
Long-Term Applications
Industry
- Unified multimodal copilot that “thinks in video” across workflows
- Sectors: software engineering, design/CAD, robotics, media/creative
- What: Replace separate text and image CoTs with a temporal video scratchpad that blends drawing, textual overlays, and narration for planning and execution; plugins for IDEs, CAD, editors.
- Dependencies/assumptions: Stronger video models with robust text rendering, lower latency, and controllable scene dynamics.
- Robotics and operations planning via internal video imagination
- Sectors: robotics, logistics, manufacturing
- What: Use video-based reasoning to simulate manipulations, path planning, or assembly steps; link to real controllers after human review of the “plan video.”
- Dependencies/assumptions: Accurate physical consistency; sim-to-real bridges; safety layers; data to ground the video plan in constraints.
- Digital twins with video explanations of system states and “what-ifs”
- Sectors: energy, industrial IoT, smart buildings
- What: Generate temporal visual narratives of process dynamics (flows, setpoint changes) to support operators and incident reviews.
- Dependencies/assumptions: Integrations with telemetry and simulation; trust calibration; governance for critical operations.
- Visual QA for manufacturing and layout verification
- Sectors: manufacturing, AEC (architecture/engineering/construction)
- What: Video models that check tolerances, alignments, and sequences by “drawing” measurement lines/overlays and highlighting deviations over time.
- Dependencies/assumptions: High-resolution, calibrated inputs; standardized measurement semantics; regulatory acceptance.
- Content creation pipelines that blend reasoning and animation
- Sectors: media, marketing, education
- What: Script-to-explainer video systems where the model derives the reasoning and animates it coherently (numbers, diagrams, labels) with narration.
- Dependencies/assumptions: Reliable on-screen text; IP licensing; editorial controls.
Academia
- Theory and methods for video-based in-context learning and induction
- Sectors: AI research
- What: Formalize “visual ICL” on ARC-like tasks; study curriculum design, example ordering, and video prompt design for improved abstraction.
- Dependencies/assumptions: Larger, diverse ARC-style corpora; better inductive bias in generators.
- New evaluation science for temporal reasoning
- Sectors: ML evaluation
- What: Standardize temporal metrics (frame-majority, temporal coherence, process correctness), human alignment checks, and LLM-as-judge protocols for video.
- Dependencies/assumptions: Community consensus; robust judge models for video; bias audits.
- Cognitive science of dynamic externalization
- Sectors: cognitive science, HCI
- What: Use “thinking with video” to probe how externalized temporal sketches affect human–AI collaboration and learning.
- Dependencies/assumptions: IRB-approved studies; consistent UX across conditions.
Policy and Standards
- Safety, audit, and transparency frameworks for video reasoning
- Sectors: regulators, compliance, safety engineering
- What: Mandate logging of video scratchpads for high-stakes decisions (audit trails), with verifiable tasks to test temporal consistency and failure modes.
- Dependencies/assumptions: Privacy-respecting storage; redaction; accepted criteria for “sufficient process transparency.”
- Education standards for video-first reasoning artifacts
- Sectors: education policy
- What: Guidelines for grading “video chain-of-thought” submissions (process + answer), with auto-grading where tasks are verifiable (eyeballing-style, geometry).
- Dependencies/assumptions: Assessment equity; accommodations; integrity and plagiarism detection.
Daily Life
- AR guidance with live “drawn” overlays and narrated answers
- Sectors: consumer AR, smart assistants
- What: On-device assistants that sketch guides in the camera view (e.g., where to drill, how to align a frame) and speak concise instructions.
- Dependencies/assumptions: On-device or low-latency edge models; precise spatial registration; safety constraints and disclaimers.
- Personalized learning companions for complex subjects
- Sectors: lifelong learning, EdTech
- What: Dynamic visual narratives for topics like physics, calculus, and statistics that adapt examples and draw derivations step-by-step.
- Dependencies/assumptions: Better math rendering in video; curriculum alignment; factual robustness.
- Scenario simulation for financial literacy and risk education
- Sectors: finance education, consumer apps
- What: Short videos that play out “what-if” timelines (budget changes, loan choices) with overlays and narrated takeaways.
- Dependencies/assumptions: Accurate models of financial dynamics; clear disclaimers; avoidance of advice liability.
Cross-Cutting Tools, Products, and Workflows (implicit in the items above)
- Video CoT Studio: An SDK/service that turns prompts + references into narrated, step-by-step “thinking videos,” with APIs for major-frame parsing, audio extraction, and multi-try voting.
- Verifiable Video Eval Kit: Open-source harness with eyeballing/visual puzzle generators, Diff metrics, LLM-as-judge prompts, and human-alignment sampling.
- Temporal Reliability Layer: A microservice that performs test-time scaling (N video generations), temporal majority voting, and confidence scoring before surfacing answers.
- CAD/IDE Plugins: In-app “draw-to-reason” panels for geometry/CAD and code/diagram reasoning, exporting short videos as artifacts for code reviews or design reviews.
Key Assumptions and Dependencies (global)
- Access to high-quality video generation models comparable to Sora-2; efficient inference and acceptable latency/cost.
- Reliable multimodal I/O: robust audio TTS/STT; accurate on-frame text rendering; stable frame content (avoid end-frame glitches).
- Trust and safety: process transparency without leaking sensitive data; audit trails; content moderation of generated videos.
- Evaluation robustness: validated judge models and temporal metrics; representative, leakage-free benchmarks; human alignment checks.
- IP and licensing for training data and generated outputs; governance in regulated sectors (healthcare, energy, finance).
- Continued research to improve process correctness (not only final answers), induction on abstract tasks (ARC-AGI-2), and controllability of temporal generation.
Glossary
- AIME24: A subset of the American Invitational Mathematics Examination 2024 used as a math reasoning benchmark. Example: "AIME24"
- ARC-AGI-2: A benchmark targeting few-shot, inductive reasoning over abstract pattern transformations on colored grids. Example: "ARC-AGI-2 is a benchmark targeting few-shot, inductive reasoning over abstract pattern transformations."
- Audio Evaluation: An evaluation method that extracts and transcribes the model’s spoken answer from generated video audio. Example: "Audio Evaluation: The prompt instructs model to speak out the option in phonetic alphabet (
Alpha'',Bravo'',Charlie'',Delta'' and ``Echo'')." - BBH: Big-Bench Hard, a suite of challenging reasoning tasks used to evaluate LLMs. Example: "BBH"
- Chain-of-thought (CoT): A prompting strategy that elicits step-by-step reasoning to improve performance on complex tasks. Example: "Chain-of-thought (CoT) significantly improves the reasoning ability of LLMs"
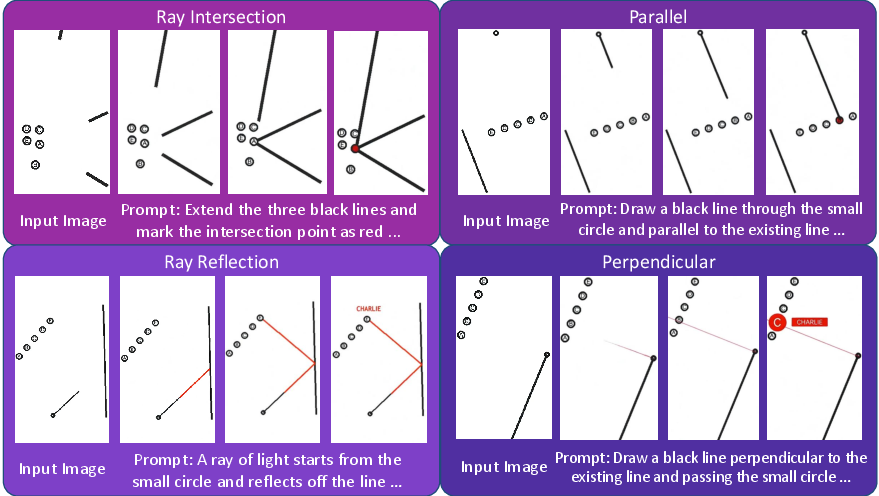
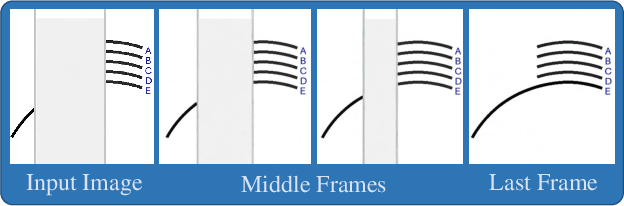
- Eyeballing Puzzles: Custom, verifiable spatial reasoning tasks requiring geometric estimation and construction. Example: "The evaluation methods of Sora-2 on Eyeballing Puzzles are introduced as follows:"
- Few-shot learner: A model that can infer patterns and generalize from a small number of provided examples. Example: "Sora-2 is a few-shot learner."
- GPQA-diamond: The hardest split of the Graduate-level Google-Proof Question Answering benchmark. Example: "GPQA-diamond"
- GSM8K: A grade-school math word problem dataset used to assess arithmetic and reasoning. Example: "GSM8K"
- In-context learning (ICL): A paradigm where models make predictions by conditioning on a few demonstrations within the prompt. Example: "In-context learning (ICL) is a paradigm for NLP, where LLMs make predictions based on contexts augmented with a few examples."
- Last Frame Evaluation: An evaluation method that reads the model’s drawn answer from the final video frame. Example: "Last Frame Evaluation: The prompt instructs model to draw a red dot on correct option."
- LLMs: Foundation models trained on vast text corpora to perform language understanding and generation. Example: "LLMs"
- LLM-as-a-Judge: An evaluation approach that uses a LLM to assess correctness of outputs (e.g., answers extracted from video or audio). Example: "LLM-as-a-Judge~\citep{zheng2023judging} approach"
- Major Frame Evaluation: An evaluation method that samples multiple frames across the video and uses majority voting to determine the answer. Example: "Major Frame Evaluation: For every 5 frames in the video, one frame is extracted and fed to the image evaluator, getting option of this frame."
- MATH-500: A subset of the MATH benchmark used for math reasoning evaluation. Example: "MATH-500"
- MathVision: A benchmark for measuring multimodal mathematical reasoning with visual inputs. Example: "MathVision"
- MathVista: A multimodal math reasoning benchmark involving images and textual reasoning. Example: "MathVista"
- MMBench: A benchmark assessing general visual understanding for multimodal models. Example: "MMBench"
- MMMU: A multi-discipline multimodal reasoning benchmark across diverse expert domains. Example: "MMMU"
- Pixel accuracy: A metric measuring the proportion of output pixels matching the ground truth in grid-based tasks. Example: "we measure performance using \"pixel accuracy\": the percentage of pixels in the output area that match the ground truth."
- Prompt rewriter model: A component hypothesized to reformulate prompts/solutions prior to video generation, potentially aiding reasoning. Example: "may originate from the prompt rewriter model."
- Self-consistency: A test-time method that aggregates multiple reasoning paths or outputs to improve reliability and accuracy. Example: "Self-consistency can improve Sora-2âs performance in the verifiable video generation reasoning task."
- SMPTE color bars: A standardized test pattern used in video engineering; its appearance can interfere with last-frame evaluation. Example: "the end of generated videos sometimes flash to SMPTE color bars"
- State-of-the-art (SOTA): Refers to the best-performing methods or models available at the time. Example: "Sora-2 is generally comparable to SOTA VLMs"
- SuperGPQA-easy: An easier split of the SuperGPQA benchmark for evaluating high-level question answering. Example: "SuperGPQA-easy"
- Test time scaling: Techniques that improve performance by using additional computation or sampling at inference time. Example: "test time scaling in video generation reasoning tasks"
- Thinking with Video: A paradigm that uses video generation to unify dynamic visual and textual reasoning within a temporal framework. Example: "we propose ``Thinking with Video''."
- VideoThinkBench: A comprehensive benchmark introduced to evaluate video-generation-based reasoning across vision- and text-centric tasks. Example: "We introduce the Video Thinking Benchmark (VideoThinkBench)"
- Vision LLMs (VLMs): Models that jointly process visual and textual inputs for multimodal understanding and generation. Example: "Vision LLMs (VLMs)"
- Whisper-1 model: A speech recognition model used to transcribe audio from generated videos during evaluation. Example: "Audio is extracted from generated video and transcribed using whisper-1 model."
Collections
Sign up for free to add this paper to one or more collections.