V-Thinker: Interactive Thinking with Images
Abstract: Empowering Large Multimodal Models (LMMs) to deeply integrate image interaction with long-horizon reasoning capabilities remains a long-standing challenge in this field. Recent advances in vision-centric reasoning explore a promising "Thinking with Images" paradigm for LMMs, marking a shift from image-assisted reasoning to image-interactive thinking. While this milestone enables models to focus on fine-grained image regions, progress remains constrained by limited visual tool spaces and task-specific workflow designs. To bridge this gap, we present V-Thinker, a general-purpose multimodal reasoning assistant that enables interactive, vision-centric thinking through end-to-end reinforcement learning. V-Thinker comprises two key components: (1) a Data Evolution Flywheel that automatically synthesizes, evolves, and verifies interactive reasoning datasets across three dimensions-diversity, quality, and difficulty; and (2) a Visual Progressive Training Curriculum that first aligns perception via point-level supervision, then integrates interactive reasoning through a two-stage reinforcement learning framework. Furthermore, we introduce VTBench, an expert-verified benchmark targeting vision-centric interactive reasoning tasks. Extensive experiments demonstrate that V-Thinker consistently outperforms strong LMM-based baselines in both general and interactive reasoning scenarios, providing valuable insights for advancing image-interactive reasoning applications.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
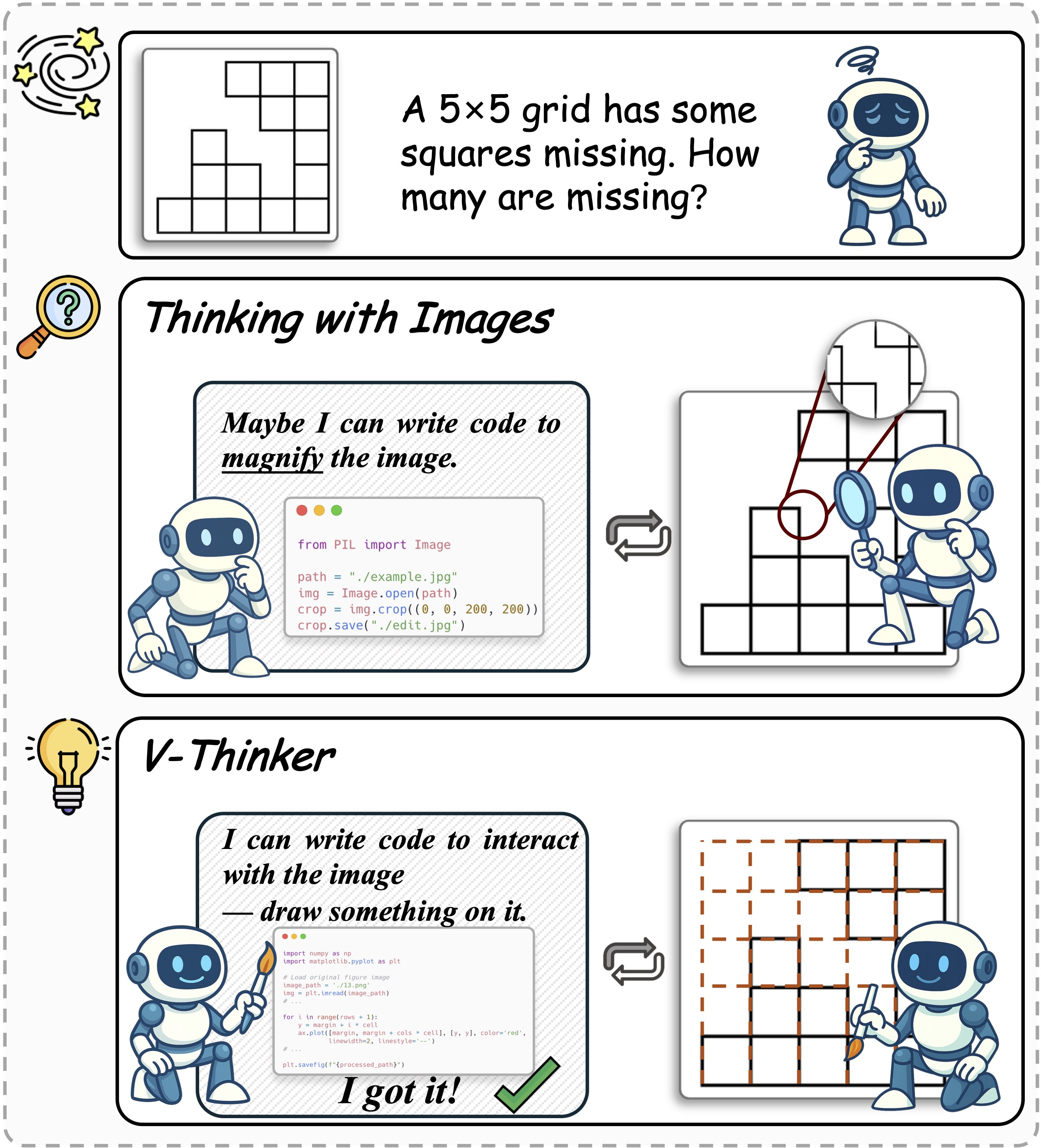
This paper introduces V-Thinker, a computer system that can look at pictures and think step by step while actually interacting with the images. Instead of only describing what it sees, V-Thinker can draw on the image, crop parts, add lines, and use these changes to reason better. The goal is to make AIs reason more like humans do when solving visual problems (such as geometry diagrams), by using the image itself as part of the thinking process.
What questions did the researchers ask?
To make this happen, the paper focuses on four simple questions:
- How can we help AI connect its thinking directly to what’s in a picture, so it doesn’t “hallucinate” or make things up?
- How can we automatically create lots of good training problems that need image interaction (not just text)?
- What is a smart way to train an AI so it first learns to “see” precisely, then learns to “think and act” on images?
- How do we test whether the AI is truly better at interactive picture-based reasoning?
How did they do it?
The researchers designed three main parts: a way to build training data, a step-by-step training plan, and a benchmark to test the system.
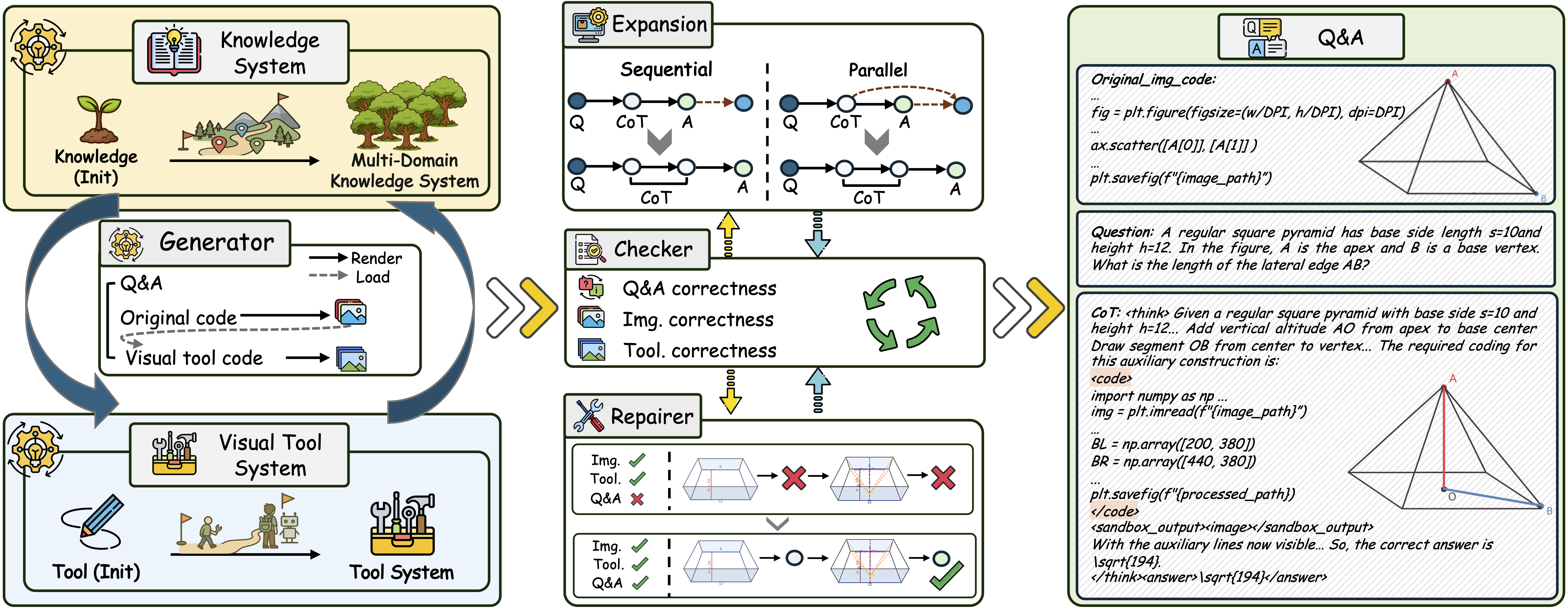
1) Data Evolution Flywheel: a cycle to make and improve training data
Think of a teacher who keeps making new worksheets, checks them, fixes mistakes, and then makes harder ones. The “flywheel” is a repeating cycle that does this automatically:
- Diversity: They start with knowledge topics (like geometry or logic) and a set of visual tools (like drawing lines, cropping, labeling). A strong model generates brand-new problems, the code to render images, and the step-by-step reasoning with image edits. As it makes more problems, the set of topics and tools grows.
- Quality: A “checker” confirms the answers are correct, the images render properly, and all edit steps make sense. If something’s off, a “repairer” adjusts the questions or labels so everything matches.
- Difficulty: They make problems tougher by adding more steps or linking new steps to previous ones, just like making multi-part puzzles.
This creates a large, high-quality dataset called V-Interaction-400K, full of tasks where the AI must interact with the image to solve the problem.
2) Visual Progressive Training Curriculum: teach “see” first, “think and act” next
The AI is trained in two stages, like learning to drive: first learn to see, then learn to make decisions.
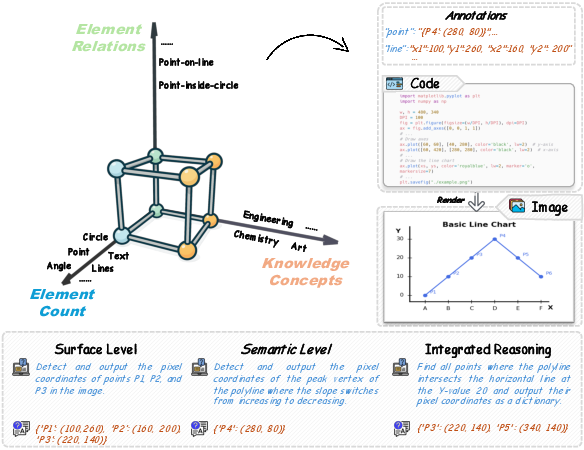
- Perception Alignment: The AI practices pinpointing exact visual anchors—like the coordinates of a point, the top-left corner of a shape, or the intersection of two lines. This improves its precise “seeing” ability. They built a special dataset for this called V-Perception-40K.
- Interactive Reasoning Alignment: After it can see well, the AI is taught to reason by writing small pieces of code that edit the image (for example, draw an auxiliary line or highlight a region) and then use the edited image to continue reasoning. First they use supervised training (showing it examples of good solutions), then reinforcement learning.
What is reinforcement learning here?
Reinforcement learning (RL) is like training a player in a video game by giving rewards when it does well. The AI tries different “moves” (pieces of code that edit the image). If the final answer is correct and it used good formatting and useful tools, it gets a reward. Over time, it learns which actions lead to success. The paper uses a safe “sandbox” to run the code and a method called GRPO to update the AI based on these rewards.
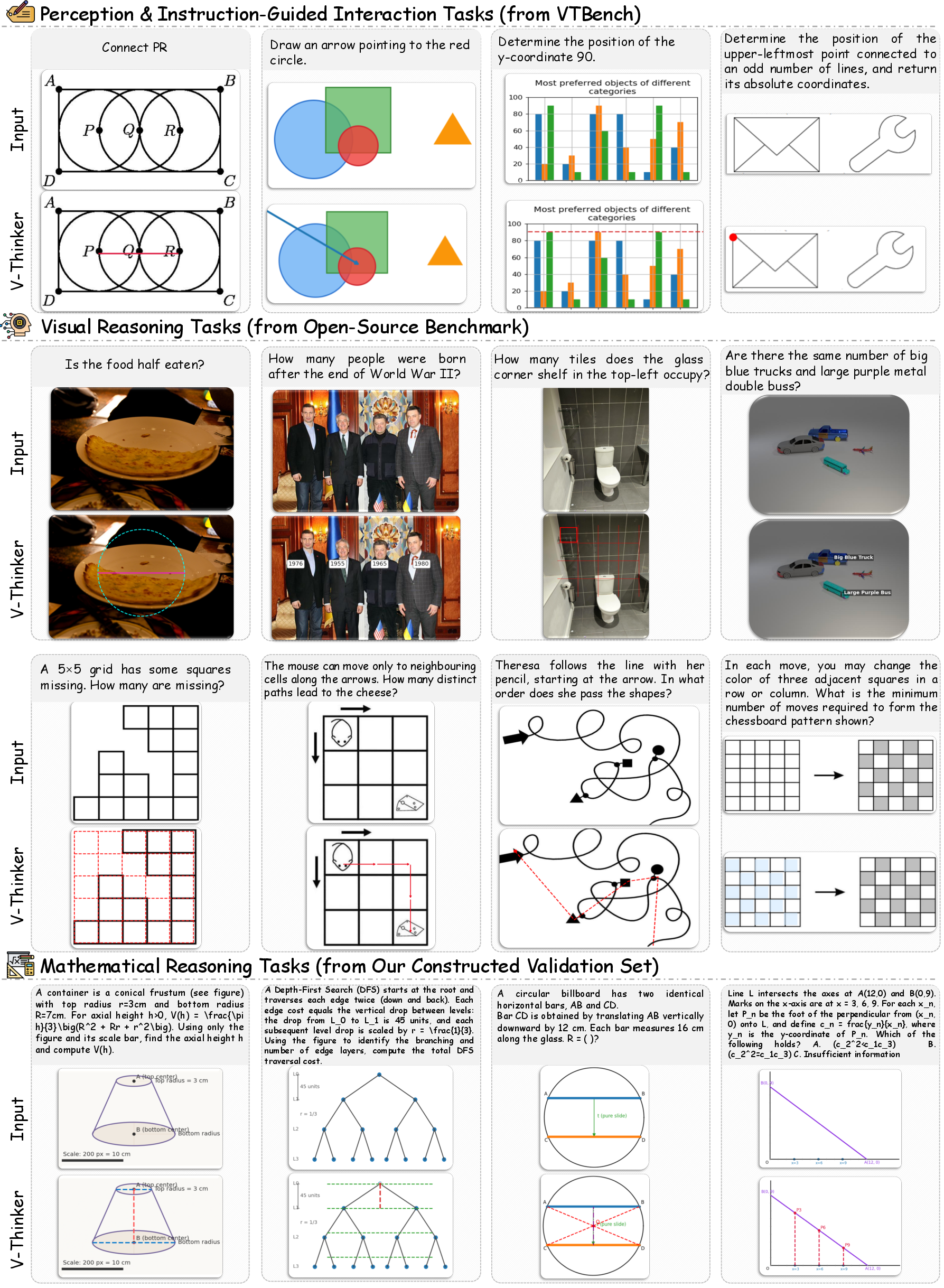
3) VTBench: a test designed for interactive image tasks
To fairly measure progress, the authors built VTBench, a benchmark of 1,500 tasks checked by experts. It includes:
- Perception tasks: identify exact visual details (like a point’s location) using code that marks the image.
- Instruction-Guided Interaction: follow instructions to edit the image (draw a line, label a region) with code.
- Interactive Reasoning: solve multi-step problems where editing the image is part of the solution.
Experts ensure the tasks truly need image interaction, not just text reasoning.
What did they find, and why is it important?
The results show clear improvements:
- V-Thinker beats strong baseline models (like popular open-source systems and GPT-4o) on VTBench, especially in tasks that require following instructions and interacting with images. For example, the 7B version of V-Thinker improves instruction-guided interaction accuracy by over 25 percentage points compared to a strong 7B baseline.
- It also performs better on general reasoning benchmarks (like MathVision and We-Math) without adding special in-domain data, which means the interactive training helps overall reasoning too.
- Ablation tests (removing training parts) show that both perception training and reinforcement learning are crucial. If you remove either step, performance drops significantly.
Why this matters: Many AI models can write long, nice explanations but don’t stay grounded in the actual picture—they can “hallucinate.” V-Thinker keeps the thinking tied to the image by editing it step by step and using those edits as evidence. This makes reasoning more trustworthy and more like how people solve visual problems (for example, drawing extra lines in geometry).
What could this change in the real world?
If AIs can truly “think with images” by interacting with them:
- Math and Science learning: Better help with geometry diagrams, graphs, and physics sketches, drawing and labeling as part of the explanation.
- Tutoring and homework help: Clearer visual steps instead of just text, making solutions easier to follow.
- Document and diagram understanding: More accurate reading and correction of charts, plans, or technical drawings.
- Professional fields: Potential improvements in areas like medical imaging or engineering, where careful visual reasoning is key.
Overall, the paper shows a path to more human-like multimodal thinking: see precisely, act on the image, reflect, and repeat. This approach helps build AI that reasons clearly and stays connected to the visual facts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open directions that emerge from the paper; each item is phrased to be concrete and actionable for future work.
- Reproducibility of the data flywheel: The pipeline depends on proprietary models (
GPT‑5,GPT‑4.1) for generation and repair, and large opaque judges (e.g.,Qwen3‑VL‑232B), with no released prompts/seeds or ablation of their roles; provide open, reproducible surrogates, release prompts, and quantify sensitivity to generator/checker choices. - Bias toward synthetic, code-rendered diagrams: Most training data (V‑Interaction‑400K) are generated via Python rendering; assess domain shift to real, noisy photographs and scanned documents by curating a real-image interactive dataset with human-verified ground truth.
- Limited visual tool space: Current tools appear to focus on drawing/annotation/cropping in 2D; evaluate and extend to richer actions (segmentation, detection, perspective transforms, geometry fitting, OCR-aware edits, region masking, inpainting) and measure gains per tool family.
- No evaluation on video/temporal or 3D reasoning: Investigate interactive reasoning over video frames and 3D scenes (e.g., multi-view geometry, point clouds) with temporally coherent tool invocation.
- Single-image, single-modal scope: Explore multi-image and cross-document interactions (e.g., compare diagrams, align plots across pages), and multi-modal cues (audio instructions, pen gestures).
- Perception alignment limited to point-level supervision: Add line/curve/region supervision and metrics (IoU, endpoint error, angle deviation), and test robustness under occlusion, clutter, scaling, and rotation.
- Rewards sparse and final-answer gated: Current reward grants tool-use credit only if final answer is correct; study denser reward shaping using intermediate visual-grounding signals (e.g., overlap with reference annotations), stepwise correctness, and alignment to expert trajectories.
- Error handling in the sandbox: Characterize frequency and recovery from code syntax/runtime errors, add explicit policies (retry, patching, constrained APIs), and quantify their impact on success rates.
- Missing fairness in baseline comparison: Baseline LMMs are evaluated without access to the same executable tool environment; re-benchmark strong baselines in the identical sandbox to disentangle interface benefits from model-specific gains.
- LLM-judged visual metrics: Perception and interaction tasks are judged by LLMs comparing rendered images; validate with human raters and objective pixel-level metrics (e.g., keypoint distance thresholds, IoU), and report inter-rater reliability and error cases.
- VTBench scale and coverage: With 1,500 items and three task types, analyze coverage by domain, difficulty, and tool use; expand to charts/plots, documents, natural scenes, and non-geometric math; publish per-domain breakdowns and confidence intervals.
- “Interaction necessity” subjectivity: The inclusion criterion (≥3/5 experts) may be subjective; release rationales, measure inter-annotator agreement (Cohen’s/Fleiss’ κ), and analyze disagreements to refine task definitions.
- Contamination risk and leakage: Quantify overlap between VTBench and training sources (public benchmarks and model pretraining corpora), and perform leakage audits.
- Lack of detailed failure analysis: Provide a taxonomy of errors (perception vs. planning vs. tool execution), breakdown by tool type and reasoning depth, and targeted fixes for frequent failure modes.
- No step/latency efficiency metrics: Report number of tool calls, reasoning steps, wall-clock latency, and compute cost per task; explore step penalties or efficiency-aware rewards.
- Limited ablations of the data flywheel: Isolate the contributions of “Knowledge-driven Evolution,” “Coordinated Calibration,” and “Progressive Expansion,” including the effect of parallel vs. sequential extensions on difficulty and performance.
- Curriculum sensitivity: Test alternative curriculum orders (e.g., RL before or interleaved with SFT), curriculum lengths, and the size of V‑Perception‑40K to derive curriculum scaling laws.
- RL stability and hyperparameter sensitivity: Provide variance across seeds, sensitivity to GRPO hyperparameters (
ε_l,ε_h,λ_1,λ_2, rollout count), and comparisons to alternative policy optimization methods. - Generalization to unseen tools and executors: Evaluate transfer when introducing new tools or switching to a different executor API, and study rapid tool-adaptation with few-shot demonstrations.
- Causal contribution of edits: Conduct intervention studies that remove or perturb generated visual edits to quantify their causal impact on correctness and reduce spurious tool usage.
- Human-in-the-loop interaction: Explore interactive correction/teaching from users during reasoning (e.g., user-adjusted anchors), and measure sample efficiency and reliability gains.
- Safety and security of code execution: Analyze sandbox robustness (resource limits, file/network isolation), adversarial prompts, and potential escapes; publish a security threat model and mitigations.
- Data and code release clarity: Specify the release status, licenses, and accessibility of V‑Interaction‑400K, V‑Perception‑40K, the executor, and VTBench to enable community verification.
- Multilingual coverage: Assess performance on non-English prompts and multilingual diagrams/labels; extend data synthesis and VTBench to multiple languages.
- OCR- and text-heavy scenarios: Benchmark on document reasoning (tables, forms, plots) where OCR and fine-grained typography matter; integrate OCR-aware tools and evaluate their effect.
- Long-horizon limits: Progressive expansion is capped at three steps; probe performance and stability on longer chains (e.g., 5–10+ steps) and study degradation patterns.
- Knowledge/tool evolution quality control: Quantify precision/recall of
Φ_KandΦ_Texpansions, detect semantic drift, and add human verification loops or constraints to prevent concept/tool mis-specification. - Scaling laws and saturation: The scaling analysis of iterations is truncated; complete and publish scaling curves relating iterations, dataset growth, and performance, including signs of saturation or negative transfer.
- Base-model dependence: Results are centered on
Qwen2.5‑VL‑7B; replicate across diverse bases (e.g., InternVL, LLaVA-OV, Mistral-VL) to assess portability of the curriculum and RL gains. - Robustness to image corruptions: Introduce controlled photometric/geometric corruptions (blur, noise, JPEG artifacts, rotation) to both training and VTBench, and report corruption robustness benchmarks.
Glossary
- Advantage: In reinforcement learning, the estimated benefit of taking a particular action compared to a baseline at a given time step. "and denotes the advantage at time step ."
- Agentic RL: A reinforcement learning perspective emphasizing autonomous, tool-using, agent-like behaviors within complex tasks. "provides a fresh perspective for the field of agentic RL."
- BGE-based hierarchical clustering: A clustering approach that uses BGE embeddings to hierarchically group similar concepts or tools. "via BGE-based hierarchical clustering."
- Chain-of-thought (CoT): Explicit step-by-step reasoning traces produced by models to make their problem-solving process transparent. "chainâofâthought (CoT)"
- Co-evolutionary loop: An iterative process where two (or more) sets, such as knowledge and tools, mutually expand each other through generation and feedback. "constitute a co-evolutionary loop"
- Cold-Start Fine-tuning: An initial supervised fine-tuning phase that equips a model with foundational capabilities before RL. "In the Cold-Start Fine-tuning stage"
- Coordinated Calibration: A verification-and-repair process ensuring consistency across text, code, and visuals in synthesized data. "Coordinated Calibration (§\ref{sec:checker}) verifies the correctness of generated questions, rendered images, and edited visual states,"
- Data Evolution Flywheel: An automated framework that continuously synthesizes, verifies, and expands datasets along diversity, quality, and difficulty axes. "We propose a Data Evolution Flywheel that automatically synthesizes, evolves, and verifies interactive reasoning datasets across three dimensions: Diversity, Quality, and Difficulty,"
- Group Relative Policy Optimization (GRPO): A policy-gradient RL algorithm that optimizes a policy relative to a reference across grouped rollouts. "we adopt Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath},"
- Hallucinations: Model outputs that are plausible-sounding but ungrounded or incorrect with respect to the input image or facts. "leading to hallucinations~\citep{Hallu_survey,self-reward-vl,Hallusionbench}."
- Importance sampling ratio: The likelihood ratio used in off-policy policy-gradient updates to reweight samples from a reference policy. "represents the importance sampling ratio for the -th token of the -th output,"
- Indicator function: A function that is 1 when a condition holds and 0 otherwise, used here to gate reward terms. "is an indicator function ensuring that the tool usage reward is applied only when the final answer is correct and involves at least one tool."
- Interactive Reasoning Alignment: Training that aligns perception with code-driven interactions so the model can reason by editing and inspecting images. "Interactive Reasoning Alignment. Built upon the perceptual foundation, we implement cold-start supervised fine-tuning followed by RL within a sandboxed executor environment,"
- Knowledge-driven Evolution: Dataset generation guided by structured knowledge concepts and tool sets that expand each other iteratively. "Knowledge-driven Evolution (§\ref{sec:generator}) generates reasoning data through the co-evolution of knowledge and tool sets,"
- Large Multimodal Models (LMMs): Foundation models that process and reason over multiple modalities, such as text and images. "Empowering Large Multimodal Models (LMMs) to deeply integrate image interaction with long-horizon reasoning capabilities remains a long-standing witness in this field."
- Multimodal LLMs (MLLMs): LLMs extended to handle multimodal inputs for reasoning across text and vision. "multimodal LLMs (MLLMs) have significantly enhanced their reasoning capabilities across diverse tasks"
- Perception Alignment: A training stage focused on improving fine-grained visual localization and reference of elements. "Perception Alignment."
- Point-level supervision: Supervision at precise pixel/coordinate points to improve localization of visual anchors. "first aligns perception via point-level supervision"
- Progressive Expansion: A procedure that increases task difficulty by adding parallel or sequential steps to the reasoning chain. "Progressive Expansion (§\ref{sec:explorer}) enhances reasoning difficulty via iterative step extension and compositional knowledge integration,"
- Reasoning trajectory: The sequence of thoughts, code actions, and resulting images produced during step-by-step problem solving. "a reasoning trajectory "
- Reinforcement learning (RL): A learning paradigm where an agent optimizes actions through rewards from interacting with an environment. "We apply reinforcement learning (RL) to enhance the model's interactive reasoning capabilities."
- Reward function: The scalar feedback design that guides policy learning, here combining accuracy, formatting, and tool usage. "We follow a reward function based on the Thyme framework~\citep{zhang2025thyme},"
- Sandboxed executor environment: A controlled runtime that safely executes model-generated code for image interactions. "within a sandboxed executor environment"
- Supervised Fine-Tuning (SFT): Training on input-output pairs to adapt a pretrained model to specific tasks. "The model is trained using supervised fine-tuning, with the objective of minimizing the loss function:"
- Vision-centric reasoning: Reasoning paradigms that emphasize visual perception and manipulation as central to problem solving. "visionâcentric reasoning"
- Visual grounding: The alignment of textual reasoning with specific evidence in the image. "detach from visual grounding"
- Visual Progressive Training Curriculum: A two-stage training plan that first aligns perception and then aligns interactive reasoning. "a Visual Progressive Training Curriculum that first aligns perception via point-level supervision"
- Visual tool space: The set of image manipulation operations (e.g., crop, draw) available to the agent for interaction. "narrow visual tool spaces"
- V-Interaction-400K: A large-scale dataset of verified, interactive, vision-centric reasoning samples produced by the flywheel. "a high-quality visual interactive reasoning dataset, namely V-Interaction-400K."
- V-Perception-40K: A perception-focused dataset with point-level annotations to improve localization abilities. "named V-Perception-40K."
- VTBench: An expert-verified benchmark for evaluating vision-centric interactive reasoning across perception and interaction tasks. "we introduce VTBench, a benchmark targeting tasks that inherently demand visual interaction."
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, assuming a human-in-the-loop, safe code execution, and standard MLOps integration.
- Interactive STEM tutoring and homework assistance for geometry and math (Sectors: education, software) — What: An assistant that draws auxiliary lines, labels points, and iteratively edits diagrams while explaining multi-step reasoning; supports problem generation for practice. — Tools/Workflow: V-Thinker API in a browser IDE or LMS; code-driven visual edits (draw lines, mark points, crop); VTBench-style evaluation to gate updates. — Dependencies/Assumptions: Safe code sandbox; teacher review for grading; content filters; acceptable latency on commodity GPUs.
- Smart diagram annotator for documents and slides (Sectors: productivity software, enterprise IT) — What: Auto-annotate PDFs/PowerPoint/Keynote figures (flowcharts, blueprints, charts) with labels, guide-lines, and callouts grounded in the image; explain logic behind edits. — Tools/Workflow: Plug-in for Office/Google Workspace/Figma; V-Thinker’s code-to-image toolchain for markups; versioned outputs for review. — Dependencies/Assumptions: On-prem or VPC deployment for sensitive files; OCR/diagram parsers integrated; human approval before export.
- Customer support and QA over screenshots (Sectors: software, CX) — What: Agents that highlight UI elements on user screenshots, reproduce steps with annotated overlays, and provide fix instructions. — Tools/Workflow: Support console plug-in; screenshot ingestion; interactive overlays; issue templates. — Dependencies/Assumptions: UI element detection accuracy; privacy guardrails; explicit opt-in for image use.
- Visual inspection co-pilot with interactive overlays (Sectors: manufacturing, e-commerce, logistics) — What: Assist inspectors by drawing measurement lines, tolerance regions, or defect boxes on product images; compare pre/post states. — Tools/Workflow: Operator console with side-by-side edited images; audit trail of code and edits; threshold-driven flagging. — Dependencies/Assumptions: Calibrated reference images; human-in-the-loop sign-off; domain-specific tool presets (e.g., pixels-to-mm mapping).
- Technical content validation before publication (Sectors: academia, publishing, R&D) — What: Pre-flight checks that interactively verify whether figures, labels, and auxiliary constructions are consistent with text claims. — Tools/Workflow: Submission pipeline step; VTBench-like judges for visual-edit correctness; comments with suggested edits. — Dependencies/Assumptions: Domain ontologies (e.g., geometry, circuits) to interpret claims; editorial oversight.
- Synthetic data factory for visual reasoning (Sectors: AI/ML, enterprise analytics) — What: Use the Data Evolution Flywheel to generate domain-specific interactive datasets (e.g., charts, process diagrams, chemical structures) for model training/testing. — Tools/Workflow: Knowledge ontology setup; co-evolution loop to enlarge concepts/tools; coordinated calibration and repair for QA; export to model training. — Dependencies/Assumptions: Seed ontologies and toolsets; compute budget; strong LMM judge availability; licensing compliance for any seed assets.
- Perception alignment fine-tune kit (Sectors: AI/ML) — What: Apply V-Perception-40K to improve point-level localization and spatial referencing for existing LMMs. — Tools/Workflow: SFT scripts; evaluation on VTBench perception and instruction-guided tasks; regression gates. — Dependencies/Assumptions: Base model access (weights, adapters); GPU capacity; reproducible training config.
- Vendor evaluation and procurement using VTBench (Sectors: government, enterprise policy, compliance) — What: Standardize evaluation of vendor LMMs for tasks requiring interactive visual reasoning (perception → guided interaction → reasoning). — Tools/Workflow: VTBench integration into RFPs; threshold scores; reporting templates showing instruction-following and edit-grounding. — Dependencies/Assumptions: Agreement on judging protocol; reproducible runners; attention to benchmark overfitting.
- Design review assistant for engineering teams (Sectors: construction/architecture, electronics, mechanical) — What: Interactive markups over CAD exports/diagrams to surface constraints, alignment issues, and measurement callouts. — Tools/Workflow: Export-to-image pipeline; templated checks (orthogonality, clearance); shared review boards. — Dependencies/Assumptions: 2D exports with adequate resolution; domain toolsets (angles, distances); human review.
- Chart/figure comprehension and QA in analytics workflows (Sectors: finance, BI, journalism) — What: Interactive chart reasoning (highlight series, add reference lines, annotate anomalies) with textual rationales. — Tools/Workflow: BI plug-ins; figure parsers; code-driven overlays; saved “inspection recipes.” — Dependencies/Assumptions: Consistent chart styles; robust OCR; dataset-level cross-checks for claims.
- Screenshot-augmented bug filing and reproduction (Sectors: software engineering) — What: Automatically annotate problem regions, expected/actual states, and reproduction steps on bug screenshots; link to logs. — Tools/Workflow: Issue tracker integration; scripted visual edits; templated CoT summaries. — Dependencies/Assumptions: Access to screenshots; privacy and PII redaction; reviewer sign-off.
Long-Term Applications
These use cases are high-value but require further research, scaling, domain validation, or safety assurance before production deployment.
- Surgical planning and radiology assistants with interactive overlays (Sectors: healthcare) — What: Draw measurement lines, regions of interest, and annotations on scans; reason about anatomical relationships over multiple views. — Tools/Workflow: DICOM integration; domain-specific toolsets and ontologies; audit logs of edits and reasoning. — Dependencies/Assumptions: Regulatory clearance; rigorous clinical validation; high-resolution perception alignment; bias and safety review.
- Vision-language co-pilots for robotics and autonomous systems (Sectors: robotics, industrial automation) — What: Interactive environment understanding with on-frame annotations to guide manipulation and navigation plans. — Tools/Workflow: On-device or edge inference; online RL adaptations; safety sandbox for tool execution. — Dependencies/Assumptions: Real-time constraints; robust perception in dynamic conditions; fail-safe policies.
- AR-based field maintenance and training (Sectors: utilities, aerospace, manufacturing) — What: Context-aware overlays (e.g., wiring traces, torque sequences) anchored to live camera views; interactive reasoning about next steps. — Tools/Workflow: AR headset integration; spatial calibration; stepwise CoT with inline visual edits. — Dependencies/Assumptions: Accurate 3D localization; controlled tool palettes; strong HMI design and safety sign-offs.
- Scientific figure and lab notebook intelligence (Sectors: pharma, materials, academia) — What: Systematically extract, annotate, and validate relationships in microscopy images, plots, and schematics; propose alternative analyses with visual evidence. — Tools/Workflow: LIMS/ELN integration; controlled vocabularies; experiment-aware edit templates; auditability. — Dependencies/Assumptions: Domain-specific ontologies; reproducibility; data governance for synthetic augmentations.
- Compliance auditing from diagrams and plans (Sectors: construction, energy, safety regulation) — What: Check plan submissions for code compliance via interactive overlays (clearances, load paths, safety zones) and reasoned reports. — Tools/Workflow: Jurisdiction-specific rules encoded as knowledge concepts; VTBench-like evaluation customized to regulations. — Dependencies/Assumptions: Legal acceptance of AI-assisted checks; expert review; version control of rulesets.
- Intelligent tutoring systems that “create to teach” (Sectors: education) — What: Knowledge-driven generation of new problems, diagrams, and multi-step solutions calibrated to learner profiles; interactive hints via visual edits. — Tools/Workflow: Curriculum ontologies; difficulty progression via the flywheel; per-learner reinforcement signals. — Dependencies/Assumptions: Pedagogical validation; bias and fairness controls; privacy-preserving analytics.
- Visual agent platforms for enterprise workflows (Sectors: horizontal enterprise) — What: Multi-app agents that read diagrams, annotate screenshots, and coordinate with ticketing/docs, under tool-usage policies. — Tools/Workflow: Policy-constrained tool execution; standardized visual tool APIs; observability and rollback of edits. — Dependencies/Assumptions: Enterprise IAM/SSO; SOC2/ISO controls; robust red-teaming for code-execution safety.
- Cross-modal interactive editing for video and 3D (Sectors: media, CAD/CAM, geospatial) — What: Extend image-interactive reasoning to temporal and 3D contexts (e.g., track features across frames, annotate 3D meshes or maps). — Tools/Workflow: Spatiotemporal toolkits; SLAM/pose alignment; streaming inference. — Dependencies/Assumptions: Data/model scaling; stable temporal grounding; new benchmarks beyond VTBench.
- Safety and standards for code-executing multimodal models (Sectors: policy, standardization) — What: Governance frameworks, safe-execution profiles, and certification suites based on benchmarks like VTBench for visual edit correctness. — Tools/Workflow: Reference sandboxes; standardized reward/penalty regimes; disclosure of tool palettes and logs. — Dependencies/Assumptions: Multi-stakeholder consensus; interoperability specs; third-party auditing.
- Domain-specific synthetic data ecosystems (Sectors: finance, legaltech, engineering) — What: Flywheel-driven data synthesis for niche visual reasoning (e.g., ledger screenshots, circuit diagrams, piping and instrumentation diagrams). — Tools/Workflow: Ontology bootstrapping; co-evolution of tools and tasks; progressive difficulty expansion with expert-in-the-loop validation. — Dependencies/Assumptions: IP/licensing clarity; expert calibration for quality; guardrails against error propagation.
- On-device interactive vision reasoning (Sectors: mobile, IoT, edge) — What: Privacy-preserving assistants that annotate and reason over images locally for field tasks or consumer use. — Tools/Workflow: 7B-class or smaller quantized models; optimized visual tool runtimes; ephemeral execution sandboxes. — Dependencies/Assumptions: Model compression without losing perceptual grounding; thermal and latency constraints.
- Generalized programmatic visual tooling marketplaces (Sectors: software platforms) — What: Ecosystems where tool providers publish safe visual operations (measurement, segmentation, OCR) that LMMs orchestrate during reasoning. — Tools/Workflow: Tool schemas, permissions, and metering; audit logs; RL fine-tuning on tool orchestration. — Dependencies/Assumptions: Secure APIs; standardized interfaces; abuse prevention and monitoring.
Notes on Feasibility and Cross-Cutting Dependencies
- Safety-critical deployment requires domain validation, robust perception, and audit trails of code and visual edits.
- The approach depends on a secure, sandboxed executor for model-generated code; policies must restrict file/network access.
- Data quality hinges on the Data Evolution Flywheel’s calibration and repair loop; expert-in-the-loop improves reliability for specialized domains.
- Performance varies across tasks; early deployments should include human oversight and clear error boundaries.
- Integration with existing tools (OCR, CAD/CAE, BI platforms) and domain ontologies is a key enabler for practical utility.
Collections
Sign up for free to add this paper to one or more collections.