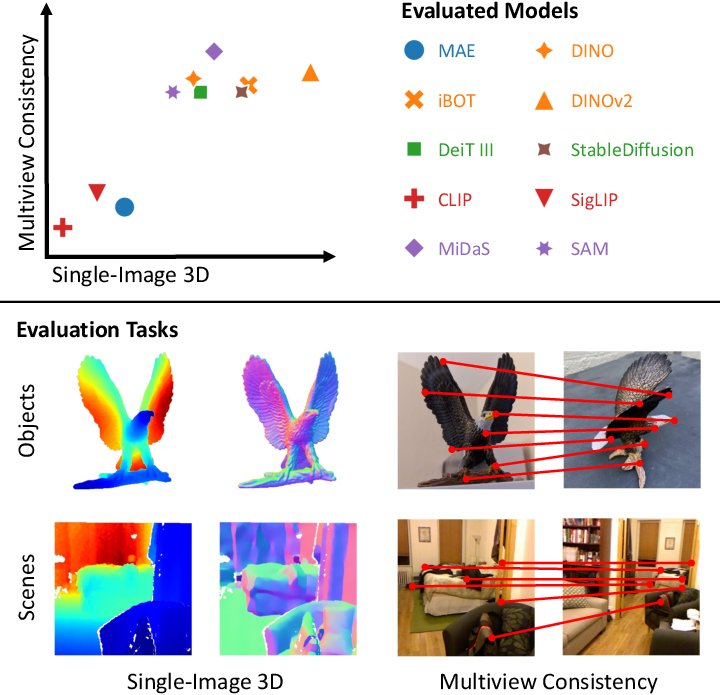
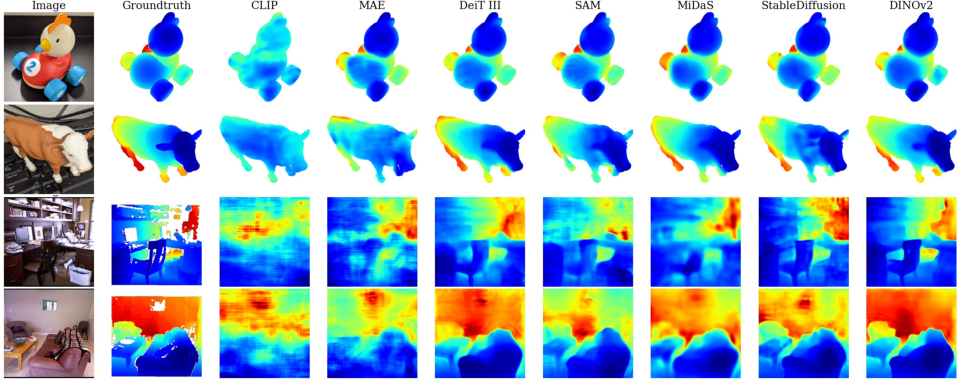
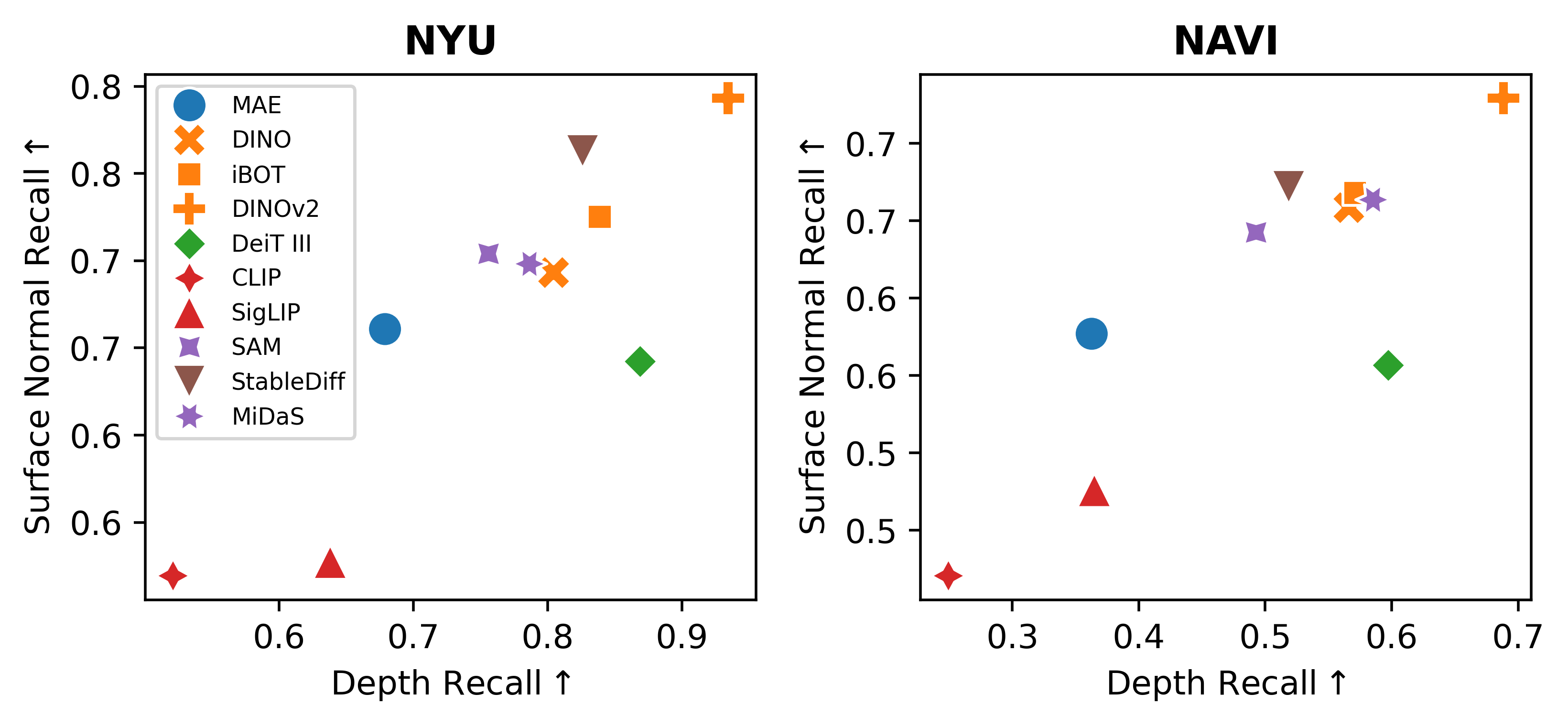
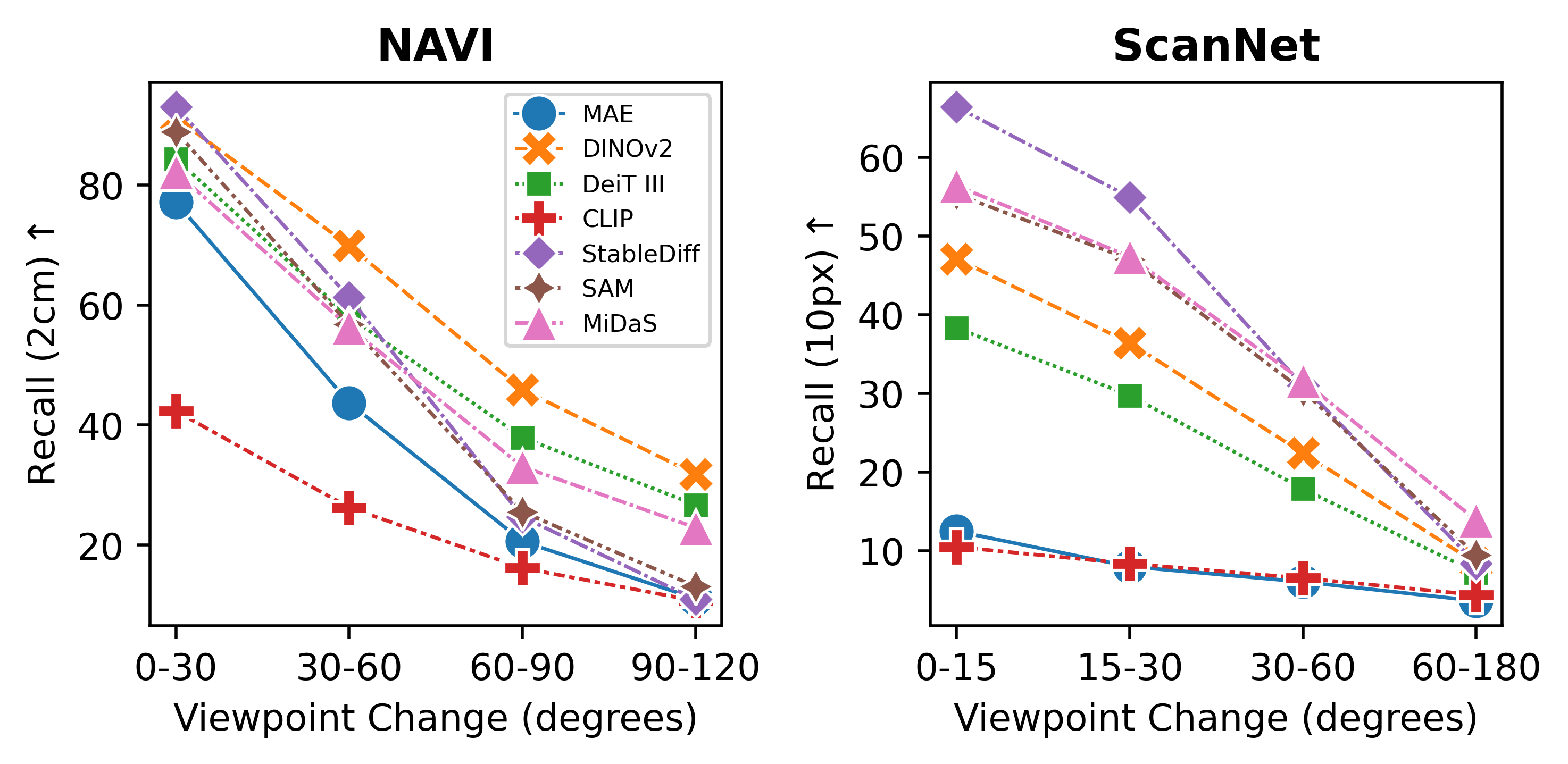
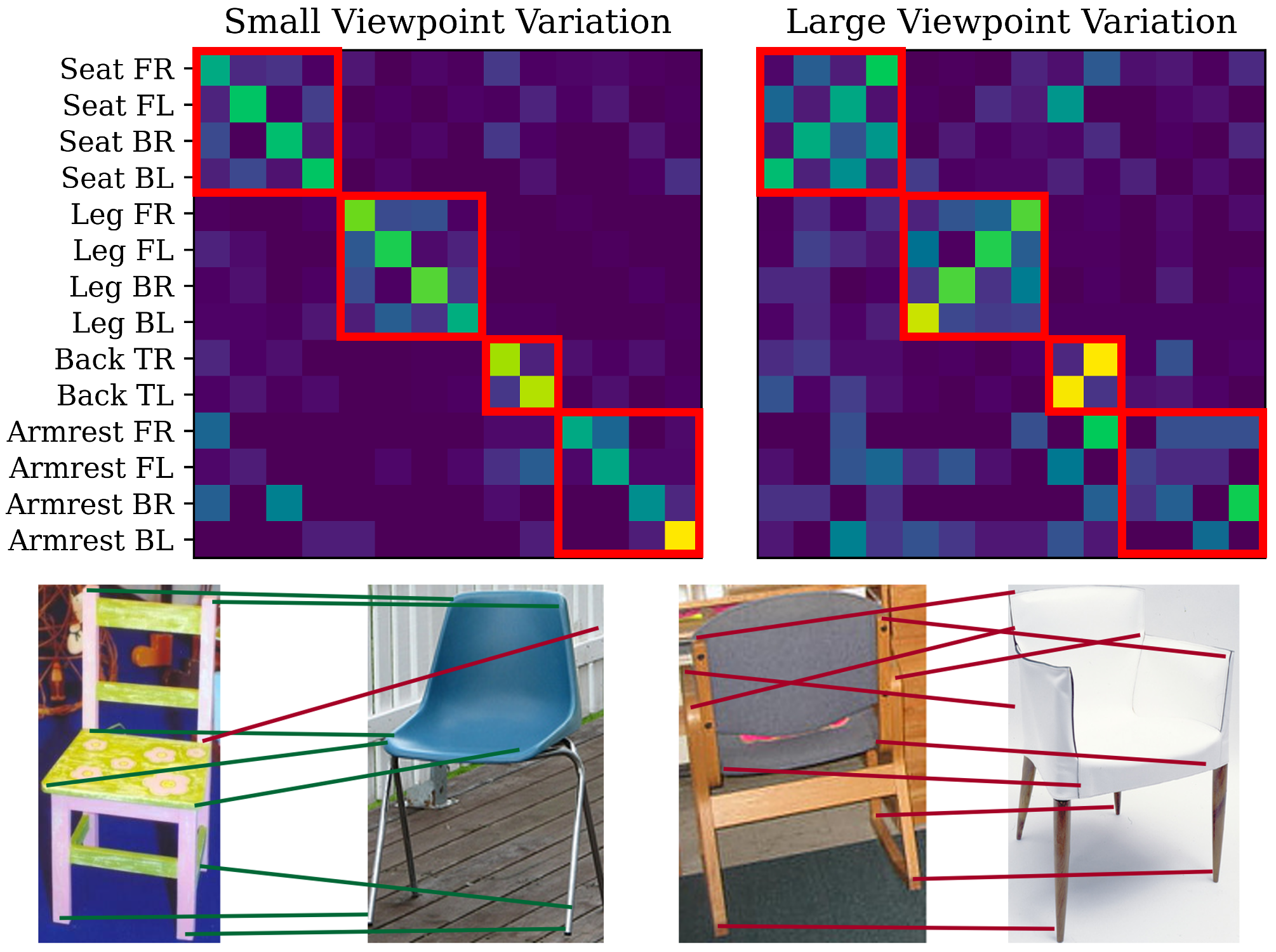
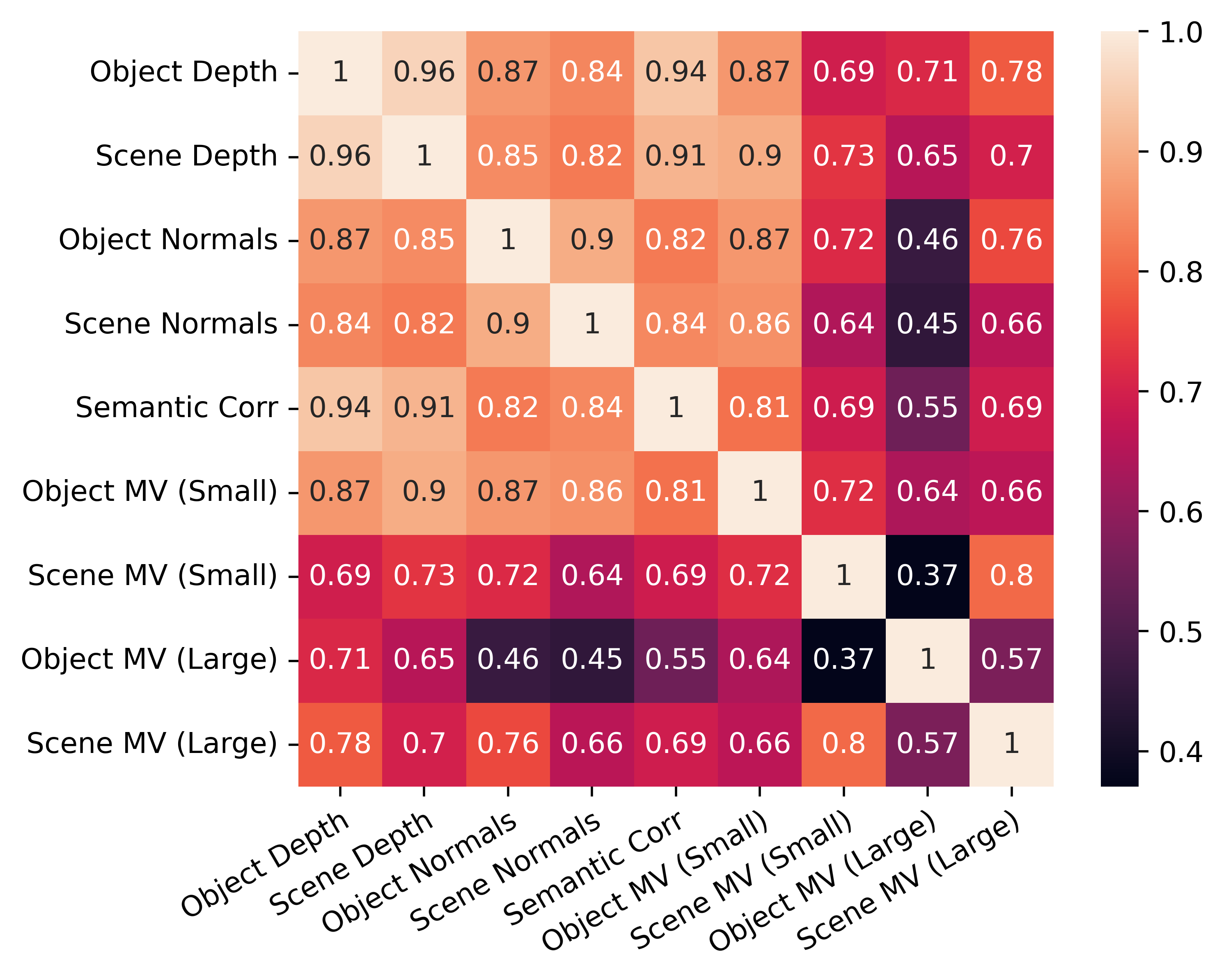
Probing the 3D Awareness of Visual Foundation Models
Abstract: Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
- Deep vit features as dense visual descriptors. arXiv preprint arXiv:2112.05814, 2021.
- Estimating and exploiting the aleatoric uncertainty in surface normal estimation. In ICCV, 2021.
- Shape matching and object recognition using low distortion correspondences. In CVPR, pages 26–33. Citeseer, 2005.
- Adabins: Depth estimation using adaptive bins. In CVPR, 2021.
- Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv preprint arXiv:2302.12288, 2023.
- Stylegan knows normal, depth, albedo, and more. arXiv preprint arXiv:2306.00987, 2023.
- Thomas O. Binford. Visual perception by computer. In Proceedings of the IEEE Conference on Systems and Control, 1971.
- Rodney A Brooks. Symbolic reasoning among 3-d models and 2-d images. Artificial intelligence, 17(1-3):285–348, 1981.
- Emerging properties in self-supervised vision transformers. In IEEE Conf. Comput. Vis. Pattern Recog., 2021.
- Muse: Text-to-image generation via masked generative transformers. In ICML, 2023.
- Return of the devil in the details: delving deep into convolutional nets. In BMVC, 2014.
- Beyond surface statistics: Scene representations in a latent diffusion model. arXiv preprint arXiv:2306.05720, 2023.
- Scannet: Richly-annotated 3d reconstructions of indoor scenes. In CVPR, 2017.
- Vision transformers need registers. arXiv preprint arXiv:2309.16588, 2023.
- An image is worth 16x16 words: Transformers for image recognition at scale. In Int. Conf. Learn. Represent., 2020.
- Generative models: What do they know? do they know things? let’s find out! arXiv, 2023.
- Depth map prediction from a single image using a multi-scale deep network. In NeruIPS, 2014.
- Bootstrap Your Own Correspondences. In ICCV, 2021.
- UnsupervisedR&R: Unsupervised Point Cloud Registration via Differentiable Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7129–7139, 2021.
- Learning Visual Representations via Language-Guided Sampling. In CVPR, 2023.
- The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88(2):303–338, 2010.
- David Fouhey. Factoring Scenes into 3D Structure and Style. PhD thesis, Carnegie Mellon University, Pittsburgh, PA, 2016.
- Single image 3D without a single 3D image. In ICCV, 2015.
- Battle of the backbones: A large-scale comparison of pretrained models across computer vision tasks. In NeurIPS Datasets and Benchmarks Track, 2023.
- Zero-shot category-level object pose estimation. In ECCV, 2022.
- Scaling and benchmarking self-supervised visual representation learning. In ICCV, 2019.
- Asic: Aligning sparse in-the-wild image collections. arXiv preprint arXiv:2303.16201, 2023.
- Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, pages 1026–1034, 2015.
- Masked autoencoders are scalable vision learners. In CVPR, 2022.
- Unsupervised semantic correspondence using stable diffusion. arXiv preprint arXiv:2305.15581, 2023.
- OpenCLIP, 2021.
- Navi: Category-agnostic image collections with high-quality 3d shape and pose annotations. In NeurIPS Datasets and Benchmarks Track, 2023.
- Repurposing diffusion-based image generators for monocular depth estimation. arXiv preprint arXiv:2312.02145, 2023.
- Dag: Depth-aware guidance with denoising diffusion probabilistic models. arXiv preprint arXiv:2212.08861, 2022.
- Adam: A method for stochastic optimization. In ICLR, 2015.
- Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- The singularities of the visual mapping. Biological cybernetics, 24(1):51–59, 1976.
- The internal representation of solid shape with respect to vision. Biological cybernetics, 32(4):211–216, 1979.
- Surface shape and curvature scales. Image and vision computing, 10(8):557–564, 1992.
- Pictorial surface attitude and local depth comparisons. Perception & Psychophysics, 58(2):163–173, 1996.
- Do better imagenet models transfer better? In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2661–2671, 2019.
- Fine-tuning can distort pretrained features and underperform out-of-distribution. In International Conference on Learning Representations, 2022.
- Discriminatively trained dense surface normal estimation. In ECCV, 2014.
- Does clip bind concepts? probing compositionality in large image models. arXiv preprint arXiv:2212.10537, 2022.
- Your diffusion model is secretly a zero-shot classifier. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2206–2217, 2023.
- Align before fuse: Vision and language representation learning with momentum distillation. In Advances in Neural Information Processing Systems, 2021.
- Megadepth: Learning single-view depth prediction from internet photos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018.
- Localization vs. semantics: Visual representations in unimodal and multimodal models. In EACL, 2024.
- On the variance of the adaptive learning rate and beyond. In ICLR, 2020.
- Zero-1-to-3: Zero-shot one image to 3d object. In ICCV, 2023.
- A convnet for the 2020s. In CVPR, 2022.
- SGDR: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- David G Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 2004.
- Diffusion hyperfeatures: Searching through time and space for semantic correspondence. arXiv, 2023.
- A computational theory of human stereo vision. Royal Society of London, 1979.
- Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localization. In IEEE Conf. Comput. Vis. Pattern Recog., 2022.
- Spair-71k: A large-scale benchmark for semantic correspondence. arXiv prepreint arXiv:1908.10543, 2019.
- Slip: Self-supervision meets language-image pre-training. In Eur. Conf. Comput. Vis., 2022.
- Visual discrimination of local surface structure: Slant, tilt, and curvedness. Vision research, 46(6-7):1057–1069, 2006.
- DINOv2: Learning Robust Visual Features without Supervision, 2023.
- idisc: Internal discretization for monocular depth estimation. In CVPR, 2023.
- Dreamfusion: Text-to-3d using 2d diffusion. In ICLR, 2022.
- Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors. arXiv preprint arXiv:2306.17843, 2023.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Learning transferable visual models from natural language supervision. In Int. Conf. Machine Learning, 2021.
- Dreambooth3d: Subject-driven text-to-3d generation. ICCV, 2023.
- Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. TPAMI, 2020.
- Vision transformers for dense prediction. In ICCV, 2021.
- High-resolution image synthesis with latent diffusion models. In CVPR, pages 10684–10695, 2022.
- Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022.
- Shadows don’t lie and lines can’t bend! generative models don’t know projective geometry…for now. 2023.
- Superglue: Learning feature matching with graph neural networks. In CVPR, 2020.
- Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Grad-cam: Visual explanations from deep networks via gradient-based localization. In Int. Conf. Comput. Vis., 2017.
- Second-order isomorphism of internal representations: Shapes of states. Cognitive psychology, 1(1):1–17, 1970.
- Mental rotation of three-dimensional objects. Science, 171(3972):701–703, 1971.
- Mvdream: Multi-view diffusion for 3d generation. arXiv preprint arXiv:2308.16512, 2023.
- Indoor segmentation and support inference from rgbd images. In ECCV, 2012.
- Beyond core knowledge: Natural geometry. Cognitive science, 34(5):863–884, 2010.
- How to train your vit? data, augmentation, and regularization in vision transformers. arXiv preprint arXiv:2106.10270, 2021.
- Reclip: A strong zero-shot baseline for referring expression comprehension. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022.
- LoFTR: Detector-free local feature matching with transformers. CVPR, 2021.
- Emergent correspondence from image diffusion. arXiv preprint arXiv:2306.03881, 2023.
- What do single-view 3d reconstruction networks learn? In CVPR, 2019.
- Winoground: Probing vision and language models for visio-linguistic compositionality. In CVPR, 2022.
- Deit III: Revenge of the ViT. In ECCV, 2022.
- Teaching matters: Investigating the role of supervision in vision transformers. In IEEE Conf. Comput. Vis. Pattern Recog., 2023.
- Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In CVPR, 2023.
- Ross Wightman. Pytorch image models. https://github.com/rwightman/pytorch-image-models, 2019.
- Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, 2020. Association for Computational Linguistics.
- Convnext v2: Co-designing and scaling convnets with masked autoencoders. In CVPR, 2023.
- Beyond pascal: A benchmark for 3d object detection in the wild. In IEEE Winter Conference on Applications of Computer Vision (WACV), 2014.
- Neurallift-360: Lifting an in-the-wild 2d photo to a 3d object with 360deg views. In CVPR, 2023a.
- Demystifying clip data. arXiv preprint arXiv:2309.16671, 2023b.
- ODISE: Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models. In CVPR, 2023c.
- Metric3d: Towards zero-shot metric 3d prediction from a single image. In ICCV, 2023.
- Sigmoid loss for language image pre-training. ICCV, 2023.
- What does stable diffusion know about the 3d scene?, 2023.
- A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence. In NeurIPS, 2023a.
- Self-supervised geometric correspondence for category-level 6d object pose estimation in the wild. In ICLR, 2023b.
- Unleashing text-to-image diffusion models for visual perception. arXiv preprint arXiv:2303.02153, 2023.
- ibot: Image bert pre-training with online tokenizer. International Conference on Learning Representations (ICLR), 2022.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

