- The paper's main contribution is a unified framework that probes 3D awareness in VFMs by extracting 3D Gaussian parameters from pre-trained features.
- It employs a shallow MLP readout and multi-view photometric loss to separately evaluate texture and geometry, ensuring robust novel view synthesis.
- Experimental results across diverse datasets show that improved 3D metrics correlate strongly with synthesis quality, guiding future VFM enhancements.
Feat2GS: Probing Visual Foundation Models with Gaussian Splatting
This paper introduces Feat2GS, a novel framework designed to probe the 3D awareness of visual foundation models (VFMs) by leveraging 3D Gaussian Splatting. This approach addresses the critical need for a unified methodology to evaluate how well VFMs, trained primarily on 2D image data, understand and represent the 3D world. The method evaluates both texture and geometry awareness through novel view synthesis, offering a way to benchmark VFMs without requiring 3D ground truth data.
Methodology and Implementation
Feat2GS operates by extracting features from input images using pre-trained VFMs. A shallow MLP readout layer then regresses the parameters of 3D Gaussians from these features. Multi-view photometric loss is used to minimize the visual difference between the renderings and the input images. The 3DGS parameters are disentangled into geometry (x,α,Σ) and texture (c), enabling separate analysis of texture and geometry awareness. Camera poses are initialized using DUSt3R and refined with photometric loss to handle sparse and uncalibrated casual images. Three probing schemes are introduced:
- Geometry probing: Reads out geometric parameters and optimizes textural parameters.
- Texture probing: Reads out textural parameters and optimizes geometric parameters.
- All probing: Reads out all Gaussian parameters.
\begin{table}[]
\begin{tabular}{ll}
Component & Implementation Details \
\hline
Feature Extraction & Utilizes pre-trained VFMs like DINOv2, MAE, and others \
Readout Layer & 2-layer MLP with 256 units per layer and ReLU activation \
Optimization & Adam optimizer, photometric loss \
Camera Pose & Initialized with DUSt3R, refined with photometric loss \
Evaluation Datasets & LLFF, DTU, DL3DV, Casual, MipNeRF360, MVimgNet, Tanks and Temples \
Metrics & PSNR, SSIM, LPIPS for novel view synthesis, Accuracy, Completeness, and Distance for 3D point cloud regression (on DTU dataset for validation)
\end{tabular}
\caption{Implementation details of Feat2GS.}
\end{table}
The parameters of 3DGS, grouped into geometry (x,α,Σ) and texture (c), enable separate analysis of VFM's texture and geometry awareness.
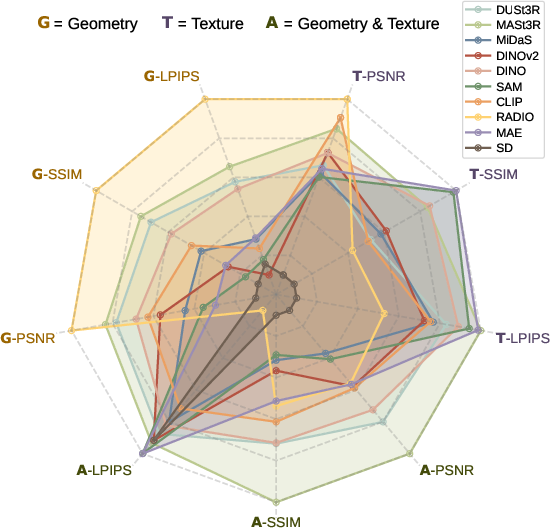
Figure 1: {\bf Texture+Geometry probing of mainstream VFMs.} Normalized average metrics for novel view synthesis (NVS) across six datasets are plotted on axes, with higher values away from the center indicating better performance.
Experimental Design and Results
The experiments involve a diverse set of VFMs, including those trained on 2D and 3D data, with varying supervision strategies. A wide range of multi-view datasets is used to evaluate the VFMs under different GTA probing modes. Key findings include:
- VFMs exhibit varying performance across datasets, emphasizing the importance of data diversity.
- Texture awareness is a general limitation of VFMs.
- Masked image reconstruction pre-training improves texture awareness.
- Geometry awareness benefits significantly from training on 3D data, especially point maps.
- Model ensembling, through feature concatenation, enhances performance.
The paper validates that novel view synthesis correlates strongly with 3D metrics, confirming its reliability as a proxy task. The effectiveness of {Feat2GS is demonstrated through superior performance compared to existing state-of-the-art methods like InstantSplat in novel view synthesis tasks.

Figure 2: {\bf Qualitative Examples.} We compare novel view renderings across VFM features.
Implications and Future Directions
The Feat2GS framework offers significant insights into the capabilities and limitations of VFMs, guiding the development of more 3D-aware models. The study suggests that predicting 3D Gaussians from various views in a canonical space and training the model with photometric loss is a promising strategy for developing 3D VFMs. Future work may focus on:
- Reducing the reliance on external stereo reconstruction for camera pose initialization.
- Extending the framework to handle long-term, in-the-wild datasets.
- Adapting {Feat2GS for dynamic scenes by integrating 4D Gaussian Splatting.

Figure 3: {\bf Novel View Synthesis as Proxy Task to Assess 3D.} We present qualitative examples from the DTU dataset, including NVS, Pointcloud (readout 3DGS positions), Accuracy (smallest distance from a readout point to ground-truth), Completeness (smallest distance from a ground-truth point to a readout point), and Distance (based on ground-truth point matching).

Figure 4: {\bf GTA Modes Comparison for the Same Region.} We present novel view synthesis of GTA modes using RADIO features.
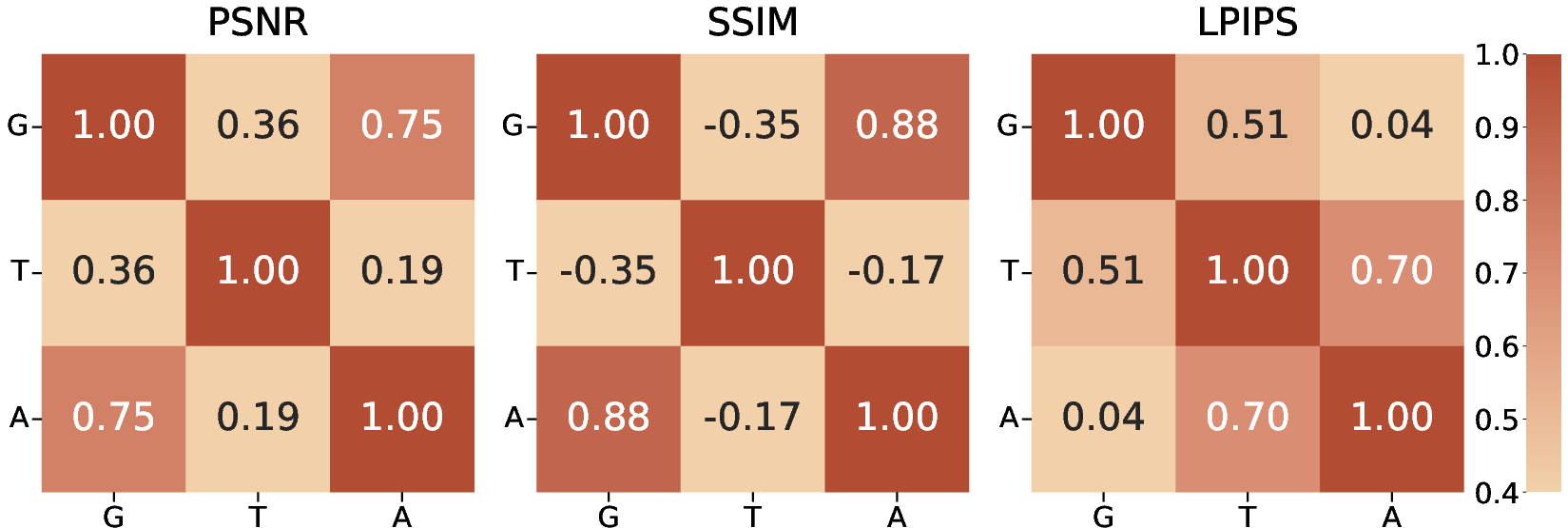
Figure 5: {\bf Performance Correlations of GTA across All Datasets.} The correlates strongly with in PSNR and SSIM (primarily reflect structural consistency), and is closely related to in LPIPS (commonly used to assess image sharpness), suggesting an optimal depends on both high-performing Geometry and .
Conclusion
Feat2GS provides a unified framework to probe the 3D awareness of VFMs, revealing crucial insights into their geometry and texture understanding. The method effectively harnesses VFMs for novel view synthesis, demonstrating the potential of 3D Gaussian Splatting as a tool for evaluating and enhancing visual foundation models. This work advances VFM research and drives progress in 3D vision by offering a versatile framework for future model exploration.