- The paper introduces the largest annotated NER dataset for 20 African languages, enabling robust cross-lingual transfer and zero-shot learning improvements.
- It demonstrates that models like AfroXLM-R, pre-trained on African corpora, deliver significant performance gains, with up to a 14 F1 point increase in zero-shot settings.
- It reveals that using typologically and geographically similar African languages as source languages greatly enhances transfer learning efficiency for low-resource settings.
Africa-centric Transfer Learning for Named Entity Recognition: MasakhaNER 2.0
Introduction
The MasakhaNER 2.0 paper presents an expansive effort to address the longstanding challenge of underrepresented African languages in NLP research, specifically focusing on Named Entity Recognition (NER). The effort culminated in the creation of the largest annotated NER dataset across 20 African languages, collectively known as MasakhaNER 2.0. These languages cover a diverse range of linguistic properties and geographic distributions, which makes this compilation pivotal as a benchmark for evaluating cross-lingual transfer methods in NLP.
Corpus Creation and Characteristics
To fill the existing gaps, the research team created a dataset encompassing 20 languages, expanding the scope from the previous MasakhaNER 1.0 that included only ten languages. The expansion notably covers Southern African languages, which exhibit unique syntactic and morphological features not present in the MasakhaNER 1.0 corpus. Each language dataset consists of annotated news articles sourced from various monolingual news domains or through translations to ensure linguistic diversity and rich named entity annotations (Figure 1).
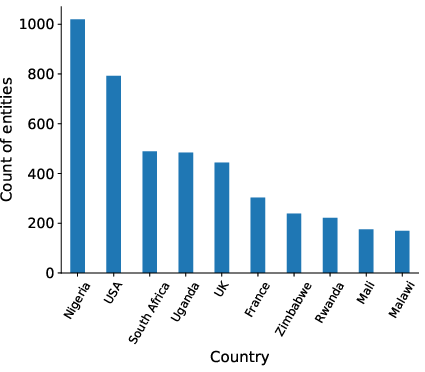
Figure 1: Top-10 countries with the largest number of entities in MasakhaNER 2.0.
A meticulous annotation process was adopted, involving native speakers to ensure high-quality named entity annotations across four categories: PER (Personal names), LOC (Locations), ORG (Organizations), and DATE (Date and Time). The research also emphasized ensuring linguistic richness by preserving distinct syntactic features like tonality and noun prefixes, which are predominantly found in African languages.
Evaluation and Baseline Models
The paper evaluates the efficacy of several multilingual PLMs by fine-tuning them for NER tasks across the MasakhaNER 2.0 corpus. Baseline experiments show that models like AfroXLM-R, which are pre-trained on African language corpora, demonstrate enhanced performance (Figure 2). This results in a noteworthy increase in F1 scores, particularly when models are fine-tuned on languages typologically similar to the target language.
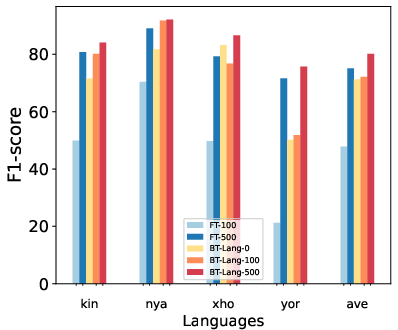
Figure 2: Sample Efficiency Results for 100 and 500 samples in the target language, model fine-tuned from a PLM (e.g. FT-100 -- trained on 100 samples from the target language) or fine-tuned from the best transfer language NER model (e.g. BT-Lang-0 -- trained on 0 samples from the target language or zero-shot).
The evaluation results substantiate that AfroXLM-R-large, with a significant F1 score increase, outperformed other multilingual PLMs, marking a significant advancement in zero-shot learning approaches for African languages.
Cross-Lingual Transfer Analysis
A substantial part of the research focused on analyzing cross-lingual transfer effectiveness, primarily in zero-shot settings. Given the typological and geographical variability among African languages, selecting the optimal source language for transfer learning is essential. The experiments reveal that geographic distance and entity overlap significantly influence transfer efficacy, as amplified through the use of LangRank models that integrate these factors to predict the best source languages for transfer (Figure 3).
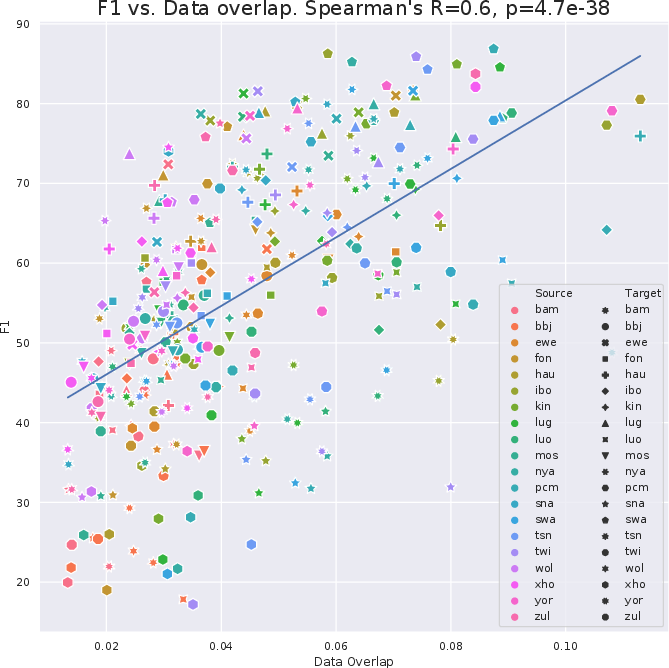
Figure 3: The correlation between the data overlap and F1 transfer performance.
MasakhaNER 2.0 illustrates that opting for a typologically and geographically proximate language yields significant improvements in NER model transfer performance for low-resource African languages. Specifically, the study observed that while English is often used as a source language, its divergence from African languages often results in suboptimal transfer efficiency. Instead, using another African language, when feasible, typically improves the zero-shot transfer results by around 14 F1 points, showcasing the advantage of Africa-centric source languages.
Conclusion
MasakhaNER 2.0 serves as a crucial resource for advancing Africa-centric NLP research, addressing a critical gap in annotated datasets for African languages. With comprehensive coverage across 20 languages and strong baseline results, it offers a reliable benchmark for evaluating and improving NER models. The insights into cross-lingual transfer highlight the necessity to leverage typological and geographical similarities for optimizing transfer learning in heterogeneous linguistic settings. These findings lay a foundational framework for future work aiming at extending multilingual models and algorithms to better support the linguistic diversity of African languages.


