- The paper introduces the Sahara benchmark to systematically evaluate LLM performance on 517 African languages.
- It demonstrates that historical language policies and data inequities significantly hamper NLP performance on indigenous languages.
- Closed, larger models outperform open ones, though challenges remain in language identification and translation.
The paper "Where Are We? Evaluating LLM Performance on African Languages" (2502.19582) addresses the substantial underrepresentation of African languages in NLP research. It highlights how historical language policies have favored foreign languages over indigenous ones, resulting in significant data inequities. These disparities affect the performance of LLMs on African languages. The study introduces a comprehensive benchmark, Sahara, to systematically evaluate LLM performance across a wide range of African languages, providing insights into policy-induced data variations and proposing recommendations for inclusive data practices and policy reforms.
Introduction
Despite Africa's rich linguistic diversity, many indigenous languages remain marginalized in NLP research. This is largely a consequence of historical policies that have prioritized foreign languages, leading to a lack of accessible, high-quality datasets for indigenous languages. While initiatives like Masakhane and platforms like HuggingFace have begun addressing these gaps, progress remains uneven. The study undertakes an extensive empirical evaluation of LLMs using a benchmark named Sahara, crafted from publicly accessible datasets, to assess how existing language policies influence model performance across Africa's diverse linguistic landscape.
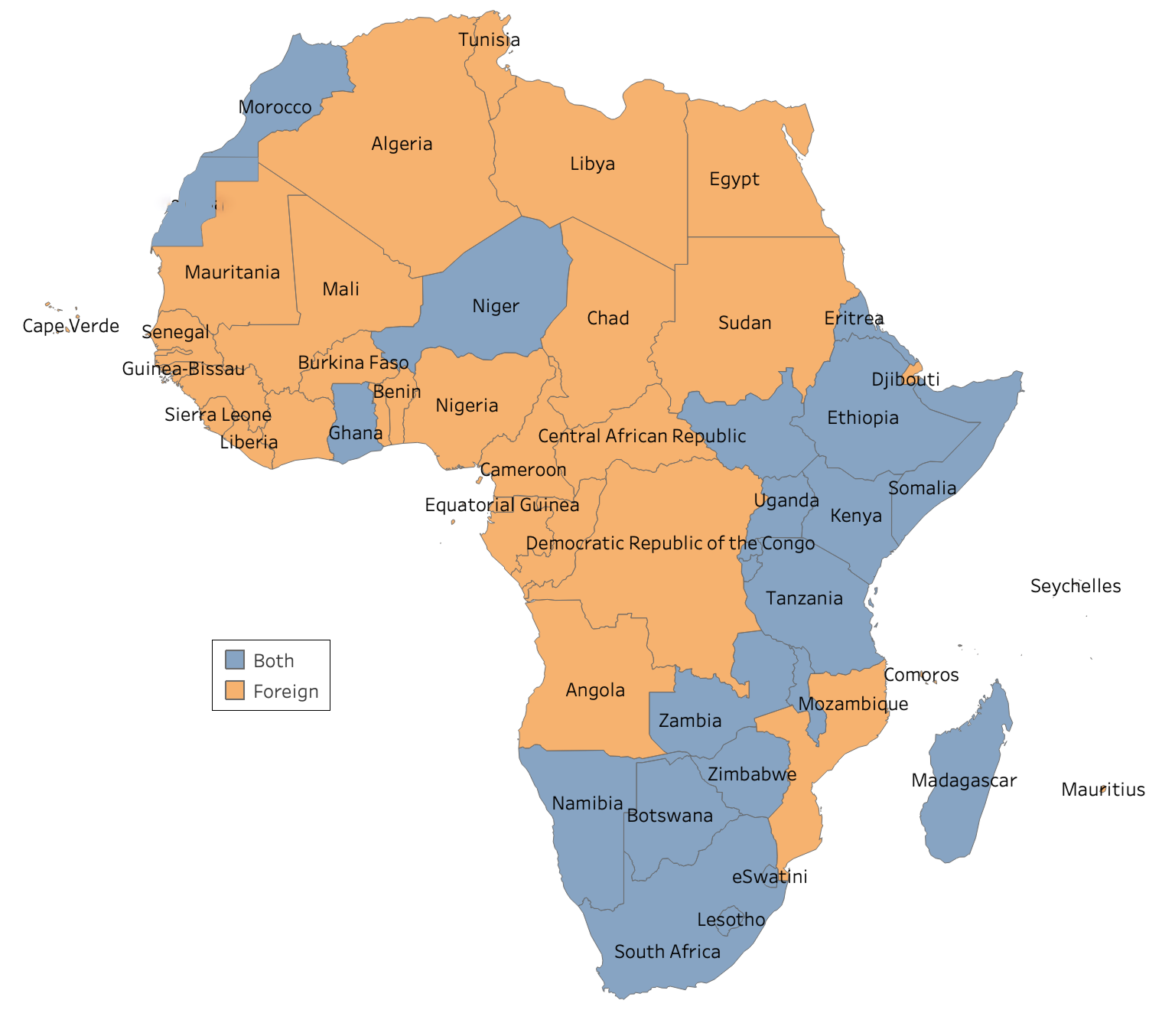
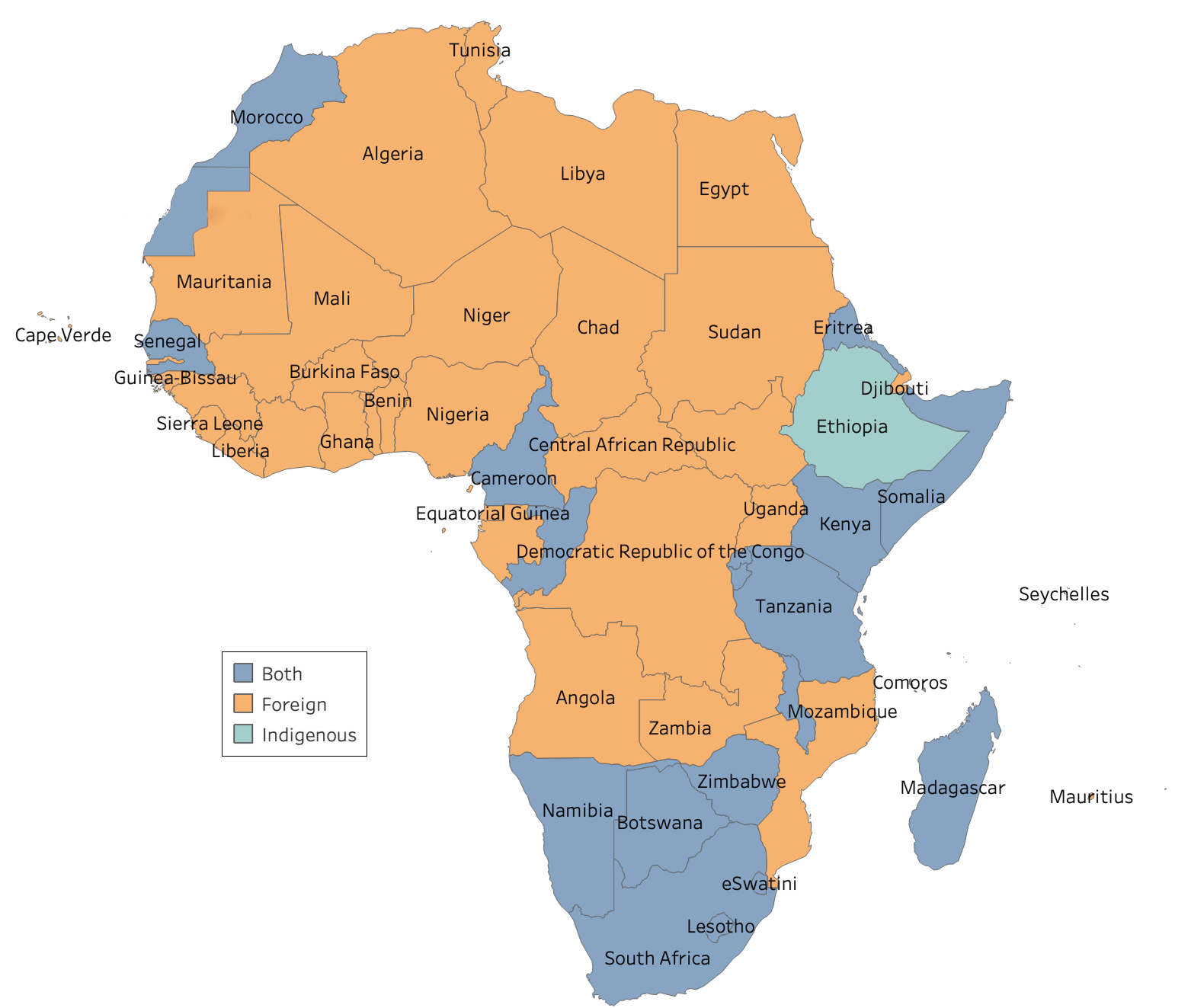
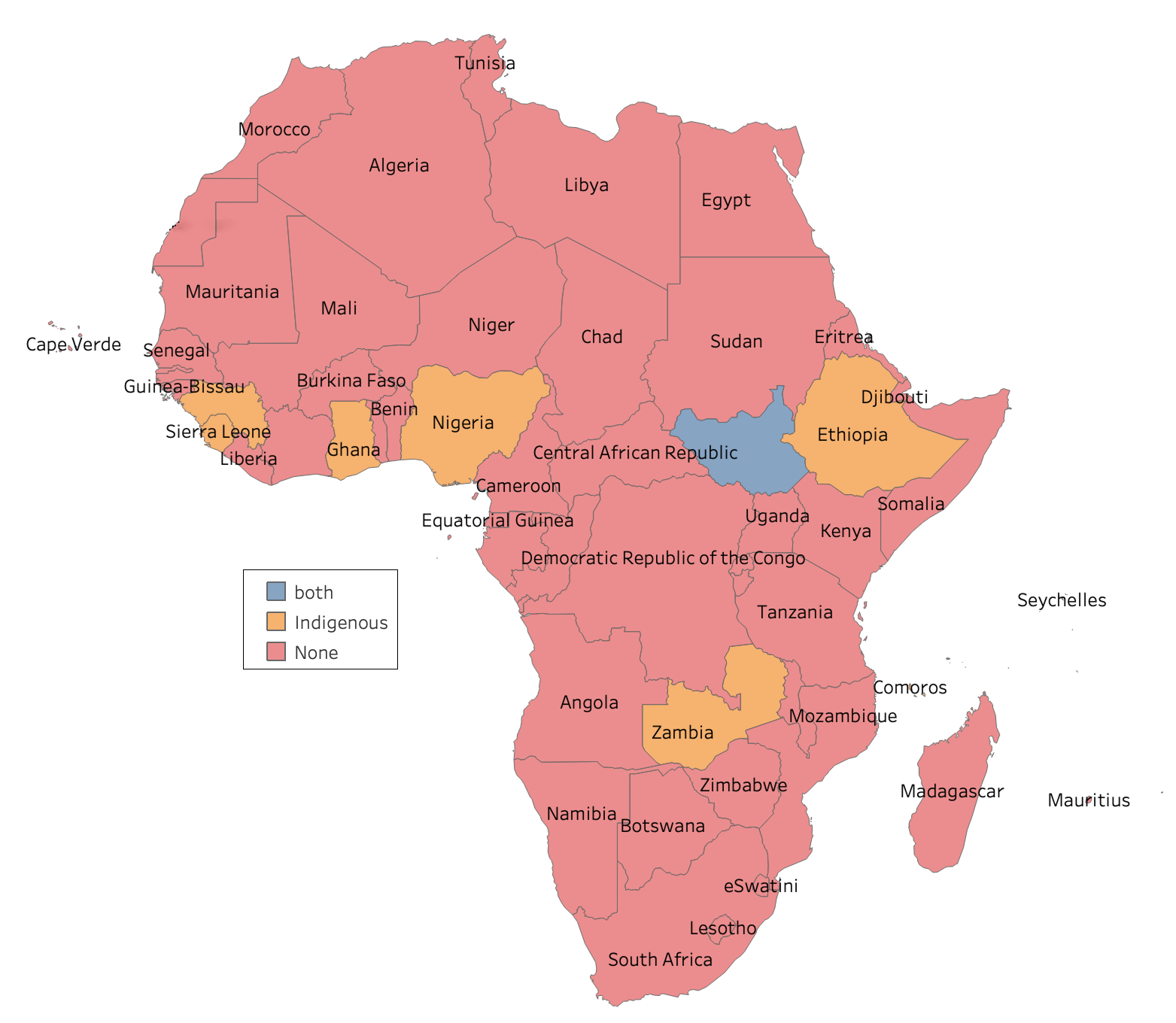
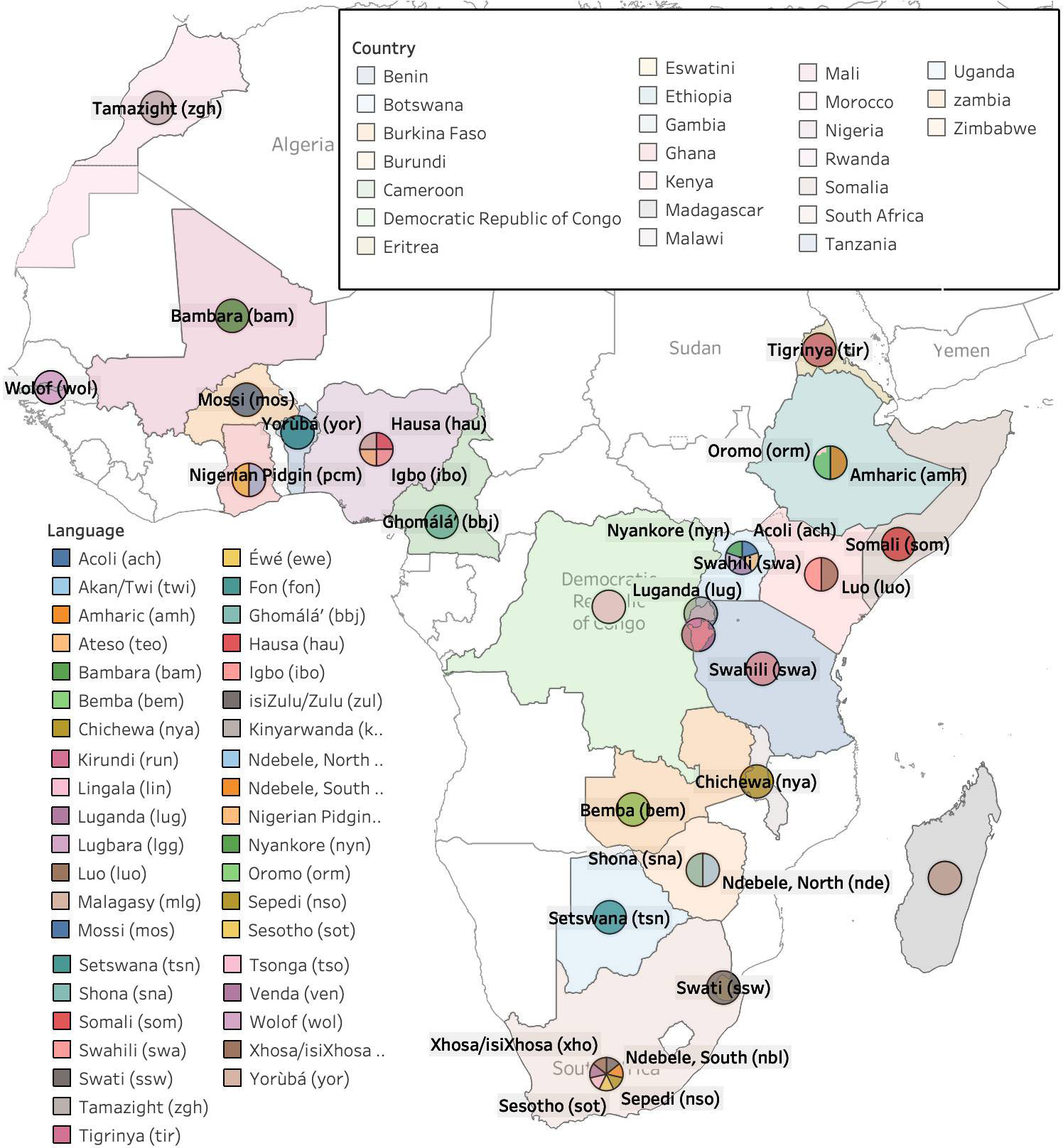
Figure 1: Maps of Africa showing the languages covered in this work and the language policies across Africa. The term "Both" refers to Indigenous and foreign languages combined.
Language Policies in Africa
Across the continent, the predominant approach to multilingualism has been the adoption of foreign languages for official use, often relegating indigenous languages to a symbolic role. For instance, in Nigeria, English is the official language, with only a fraction of indigenous languages receiving regional recognition. Similar patterns are observed in countries like Tanzania and Kenya. These policies exacerbate the underrepresentation of indigenous languages in formal and digital domains. As shown in Figure 1, language policies significantly impact the availability and performance of NLP datasets across Africa.
Efforts to develop NLP for African languages have been hampered by data scarcity and uneven model performance. Initiatives like MasakhaNER and IROKOBench have expanded datasets and introduced benchmarks for evaluating LLMs on African languages. However, these efforts reveal pronounced performance gaps. Language policies play a crucial role, with official status often leading to better resource availability. Despite improvements through projects like Meta AI's NLLB, performance disparities persist, highlighting the need for continued investment in dataset curation and model development tailored to Africa's linguistic diversity.
Sahara Benchmark
The Sahara benchmark is a comprehensive tool for evaluating African NLP, covering a wide range of languages and tasks. It supports diverse NLP tasks, including text classification, text generation, and token-level classification. The benchmark aims to enable accurate analysis and evaluation of LLM performance across 517 African languages, using existing datasets to facilitate multilingual assessment.

Figure 2: Distribution of languages across different clusters. Each bar represents the number of datasets a language appears in, categorized into the clusters.
Experiments and Results
The study evaluates several instruction-based LLMs, including Claude-3.5-Sonnet, on the Sahara benchmark. Results indicate that closed models like Claude-3.5-Sonnet and GPT-4 generally outperform open models across tasks. However, language identification remains challenging, with limited model understanding for many African languages. Larger models perform better, but disparities in translation tasks persist, particularly with African languages as the target.
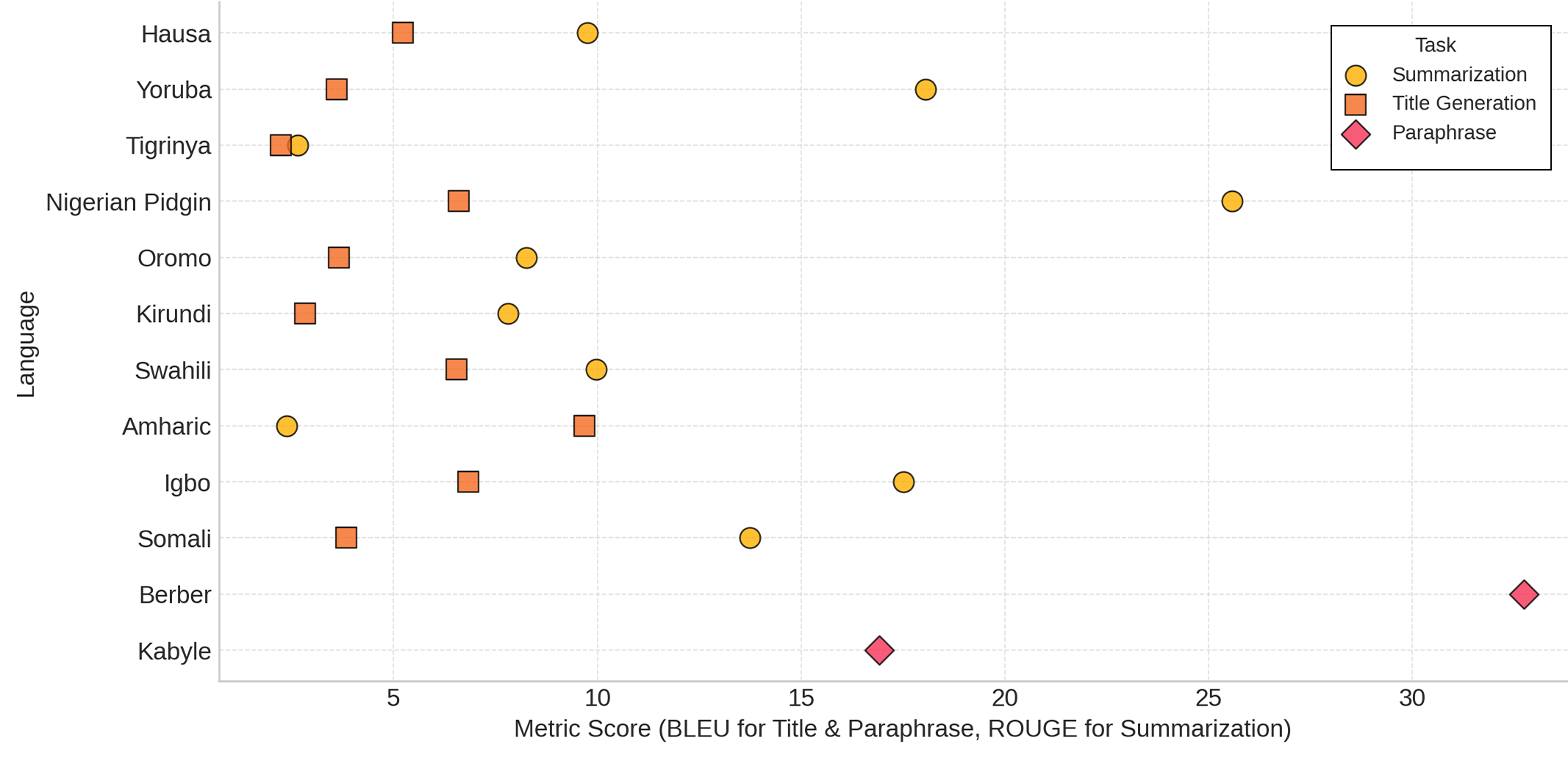
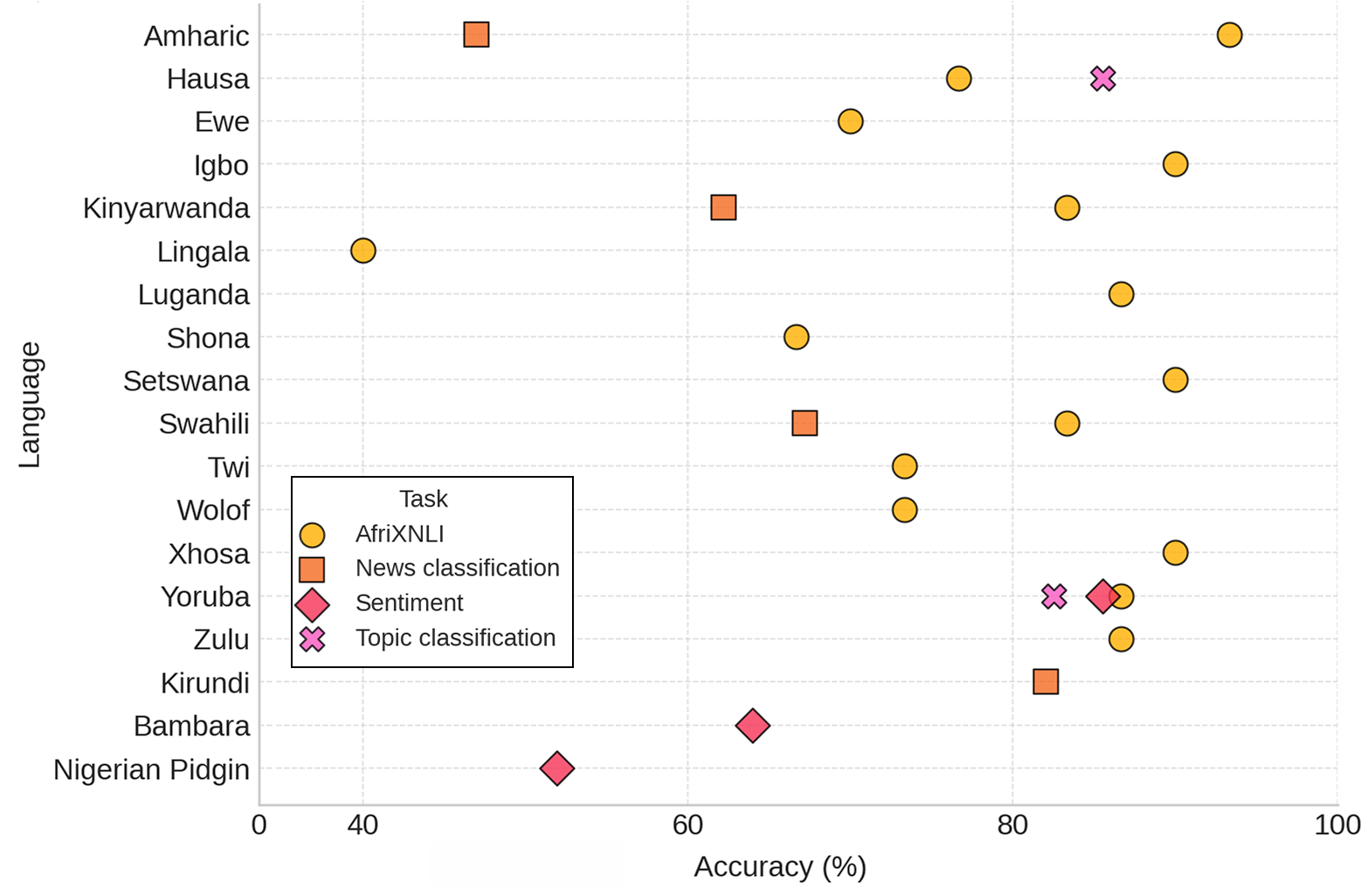
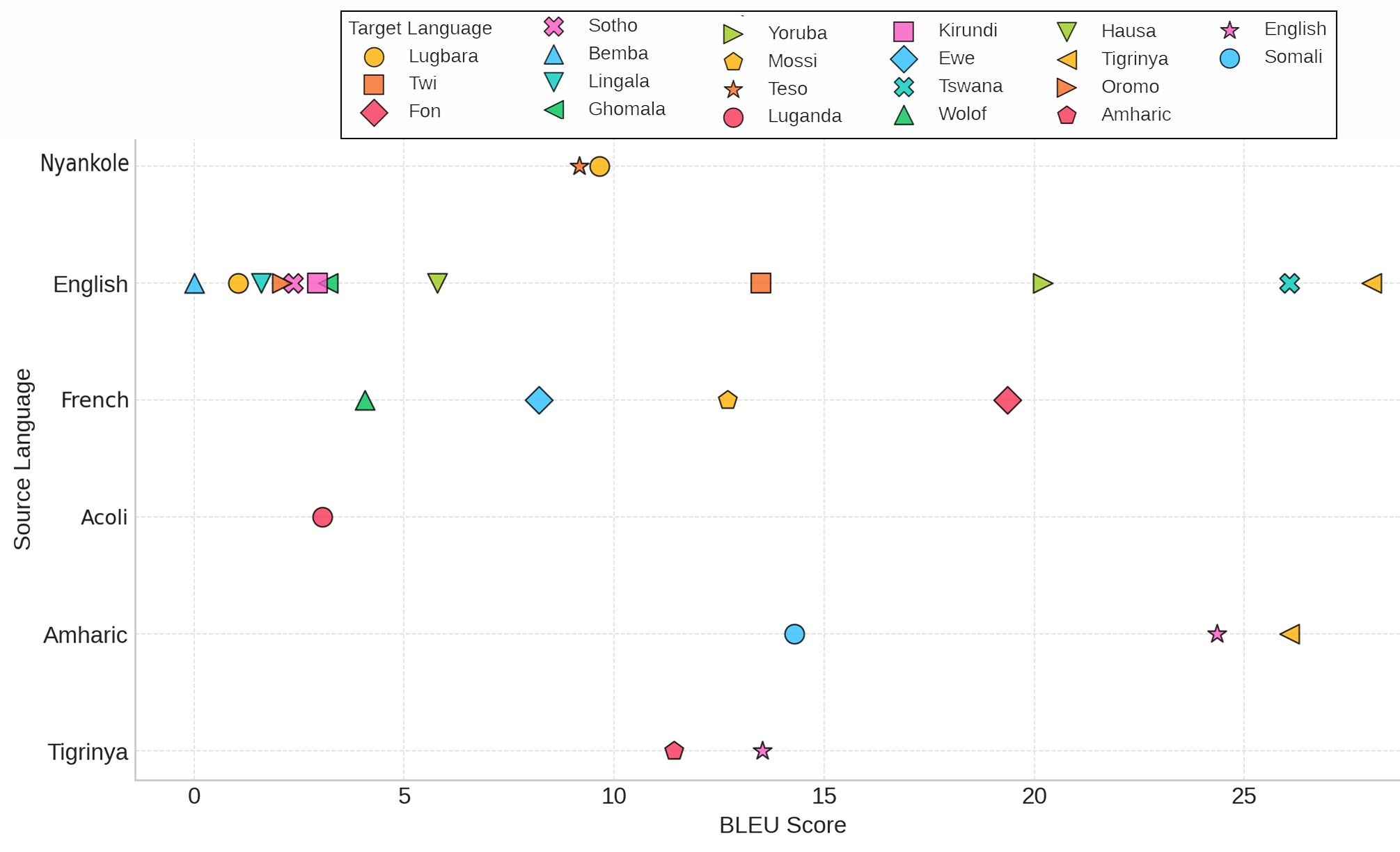
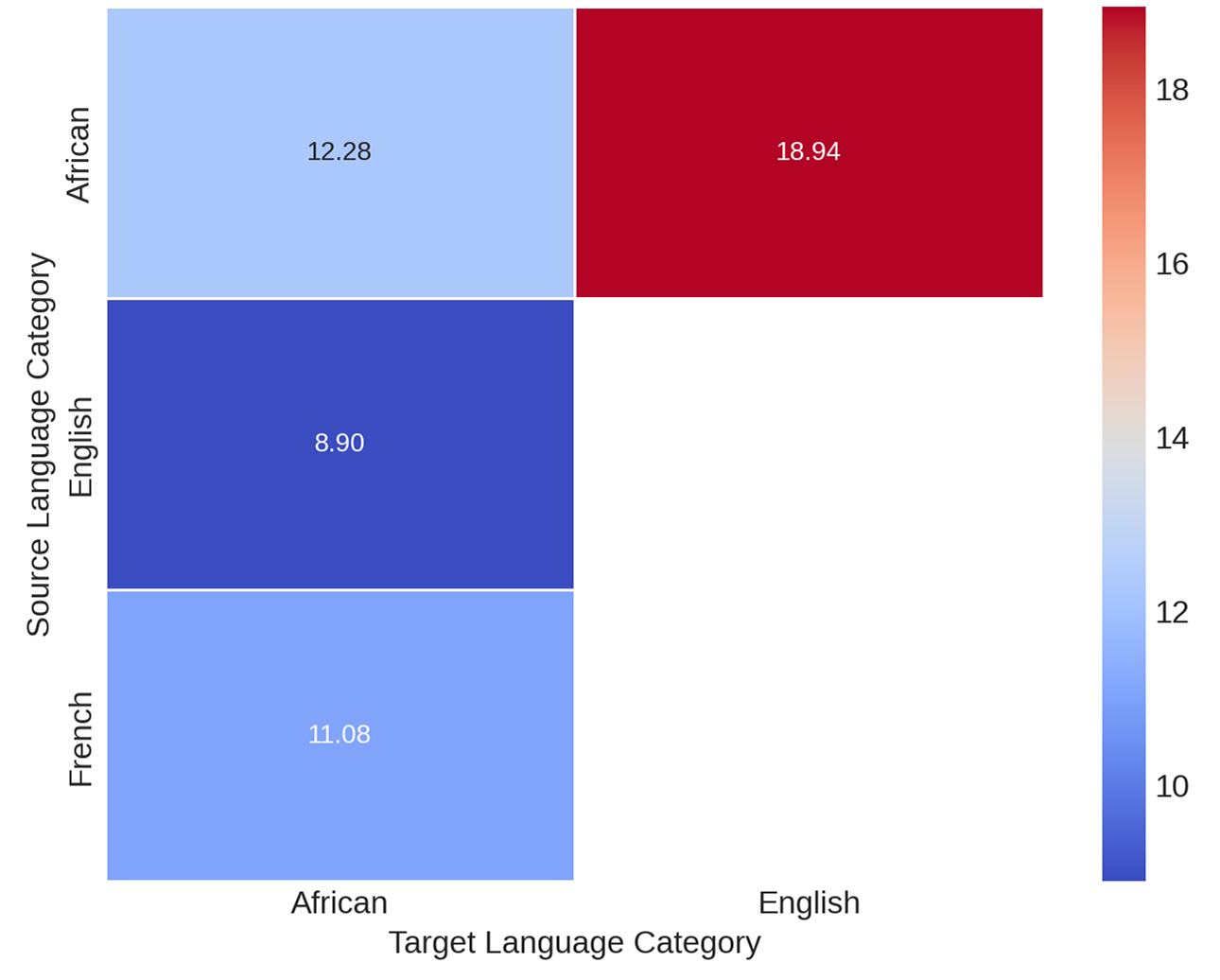
Figure 3: Distribution of best model performance (Claude 3.5-Sonnet) on different task clusters across African languages in downstream data.
The availability of datasets for African languages is uneven, with only a small subset possessing multiple resources. This is closely linked to language policy, with official languages generally enjoying better data support. Conversely, languages without official recognition remain under-resourced. The quality of existing datasets is often limited, with reliance on translated materials that may not reflect authentic language use. Addressing this requires policy shifts that prioritize multilingual data collection and integration of diverse languages into digital communication.
Recommendations
The paper advocates for policy reforms to bridge the language divide, emphasizing the need for inclusive data practices and increased funding for low-resource language research. It stresses the importance of community-driven data annotation efforts and the development of culturally relevant datasets to improve NLP outcomes for African languages.
Conclusion
This study highlights the need to integrate theoretical insights with empirical evaluations to foster linguistic diversity in AI development. By introducing the Sahara benchmark and evaluating LLMs on African languages, the paper underscores the importance of inclusive policies and data practices. These efforts aim to bridge the digital divide and promote equitable representation of African languages in NLP research.
