EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
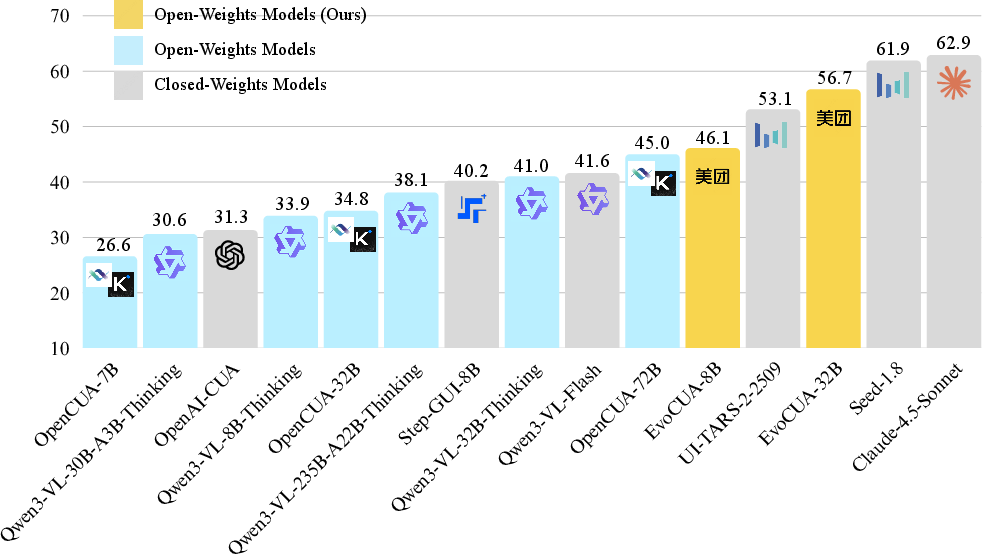
Abstract: The development of native computer-use agents (CUA) represents a significant leap in multimodal AI. However, their potential is currently bottlenecked by the constraints of static data scaling. Existing paradigms relying primarily on passive imitation of static datasets struggle to capture the intricate causal dynamics inherent in long-horizon computer tasks. In this work, we introduce EvoCUA, a native computer use agentic model. Unlike static imitation, EvoCUA integrates data generation and policy optimization into a self-sustaining evolutionary cycle. To mitigate data scarcity, we develop a verifiable synthesis engine that autonomously generates diverse tasks coupled with executable validators. To enable large-scale experience acquisition, we design a scalable infrastructure orchestrating tens of thousands of asynchronous sandbox rollouts. Building on these massive trajectories, we propose an iterative evolving learning strategy to efficiently internalize this experience. This mechanism dynamically regulates policy updates by identifying capability boundaries -- reinforcing successful routines while transforming failure trajectories into rich supervision through error analysis and self-correction. Empirical evaluations on the OSWorld benchmark demonstrate that EvoCUA achieves a success rate of 56.7%, establishing a new open-source state-of-the-art. Notably, EvoCUA significantly outperforms the previous best open-source model, OpenCUA-72B (45.0%), and surpasses leading closed-weights models such as UI-TARS-2 (53.1%). Crucially, our results underscore the generalizability of this approach: the evolving paradigm driven by learning from experience yields consistent performance gains across foundation models of varying scales, establishing a robust and scalable path for advancing native agent capabilities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper introduces EvoCUA, a new kind of AI “computer helper” that can look at a computer screen, read instructions, and control the mouse and keyboard to finish tasks—like a person would. Instead of just copying examples from a fixed dataset, EvoCUA learns by practicing a huge number of tasks in safe, simulated computers and improves by studying both its successes and its mistakes.
What questions the researchers wanted to answer
- How can we train a computer-using AI to handle long, multi-step tasks (like editing a document or analyzing a spreadsheet) more reliably than by just copying old examples?
- Can we automatically create lots of realistic, solvable practice tasks—and automatically check if the AI did them right?
- Is there a scalable way to let the AI practice on thousands of virtual computers at once?
- Can an AI learn better if it:
- keeps the good parts from successful attempts,
- and fixes specific mistakes found in failed attempts?
How EvoCUA works (with easy analogies)
Think of training this AI like training a sports team—by giving it good drills, lots of practice time, and coaching based on video review.
- It builds its own “practice drills” and “referees”
- Verifiable Synthesis Engine: The system automatically creates tasks (like “sort this spreadsheet” or “save a PDF with a new name”) and also creates a strict “autograder” for each task—a tiny program that checks if the task was done correctly.
- Why this matters: The AI doesn’t just get fuzzy feedback (“looks okay”); it gets clear pass/fail signals based on the actual computer state.
- It trains in a giant “computer gym”
- Scalable Interaction Infrastructure: The team built a huge training system that runs tens of thousands of virtual computers at the same time (using virtual machines inside containers).
- These virtual PCs are carefully tuned so the same clicks and keystrokes always produce the same results (fonts installed, keyboard mappings fixed, layouts stable).
- Why this matters: The AI can practice safely, quickly, and consistently—like scrimmaging on many fields at once.
- It learns like a good student: from wins and mistakes
- Cold start: First, the AI learns the basics—how to reason step by step and how to use mouse/keyboard actions correctly.
- Learn from wins (Rejection Sampling Fine-Tuning): The AI collects examples of successful attempts, cleans out unnecessary or messy steps, and studies those.
- Learn from mistakes (Reinforcement Learning with step-level feedback): When a task fails, the system finds the exact “fork in the road” where the AI went wrong. Then it teaches the AI what it should have done at that moment and how to pause, reflect, and recover next time.
- In short: Keep what works. Fix what fails. Repeat.
What they found and why it’s important
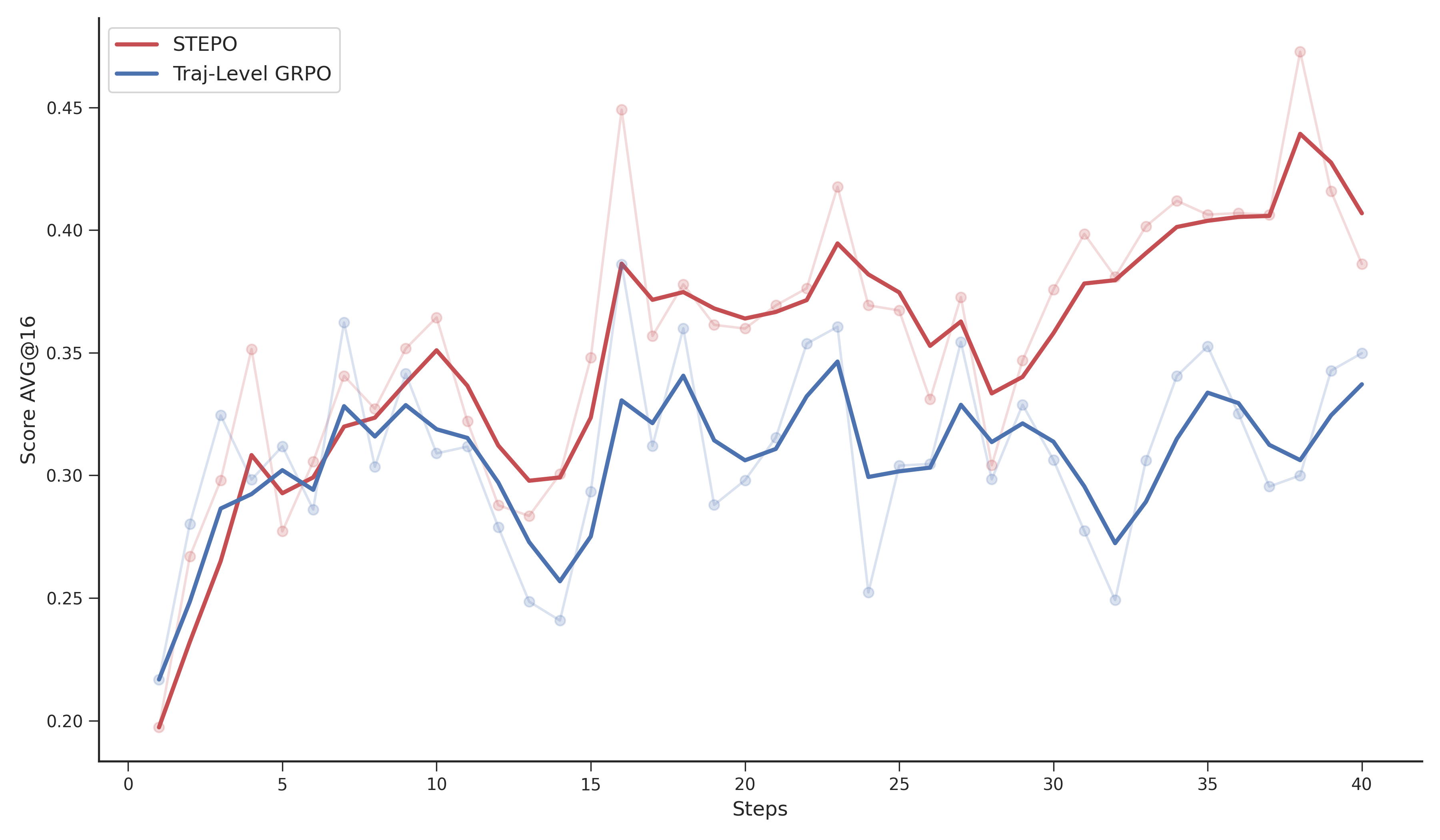
- On a tough benchmark called OSWorld (which tests real computer-using skills), EvoCUA achieved a 56.7% success rate with its 32B model, which is:
- better than the previous best open-source model (45.0%),
- and even better than some leading closed models (like 53.1%).
- Even the smaller 8B version scored 46.1%, beating some much larger models.
- It did this with fewer steps per task (50 steps), showing it’s more precise and efficient.
Why this matters:
- It shows that learning from lots of interactive experience—especially with automatic task creation and strict checking—can beat simply training on static, human-made examples.
- It works across different base models and sizes, which means it’s a flexible and scalable approach.
What this could mean for the future
- Smarter computer assistants: Systems that can reliably handle real tasks—editing files, analyzing data, filling forms, browsing, or organizing information—could become practical and trustworthy helpers.
- Cheaper, faster progress: Because the tasks and graders are generated automatically and checked in bulk, researchers don’t need to hand-label everything. That speeds up improvement.
- Safer training: Practicing inside thousands of isolated virtual computers reduces risk and makes results more consistent.
- A general recipe: The “learn from scalable experience” loop—create tasks + auto-check + practice at scale + learn from wins and mistakes—could help many other AI agents beyond computer use.
In short: EvoCUA shows that giving AI a realistic, massive, and well-checked way to practice—just like people—can lead to big, reliable gains in how well it uses computers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored, to guide future research.
- Real-world generalization beyond the calibrated Ubuntu 22.04 sandbox is untested: performance on Windows/macOS, different desktop environments, locale settings, and heterogeneous hardware/driver stacks remains unknown.
- Robustness to uncontrolled UI variability (unexpected pop-ups, OS updates, window occlusions, network delays, variable DPI/scaling, non-installed fonts) is not characterized; current font and HID patches may mask real-world instability.
- Coverage and realism of the synthetic task distribution are not quantified: how representative is the hierarchical taxonomy and hybrid resource injection of real enterprise workflows and long-tail tasks?
- Validator reliability is not measured: false-positive/false-negative rates of executable evaluators and the reward model, especially under edge cases and complex success criteria, are unknown.
- Scalability of “Generation-as-Validation” to domains where success is subjective or multi-faceted (e.g., design quality, readability, compliance) is unclear; how to define executable validators for such tasks?
- Dependence on foundation VLMs for dual-stream synthesis introduces bias and failure modes; a systematic audit of synthesis errors (e.g., GT mismatches, API misuse) and their impact on training is missing.
- Tri-fold decontamination efficacy is not validated quantitatively; residual benchmark leakage risk and its effect on reported gains are not assessed.
- Experience pool diversity and balance (by domain, app, complexity, language, and resource type) are not reported; risk of overfitting to overrepresented domains remains.
- No ablation isolating contributions of the three stages (cold start, RFT, RL) and their interactions; the marginal utility of each component, and whether some are redundant, is unknown.
- The RL formulation (step-level DPO) lacks comparison to alternative credit assignment methods (e.g., TD learning, actor-critic with learned intermediate rewards, Q-learning on structured actions); sample efficiency and stability trade-offs are unstudied.
- Critical Forking Point detection relies on availability of a successful reference or synthesis; coverage when references are unavailable or non-alignable is not evaluated.
- Reflection traces may add inference latency and token costs; their net effect on throughput, success rates, and hallucination reduction is not quantified.
- Dynamic compute budgeting hyperparameters (budget spectrum and thresholds) are not described or analyzed; sensitivity, stability, and fairness across tasks are unknown.
- Asynchronous rollout decoupling from policy updates can cause on-/off-policy drift; the extent of stale-policy interactions and their impact on learning is not measured.
- Step budget sensitivity is underexplored: success rates vs. max-step constraints (50 vs. 100+) and trade-offs with precision/efficiency are not systematically characterized.
- Failure taxonomy is missing: no detailed post-hoc analysis of error types (perception, grounding, keyboard/mouse state, planning, termination) and their prevalence across domains/apps.
- Safety and security considerations beyond VM isolation are not addressed: guardrails for destructive actions (e.g., deleting files, credential use), policy constraints, and safe deployment guidelines are absent.
- Privacy/legal risks from injecting public internet data (licensing, PII, sensitive content) and validator code execution are unexamined.
- Multilingual and non-English UI support is not evaluated; impact of locale, non-Latin scripts, RTL layouts, and language-specific hotkeys remains unknown.
- Accessibility and atypical input modalities (screen readers, high-contrast themes, assistive tech) are not considered; agent performance in accessible UI configurations is unexplored.
- General-capability retention issues are acknowledged (MMMU, ScreenSpot-Pro declines), but the cause (thinking vs. non-thinking data mismatch) is not resolved; methods for distribution-aligned mixing and avoiding catastrophic forgetting need study.
- Data scale and release details are incomplete: exact counts per domain, public release of synthesized tasks and validators, and reproducibility of the synthesis pipeline are unclear.
- Compute, cost, and energy footprint of tens of thousands of concurrent sandboxes are not reported; strategies for cost/energy-efficient scaling and environmental impact are missing.
- User-centric evaluation is absent: no human studies on usability, reliability under supervision, productivity gains, or trust/interpretability of reasoning traces.
- Transferability to other agentic settings (mobile apps, terminal/TUI, cloud SaaS, web-native GUIs) and cross-application workflows (multi-app, multi-session, long-term memory) is untested.
- Intermediate reward shaping and curriculum strategies are limited to terminal binary rewards; learning from dense signals (e.g., partial progress, UI element-level micro-goals) is not explored.
- Judge model identity, calibration, and error rates for step-level denoising are unspecified; its potential to introduce bias or discard useful steps is not assessed.
- Fairness of baseline comparisons is limited: heterogeneous step budgets and closed-weight differences confound attribution; standardized evaluation protocols are needed.
- Open-source availability of the high-throughput infrastructure (VM orchestration, scheduler, gateway) and its portability to public clouds is unclear; reproducibility outside the authors’ environment is uncertain.
- Long-horizon persistence (file state across sessions, robust checkpoints, recovery from crashes) and memory mechanisms are not studied; agent reliability over multi-session tasks remains unknown.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with the paper’s released models, verifiable synthesis engine, and sandbox infrastructure.
- Computer-use RPA with error recovery [Software, Finance, E-commerce, Operations] Tools/products/workflows: Replace brittle GUI scripts with an EvoCUA-based agent that executes long-horizon desktop workflows (e.g., Excel report generation, PDF processing, data consolidation across apps) and self-recovers via reflection and step-level correction. Integrate “pass@k” dynamic retries for boundary tasks. Assumptions/dependencies: Agents operate within hardened sandboxes; validators exist for critical tasks; human-in-the-loop for exceptions; Linux-first images or equivalent calibrated images for target OS/apps.
- Autonomous desktop QA/regression testing [Software/QA] Tools/products/workflows: Use the verifiable synthesis engine to auto-generate test tasks and executable validators for desktop apps; run at scale in the QEMU-KVM sandbox via CI pipelines to detect regressions (layout/rendering/keyboard mapping). Add step-level denoising to reduce flakiness. Assumptions/dependencies: Access to app images, fonts, and deterministic rendering; validator authoring for product-specific success criteria; compute for thousands of parallel runs.
- Back-office operations automation (reports, reconciliations, bulk edits) [Finance, E-commerce, Logistics] Tools/products/workflows: Configure role/capability/resource templates (e.g., monthly P&L, price updates, order reconciliation). Validate outcomes with domain-specific evaluator libraries (e.g., numbers match, files generated). Assumptions/dependencies: Clear ground-truth definitions; safe credentials handling; scoped privileges; change management to handle UI updates.
- IT service desk and configuration tasks [IT/Ops] Tools/products/workflows: Automate GUI-based provisioning (install apps, set proxies, configure fonts, apply patches), using control primitives (wait/terminate) to handle asynchronous UI and validators to confirm successful configuration. Assumptions/dependencies: Sandbox images mirror production; validator checks for system state; guardrails for privileged operations.
- Secure agent testing and red-teaming at scale [Security, Platform Engineering] Tools/products/workflows: Use the hybrid virtualization (QEMU-in-Docker) to safely execute untrusted agent behavior, collect failure trajectories, and apply step-level DPO to harden policies against prompt-injection and UI traps. Assumptions/dependencies: Strict kernel-level isolation; audit logging; curated adversarial tasks with executable checks.
- Internal benchmarking and skills tracking for GUI agents [Software, MLOps] Tools/products/workflows: Adopt “generation-as-validation” to build an internal, evolving benchmark tied to app versions and business workflows; monitor agent success rates and compute-adjust budgets to focus on weak skills. Assumptions/dependencies: Taxonomy of atomic capabilities; evaluator decontamination; continuous synthesis to avoid benchmark overfitting.
- AgentOps for reliability engineering [Software/MLOps] Tools/products/workflows: Deploy a monitoring layer that identifies Critical Forking Points, surfaces reflection events, and auto-generates preference pairs for DPO-based hotfixes; continuously update a rolling “experience pool.” Assumptions/dependencies: Storage and governance for trajectory logs; reference selection or synthesis for chosen/rejected pairs.
- Accessibility co-pilot for repetitive GUI tasks [Healthcare, Public Sector, Consumer] Tools/products/workflows: Natural-language-triggered sequences that automate multi-step GUI actions (form filling, file management, batch renaming) with visual self-check before termination. Assumptions/dependencies: Reliability threshold acceptable to users (human confirmation for high-stakes actions); privacy constraints for on-device data.
- Education and training labs for HCI/RL/ML systems [Academia, EdTech] Tools/products/workflows: Course labs that synthesize tasks plus validators; students compare imitation vs. experience learning; scale asynchronous sandboxes for class cohorts. Assumptions/dependencies: Institutional compute; curated task suites; safe environment images.
- Synthetic data generation pipeline for GUI agent training [Software, Research] Tools/products/workflows: Use dual-stream synthesis to produce large, grounded datasets with executable validators; tri-fold decontamination to prevent leakage; publish as internal corpora for model post-training. Assumptions/dependencies: VLM-based task architect; evaluator tool libraries; QA protocol (consistency checks, manual spot audits).
- UI compatibility and rendering calibration in CI [Software/QA] Tools/products/workflows: Apply font injection and HID mapping calibration to ensure cross-environment consistency; gate releases on validator-verified UI fidelity (e.g., office doc rendering). Assumptions/dependencies: Access to proprietary fonts; deterministic OS builds; baseline screenshots/validators.
- Vendor-agnostic “GUI Gym” as a managed service [Cloud, Platform] Tools/products/workflows: Offer a sandbox farm that boots tens of thousands of sessions/min; expose APIs for rollouts, validators, pass@k orchestration, and logs; support customers’ internal agent training/evaluation. Assumptions/dependencies: Multi-tenant isolation; quota controls; cost monitoring; SLAs.
Long-Term Applications
The following opportunities require further research, scaling, safety work, or ecosystem development before broad deployment.
- Enterprise-grade generalist desktop co-pilots with high reliability [Software, Cross-industry] Tools/products/workflows: Organization-wide assistants that handle complex, cross-application workflows with audit trails, deterministic validators, and automated failure-to-feedback loops. Assumptions/dependencies: Consistent >90% success rates in-the-wild; standards for validator quality and coverage; robust governance and rollback.
- Regulated workflow automation (EHRs, trading terminals, public admin) [Healthcare, Finance, Government] Tools/products/workflows: Agents operating legacy GUIs under strict compliance, with verifiable evaluators defining admissible outcomes; continuous preference optimization from audited failures. Assumptions/dependencies: Privacy-preserving sandboxes; domain-certified validators; human oversight; detailed auditability and access control.
- On-device, privacy-preserving experience learning [Consumer, Enterprise IT] Tools/products/workflows: Local agents that learn from personal GUI history; validators run locally; federated aggregation of preference signals without raw data sharing. Assumptions/dependencies: Efficient on-device models; secure enclave for logs; federated optimization and drift detection.
- Cross-OS, cross-application generalization at scale [Software, Platform] Tools/products/workflows: Reliable operation across Windows/macOS/Linux with app-specific quirks (fonts, HID, rendering); universal action schemas and adaptive reasoning. Assumptions/dependencies: OS-specific calibration (HID, rendering); large-scale synthesis per OS/app; continuous adaptation to UI changes.
- Standardization of verifiable evaluators and safety audits [Policy, Standards] Tools/products/workflows: Industry standards for “executable validators,” dataset decontamination, and safety test suites; certification programs for GUI agents. Assumptions/dependencies: Multi-stakeholder consensus; regulator involvement; open reference implementations and audit tooling.
- Multi-agent orchestration for end-to-end business processes [Operations, ERP/CRM] Tools/products/workflows: Teams of specialized GUI agents with shared experience pools, role-based validators, and coordination protocols for SLAs and handoffs. Assumptions/dependencies: Inter-agent communication standards; conflict resolution; process-level validators and KPIs.
- Digital twins of enterprise desktops for change management [IT/Ops, DevOps] Tools/products/workflows: Simulate large-scale rollouts (patches, UI updates, policy changes) in a GUI twin with executable acceptance tests before production deployment. Assumptions/dependencies: Accurate cloning of environments; cost-efficient large-scale simulation; integration with ITSM/CMDB.
- Safety-critical HMI operation (industrial, energy) [Energy, Manufacturing] Tools/products/workflows: Agents assist with SCADA/HMI under strict guardrails, running only in shadow mode with validators mirroring safe states and interlocks. Assumptions/dependencies: Extremely robust verification; formal methods-backed validators; human-in-the-loop; regulatory approval.
- End-to-end web task automation resilient to site drift [E-commerce, Media, Travel] Tools/products/workflows: Agents that handle heterogeneous websites, robustly recover from DOM/layout changes via visual grounding and reflection, and validate outcomes (e.g., booking confirmation). Assumptions/dependencies: Domain-specific validators; content policy compliance; continuous adaptation to site changes.
- Cross-domain reward/validator libraries (beyond GUIs) [Robotics, IoT, XR] Tools/products/workflows: Port the “generation-as-validation” paradigm to robotics/IoT/XR, building executable evaluators for physical or simulated tasks to enable scalable RL. Assumptions/dependencies: High-fidelity simulators; sensor-grounded validators; sim2real transfer methods.
- Human-in-the-loop governance with learning-from-feedback markets [Policy, Platforms] Tools/products/workflows: Frameworks where user approvals/denials become structured preference signals; marketplaces for validator modules and correction datasets. Assumptions/dependencies: Incentive design; privacy and consent; provenance tracking and quality scoring.
- Energy- and cost-aware large-scale agent training [Cloud, Sustainability] Tools/products/workflows: Optimizers that schedule pass@k budgets, sandbox lifecycles, and preference updates for minimal energy/cost per capability gain. Assumptions/dependencies: Telemetry standards; carbon-aware schedulers; pricing models tied to reliability metrics.
- Personal “full PC autopilot” assistants for daily life [Consumer] Tools/products/workflows: Household-grade agents that handle admin tasks (form filling, bookings, file organization, app setup), with just-in-time confirmations and visual self-checks. Assumptions/dependencies: High reliability in diverse consumer environments; safe credential handling; accessible UX for oversight and corrections.
In all cases, feasibility depends on several common factors highlighted by the paper’s approach: availability of high-quality, executable validators; robust sandboxing and calibrated environments; sufficient compute for large-scale asynchronous rollouts; continuous error analysis (critical forking points) and preference-based correction; and governance for safety, privacy, and auditability.
Glossary
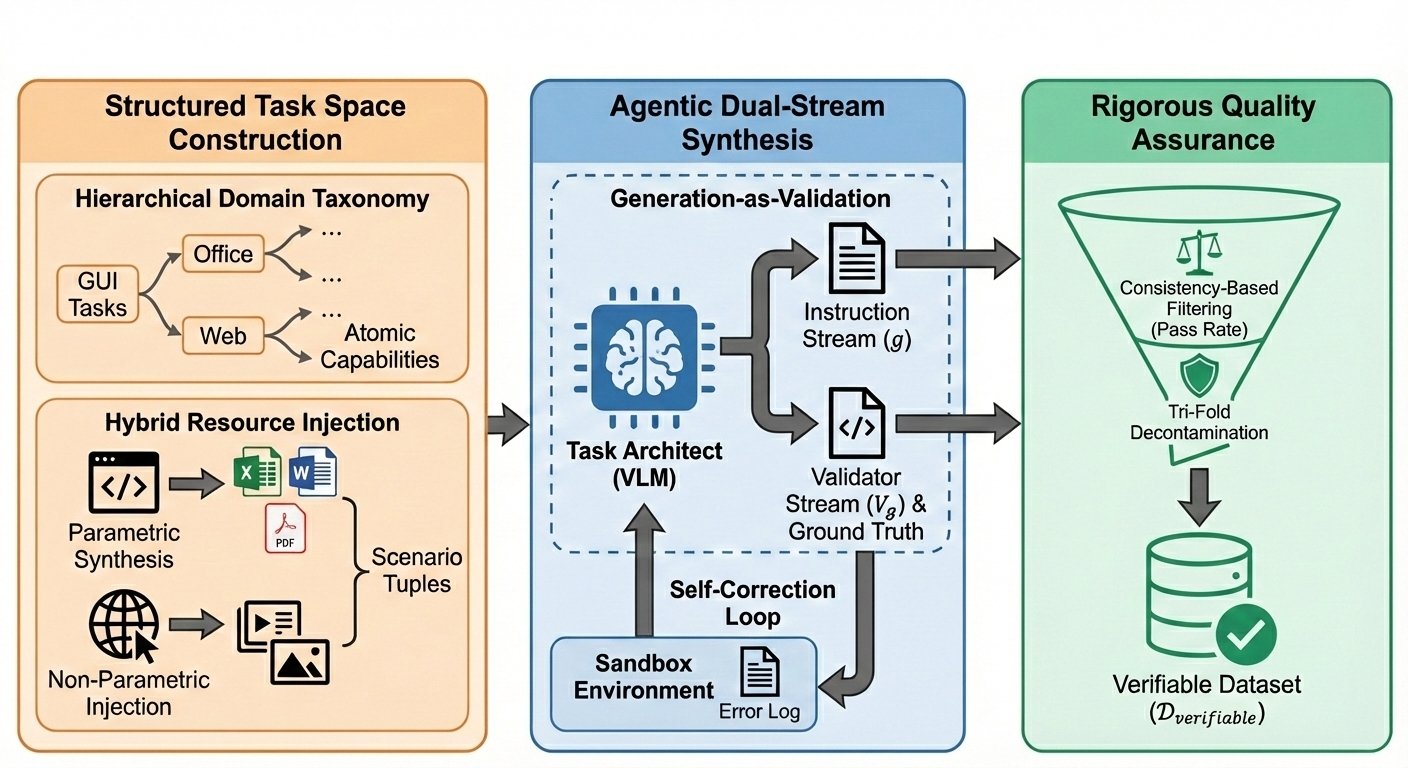
- Agentic Dual-Stream Synthesis: A dual-stream generation process where a task architect produces both instructions and executable validators within one agentic workflow. "Agentic Dual-Stream Synthesis, where a Task Architect (VLM) co-generates instructions () and executable validators () via a closed-loop feedback mechanism;"
- Asynchronous gateway service: A non-blocking I/O routing layer that decouples control from environment interaction to handle massive request throughput. "The infrastructure relies on an asynchronous gateway service based on the reactor pattern for non-blocking I/O."
- Asynchronous sandbox rollouts: Concurrent environment interactions executed without synchronization to scale experience collection. "we design a scalable infrastructure orchestrating tens of thousands of asynchronous sandbox rollouts."
- Atomic capabilities: Minimal, transferable skills that can be composed into complex tasks. "Moving beyond text-only generation, we analyze atomic capabilities to synthesize self-contained task definitions."
- Burst scaling capabilities: The ability to rapidly instantiate large numbers of environments in response to demand spikes. "More critically, it supports burst scaling capabilities, bootstrapping tens of thousands of sandbox instances within one minute."
- Closed-loop feedback mechanism: An iterative executability check that runs generated code and feeds the outcome back to improve validators. "To guarantee executability, we enforce a closed-loop feedback mechanism."
- Critical Deviation Step: The earliest step where an action diverges from a successful reference while states remain equivalent. "We identify the Critical Deviation Step as the first timestamp where the agent's action diverges from the reference, despite the environmental states remaining functionally equivalent."
- Critical Forking Points: Decision points in long-horizon tasks where small action differences lead to success or failure. "We instead propose a Step-Level Direct Preference Optimization strategy~\citep{lai2024step} that targets Critical Forking Points illustrated in Figure \ref{fig:evocua_dpo}."
- Deterministic environment calibration: System-level adjustments ensuring consistent inputs and rendering across runs. "Deterministic environment calibration."
- Direct Preference Optimization (DPO): A training objective that increases preference margins between chosen and rejected samples. "We optimize the policy using Direct Preference Optimization (DPO)."
- Distributed sharding: Partitioning scheduling and resources across shards to enable high-efficiency scaling. "Leveraging distributed sharding and resource pooling, the scheduler achieves high-efficiency node scheduling."
- Dynamic compute budgeting: Adaptive allocation of rollout budget based on observed task success rates. "To optimize the generation of high-quality experience under computational constraints, we propose dynamic compute budgeting."
- Experience Pool: A transient buffer aggregating freshly collected trajectories for on-policy updates. "The scalable interaction infrastructure maintains a transient Experience Pool that aggregates a high-throughput stream of fresh interaction trajectories:"
- fc-cache: The Linux font cache utility used to register fonts and stabilize rendering. "we injected a comprehensive suite of proprietary fonts directly into the system font cache (fc-cache)."
- Generation-as-Validation: A synthesis approach where generating tasks inherently includes generating their executable validators. "This \"Generation-as-Validation\" approach eliminates the ambiguity of natural language rewards, providing the agent with precise, deterministic supervision signals."
- HID patching: Modifying Human Interface Device mappings to guarantee input determinism. "Input determinism (HID patching): Standard virtualization often suffers from key mapping collisions."
- Hierarchical Domain Taxonomy: A structured decomposition of applications and behaviors into domains and atomic skills. "Leveraging a hierarchical domain taxonomy, we synthesized a wide range of task scenarios featuring diverse user personas~\citep{ge2024scaling} to ensure data diversity."
- Hindsight Reasoning Generation: Retrospective generation of reasoning traces that explain known action sequences. "Crucially, to ensure alignment between reasoning and action, we employ a Hindsight Reasoning Generation strategy."
- Hybrid virtualization: Encapsulating hardware-accelerated VMs within containers to balance isolation and performance. "To support the rigorous requirements of computer use tasks, we implement a hybrid virtualization architecture that encapsulates QEMU-KVM virtual machines within Docker containers."
- Monte Carlo estimation: Sampling-based approximation used to estimate expectations over task distributions. "we resort to an empirical approximation via massive-scale Monte Carlo estimation."
- Non-parametric injection: Incorporating real internet data to increase realism and visual noise in synthesized tasks. "Non-parametric injection: To mitigate the sterility of synthetic templates, we inject public internet data (e.g., images, audio, complex slides)."
- On-policy reinforcement learning: Learning from trajectories generated by the current policy to maintain alignment between data and parameters. "ensures that the environment scaling strictly matches the training demand of on-policy reinforcement learning, minimizing the latency between policy updates and experience collection."
- OSWorld benchmark: A benchmark suite for evaluating open-ended computer-use agents in realistic environments. "Empirical evaluations demonstrate that EvoCUA achieves a state-of-the-art success rate of 56.7\% on the OSWorld benchmark~\citep{xie2024osworld}"
- Parametric synthesis: Code-based generation of structured documents by parameterizing variables. "Parametric synthesis: For structured data (e.g., production sales data), we utilize code-based generators to batch-produce documents (Word, Excel, PDF) by parameterizing variables such as names, prices and dates."
- Partially Observable Markov Decision Process (POMDP): A formal model of decision-making under partial observability used to frame the agent’s interaction. "Formally, CUA can be viewed as a Partially Observable Markov Decision Process (POMDP)~\citep{kaelbling1998planning}"
- pass@k: A success metric and compute allocation guide based on the number of attempts. "This entire process is driven by a pass@k-guided dynamic compute strategy"
- QEMU-KVM virtualization: Hardware-accelerated virtualization via QEMU with KVM used for high-fidelity GUI environments. "Computer Use Sandbox, which utilizes QEMU-KVM virtualization and a calibrated OS to ensure input determinism, rendering consistency, and runtime stability for high-fidelity environments."
- ReAct-based agentic workflow: A reasoning-acting loop that structures dual-stream task and validator generation. "The core synthesis process is modeled as a ReAct-based agentic workflow~\citep{yao2022react}."
- Reactor pattern: An event-driven I/O design enabling non-blocking request handling at scale. "based on the reactor pattern for non-blocking I/O."
- Reference-Guided Diagnosis: A method for locating causal errors by comparing failed and successful trajectories. "Given a failed rollout and a successful reference (retrieved from the same or a semantically equivalent task), we employ a Reference-Guided Diagnosis mechanism."
- Rejection Sampling Fine-Tuning (RFT): A fine-tuning method that trains only on high-quality successful executions. "The objective of Rejection Sampling Fine-Tuning (RFT)~\citep{ahn2024large} is to consolidate the agent's ability to solve tasks by learning exclusively from high-quality, successful executions."
- Rendering consistency: Ensuring identical document layouts via font calibration to avoid confusing visual agents. "Rendering consistency: To prevent layout shifts in office software that confuse visual agents, we injected a comprehensive suite of proprietary fonts directly into the system font cache (fc-cache)."
- Reasoning Schema: A structured format that aligns the agent’s explicit reasoning with its execution logic. "To enable interpretable and robust decision-making, we define a Reasoning Schema for the latent thought space ."
- Reward model: A learned model used to estimate or validate task success, complementing executable evaluators. "we calculate pass rates using both a reward model and an evaluator."
- State transition kernel: The function that defines how environment states evolve given actions. "The environment state evolves according to a state transition kernel "
- Stateful Interaction mechanism: A representation that preserves key-down/up states to enable complex multi-step inputs. "Crucially, to support complex, multi-step operations, we implement a Stateful Interaction mechanism."
- Step-Level denoising: Filtering trajectories to remove redundant or misleading steps before training. "Step-Level Denoising."
- Step-Level Direct Preference Optimization: Applying DPO at the step level to correct actions and induce reflection. "We instead propose a Step-Level Direct Preference Optimization strategy~\citep{lai2024step}"
- Tri-fold decontamination: A three-pronged strategy (semantic, configuration, evaluator) to prevent data leakage. "Tri-fold decontamination."
- Verifiable reward: A binary, instruction-conditioned reward derived from executable validators on terminal states. "Supervision is grounded in execution correctness via a verifiable synthesis mechanism."
- Verifiable Synthesis Engine: A system that co-generates tasks and executable validators to provide deterministic supervision. "Verifiable Synthesis Engine."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs for perception and task planning. "a foundation VLM functions as a task architect to execute a dual-stream generation:"
- xkb: The X Keyboard Extension configuration used to calibrate key mappings inside the VM. "We calibrated the human interface device mapping at the xkb kernel level."
Collections
Sign up for free to add this paper to one or more collections.

