ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Abstract: The evolution of LLMs into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development”
Overview
This paper introduces ABC-Bench, a big test (benchmark) designed to see how well modern AI systems—especially those that act like developers—can build and fix the “backend” of real software. The backend is the behind-the-scenes part of apps and websites that handles data, runs logic, and responds to requests. Unlike simple coding tests, ABC-Bench checks whether an AI can do the whole job: understand a project, change the code, set up the right environment, deploy the service, and prove that it works by passing real web tests.
Key Objectives
The paper focuses on three main questions, explained simply:
- Can AI agents handle the full process of backend development, not just writing code?
- Where do these AIs struggle the most—coding, setting up the environment, deploying, or passing end-to-end tests?
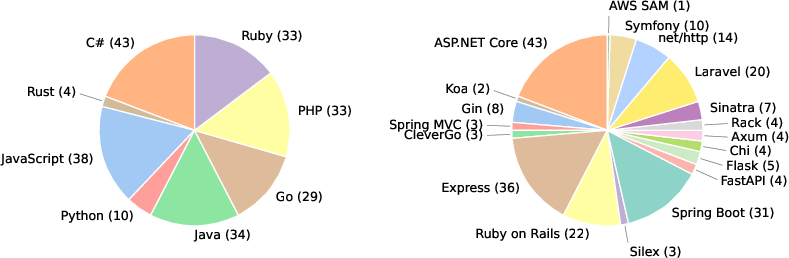
- How can we build a realistic, large-scale test set to measure these skills across many programming languages and frameworks?
Methods and Approach
Think of building a backend like opening a food truck: you don’t just need a recipe (code), you also need a kitchen setup (environment), a working truck (deployment), and real customers to serve (API tests).
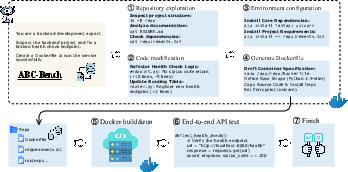
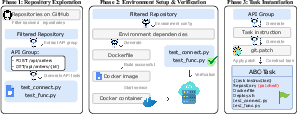
To create ABC-Bench, the authors built an automated system called ABC-Pipeline that turns real open-source projects into test tasks. Here’s how it works:
- Picking projects: The system scans 2,000 open-source backend repositories and chooses good ones.
- Creating tests: Instead of relying on old or missing tests, the system writes its own checks that send real web requests (like HTTP requests) to endpoints (the API paths). This proves whether the service actually behaves correctly.
- Building “containers”: The AI must write Docker configurations—a container is like a sealed lunchbox that carries everything the app needs to run, so it runs the same way everywhere.
- Making the challenge: The system creates tasks by “masking” (hiding) parts of the correct code and asking the AI to fix or re-implement them. For harder tasks, it removes environment files too, so the AI must set up the whole runtime by itself.
- Double-checking solvability: The team first ensures the original project passes the tests when unmasked, then ensures the tests fail when masked. That way, the tasks are fair and meaningful.
In the actual evaluation, the AI runs inside one container (its workspace), writes and edits code, sets up dependencies, and prepares Docker files. Then, the benchmark builds and launches the backend service in a separate container and tests it with real API calls. The AI succeeds only if the service starts and passes the external tests.
Main Findings and Why They Matter
To keep this clear, here are the core findings:
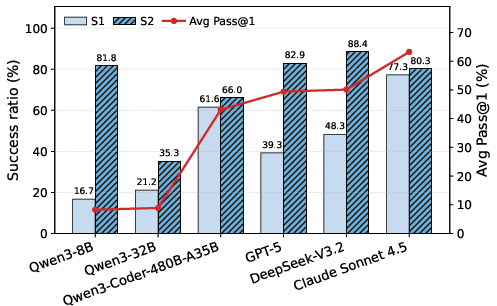
- Many top AIs still struggle with full-stack backend work: Even the best model tested reached about 63% success on the first try (pass@1) across 224 tasks. Most others performed lower, and small models often did very poorly.
- Environment setup is the biggest bottleneck: Some models could write correct feature code, but failed to set up the environment (dependencies, configurations, ports) or deploy the service. In other words, they “knew the recipe” but couldn’t “set up the kitchen.”
- Language and framework differences matter: Models did better on common stacks (like Python, Go, JavaScript) and often failed on Rust tasks. This shows uneven skills across programming ecosystems.
- Longer, thoughtful interactions help: Models that took more steps—reading logs, retrying, debugging—did better. Backend work usually needs many small fixes, not just one shot.
- The agent framework and training influence results: The way the AI interacts (its “agent framework”) changes performance a lot. Also, models trained on agent-style data (step-by-step developer workflows) improved strongly.
These findings matter because real backend work is messy and integrated. It’s not enough to write a function; you need to make sure the whole service runs correctly, end to end.
Implications and Impact
ABC-Bench highlights a gap between what today’s AI models can do and what real backend engineering demands. It shows researchers and engineers where to focus next:
- Teach AIs better environment and deployment skills (not just pure coding).
- Improve agent frameworks so AIs can plan, debug, and persist through long tasks.
- Build models with stronger multilingual and multi-framework support.
- Use realistic, end-to-end tests (like ABC-Bench) to measure true readiness for production work.
The authors are releasing the code and dataset openly, so the community can use it to build smarter, more reliable AI developer agents that can ship working backend services—not just write snippets.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and questions the paper leaves open, intended to guide future research.
- Real-world backend complexity beyond single-service containers is not evaluated: no multi-service orchestration (e.g., docker-compose, Kubernetes), message queues, caches, background jobs, persistent storage, or data migrations, which are common in production systems.
- Security, compliance, and deployment hygiene are out of scope: the benchmark does not assess secret management, dependency pinning/supply-chain risks, least-privilege containerization, or vulnerability scanning as part of agent outputs.
- Non-functional requirements are unmeasured: no metrics for latency, throughput, availability, resource usage, cold-start times, image size, or cost, limiting insight into production-readiness of generated solutions.
- Test coverage and quality are uncertain because tests are LLM-generated: the paper lacks systematic measures of test completeness, mutation testing, negative/edge-case coverage, flakiness rates, or human validation of test suites.
- Masking-based task instantiation may not reflect real-world bug-fixing/feature workflows: tasks simulate “missing logic,” but exclude realistic issues like version conflicts, performance regressions, security flaws, flaky tests, partial implementations, and refactoring constraints.
- External dependency determinism is not addressed: it is unclear whether network access is allowed, whether third-party APIs are stubbed, and whether dependencies are pinned to ensure reproducibility across time and environments.
- Resource and budget constraints are unspecified: the paper does not report CPU/RAM/disk/network limits, timeouts, build caching, or interaction budget choices per model, making it hard to interpret and replicate performance.
- Dataset representativeness is under-characterized: selection criteria from 2,000 repos to 224 tasks are described qualitatively; quantitative breakdown of acceptance/rejection reasons and potential biases by ecosystem, project size, repo maturity, and issue types is missing.
- Language/framework balance and difficulty calibration need clarification: strong performance variance (e.g., Rust near 0%) is reported, but the number and nature of tasks per language/framework (complexity, dependency graph depth, runtime specifics) are not analyzed to distinguish model weakness from dataset skew.
- Agent framework effects are only partially explored: results depend strongly on the framework; systematic ablations on tool availability, planning strategies, memory/retrieval, error-handling loops, and hyperparameters are missing.
- Causality of “interaction depth correlates with success” remains unclear: the paper reports correlation but does not test causation (e.g., controlled turn limits, enforced planning phases, or intervention experiments).
- Generality of agentic SFT effects is limited: SFT is assessed only on Qwen models with one dataset; broader evaluation across model families, datasets, and training regimens (e.g., RLHF, DPO, trajectory quality filters) is needed, including contamination checks against ABC-Bench.
- Evaluation metrics are narrow: pass@1 across three runs is the sole primary metric; pass@k, time-to-solve, number of edits/commands, cost (tokens/tools), reproducibility across seeds/runs, and failure recovery (robustness) are not reported.
- Human baseline and expert ablations are absent: there is no measurement of skilled developer performance under identical constraints, nor controlled studies on what tools or documentation access humans need versus agents.
- Task domains omit key backend scenarios: authentication/authorization with complex policies, multi-tenant isolation, streaming/real-time systems, event-driven architectures, IoT backends, and legacy monoliths are not covered.
- Operating system and platform diversity are limited: the benchmark appears Linux/container-centric; Windows/macOS differences, GPU/accelerator constraints, ARM architectures, and platform-specific tooling are not explored.
- CI/CD and DevOps integration are not assessed: agents are not evaluated on producing build pipelines, test jobs, release artifacts, rollbacks, or observability hooks (logs/metrics/traces).
- Data and state lifecycle are simplified: the benchmark does not test schema/version migrations, data seeding, backup/restore, or consistency handling under concurrent workloads.
- Documentation and specification handling are under-examined: tasks use LLM-authored instructions rather than real issue threads/specs; analysis of agent comprehension across README/docs, API contracts, and change requests is limited.
- Failure taxonomy lacks actionable linkage to interventions: while error categories are reported, the paper does not tie each class to concrete remediation strategies, benchmark variants, or tooling that would reduce those errors.
- Fairness across models is potentially confounded by tool integration: proprietary models may have differing default tool-use behaviors or context limits; standardized tool APIs, identical limits, and controlled retrieval configurations are not fully documented.
- Determinism and reproducibility of builds/tests are not audited: seed control, randomized test behaviors, network nondeterminism, and dependency resolution variability are not measured or mitigated.
- Cloud-native deployment is untested: agents are not asked to deploy to managed services (serverless, managed DBs, cloud networking, IAM), limiting external validity for production teams.
- Release artifacts lack completeness details: it is unclear whether the benchmark includes ground-truth patches, environment manifests, and reproducible build recipes for each task, and whether these are versioned to prevent silent drift.
- Benchmark scalability and maintenance plan are unspecified: with heavy LLM reliance in task construction, the paper does not report pipeline error rates, ongoing curation processes, or strategies to add/retire tasks as ecosystems evolve.
- Data contamination safeguards are not described: given public datasets and widely used training corpora, no methodology is presented to assess whether models have seen ABC-Bench tasks or their source repos during training.
Practical Applications
Immediate Applications
The following list outlines practical uses that can be deployed today using the paper’s benchmark, pipeline, and findings.
- Industry: Vendor benchmarking and procurement for AI coding agents
- Use ABC-Bench pass@1 and environment build/functional success metrics (S1/S2) to compare LLMs and agent frameworks on backend stacks relevant to your org.
- Sectors: software, cloud, finance, healthcare, e-commerce.
- Tools/products/workflows: “AgentOps scorecard” dashboards; RFP evaluation packs; language-stack readiness reports.
- Assumptions/dependencies: Your stack overlaps with the 8 languages/19 frameworks; Dockerized test environments; consistent sandboxing and metric definitions.
- Industry: CI/CD “agent risk gate” with production-like end-to-end tests
- Integrate ABC-style external API tests and inner/outer container isolation as pre-merge gates for agent-generated patches.
- Sectors: platform engineering, DevOps, SRE.
- Tools/workflows: CI plugin that spins inner containers, runs HTTP API tests, blocks deploy on failure.
- Assumptions/dependencies: Reliable container orchestration, test coverage quality, network isolation.
- Industry: Agent framework A/B testing and tuning
- Empirically select frameworks (e.g., OpenHands vs. mini-SWE-agent) and interaction strategies to maximize end-to-end success.
- Sectors: software tooling, internal developer platforms.
- Tools/workflows: Framework toggles, turn-depth budgeting, tool-use audit trails.
- Assumptions/dependencies: Instrumentation for turns/errors; reproducible agent trajectories.
- Academia: Reproducible backend-agent benchmark and curriculum
- Use ABC-Bench tasks to teach full-lifecycle backend development, containerization, and deployment validation.
- Sectors: education.
- Tools/workflows: “ABC-Lab kits” for courses; graded assignments using API tests; student sandbox containers.
- Assumptions/dependencies: Student access to Docker; lab compute; task selection by language.
- Academia/Industry: Agentic supervised fine-tuning (SFT) on trajectories
- Fine-tune base models on high-quality agent trajectories to improve end-to-end backend capabilities.
- Sectors: ML engineering, model training.
- Tools/workflows: SFT pipelines; trajectory collection; evaluation loops on ABC-Bench.
- Assumptions/dependencies: Access to trajectory datasets; training compute; licensing compliance.
- Industry: Multilingual capability audits and migration planning
- Use per-language breakdowns to identify gaps (e.g., Rust bottlenecks) and prioritize stack focus or training.
- Sectors: CTO/architecture, QA.
- Tools/workflows: Language heatmaps; remediation plans; stack-specific agent strategies.
- Assumptions/dependencies: Adequate task coverage for each language; cross-stack comparability.
- Industry/Academia: Error taxonomy–driven QA checklists
- Convert failure modes (path missing, dependency missing, logic errors) into pre-flight checklists and automated linters for agent outputs.
- Sectors: software quality, DevSecOps.
- Tools/workflows: “EnvConfig checklist,” dependency auditors; patch logic validators.
- Assumptions/dependencies: Mapping of error categories to automated checks; policy adoption by teams.
- OSS maintainers: Task generation for reproducible issue triage
- Use the ABC-Pipeline to mask functionality and auto-generate API tests to turn issues into solvable benchmark tasks for contributors.
- Sectors: open source ecosystems.
- Tools/workflows: “Issue-to-Task generator;” contributor onboarding packs.
- Assumptions/dependencies: Repository licensing; maintainers’ willingness to curate; pipeline reliability.
- HR/Training: Backend skills and agent-assisted hiring assessments
- Evaluate candidates and internal upskilling using ABC tasks that require code, environment configuration, and deployable services.
- Sectors: tech hiring, L&D.
- Tools/workflows: Practical exams with containerized evaluation; agent-in-the-loop pair programming drills.
- Assumptions/dependencies: Fair test administration; standardized scoring; sandbox resources.
- Security/Platform: Safe agent execution patterns via container isolation
- Adopt the paper’s outer-agent/inner-service isolation model to limit blast radius of tool use and deployment attempts.
- Sectors: security engineering, platform security.
- Tools/workflows: Network policies; ephemeral sandboxes; artifact quarantines.
- Assumptions/dependencies: Strong isolation, observability, role-based access.
- Daily life (developers): Practice and portfolio building with production-like tasks
- Use the benchmark to practice real backend workflows (Docker, APIs, dependency resolution) and showcase deployable solutions.
- Sectors: individual developers, bootcamps.
- Tools/workflows: Personal “agent pair-debugging” sessions; public portfolios referencing pass@1 on tasks.
- Assumptions/dependencies: Local Docker, time budget, task selection matching skill level.
- Governance (internal policy): AI coding policy requiring end-to-end validation
- Codify that agent-generated code must pass external API tests and environment build checks before merge.
- Sectors: compliance, engineering leadership.
- Tools/workflows: Policy templates; mandatory ABC-style gates.
- Assumptions/dependencies: Executive buy-in; alignment with existing QA standards.
Long-Term Applications
The following use cases require additional research, scaling, safety engineering, or ecosystem adoption before wide deployment.
- Autonomous DevOps/back-end engineer agents
- Agents that autonomously progress from issue analysis to code edits, environment synthesis, container build, deploy, and pass E2E tests.
- Sectors: software, cloud, platform engineering.
- Tools/products/workflows: “Auto-DevOps Agent” services; approval pipelines with human-in-the-loop sign-off.
- Assumptions/dependencies: Higher S1/S2 reliability, robust guardrails, change management, auditability.
- Standardized certification for AI coding systems
- Industry or regulatory “ABC-certified” labels indicating an agent’s proficiency across stacks with E2E verification.
- Sectors: policy, procurement, regulated industries (healthcare, finance).
- Tools/workflows: Certification test suites; reporting schemas; compliance mappings.
- Assumptions/dependencies: Community consensus on metrics; governance bodies; periodic re-certification.
- Managed cloud services for agentic backend testing
- Cloud providers offer “Agentic Backend Testing” as a hosted service: spin sandboxes, run API tests, produce compliance reports.
- Sectors: cloud platforms, enterprise IT.
- Tools/products/workflows: Cloud-native ABC pipelines; SLAs; artifact registries.
- Assumptions/dependencies: Integration with provider IAM, VPC isolation, cost controls.
- Automatic environment synthesis platforms (“EnvSynth”)
- Generalized environment inference engines that generate Dockerfiles, Compose files, Helm charts from repo analysis and pass deployment checks.
- Sectors: platform engineering, DevOps tooling.
- Tools/products/workflows: EnvSynth IDE extensions; repo scanners; continuous environment drift correction.
- Assumptions/dependencies: Accurate dependency graphing; multi-OS coverage; secrets/config management.
- Agent-in-the-loop production change management
- Continuous agent-driven remediation (dependency updates, config fixes) validated via live canary E2E tests and automated rollbacks.
- Sectors: SRE, reliability engineering.
- Tools/workflows: Canary deploy orchestration; agent rollbacks; error-budget aware policies.
- Assumptions/dependencies: Strong observability; safe rollback paths; incident governance.
- Sector-specific compliance benchmarks and packs
- ABC-style benchmarks tailored to privacy, security, and reliability requirements (HIPAA, PCI DSS, SOX) with domain-specific API tests.
- Sectors: healthcare, finance, public sector.
- Tools/workflows: Compliance test generators; audit artifacts; exception handling policies.
- Assumptions/dependencies: Legal alignment; domain expert test design; secure data handling.
- Cross-language universal orchestration and tooling
- Expanded benchmarks and agents that robustly handle less common stacks (e.g., Rust) and mixed polyglot services.
- Sectors: software, embedded systems.
- Tools/workflows: Polyglot build orchestrators; language-aware agent toolkits.
- Assumptions/dependencies: Broader task coverage; improved multilingual model training; better tool adapters.
- Education at scale: programmatic lab builder and auto-grading
- Large-scale course infrastructure that generates tasks, spins per-student containers, auto-grades via E2E tests, and provides agent feedback.
- Sectors: higher education, online learning platforms.
- Tools/workflows: Lab-generation APIs; grading pipelines; feedback analytics.
- Assumptions/dependencies: Scalable compute; anti-cheating measures; equitable access.
- Robotics/IoT edge backend validation
- Use ABC-style API test synthesis and container builds to validate microservices supporting edge devices, gateways, and digital twins.
- Sectors: robotics, manufacturing, energy.
- Tools/workflows: Edge-compatible containers; hardware-in-the-loop simulators; network-constrained testing.
- Assumptions/dependencies: Hardware integration; real-time constraints; protocol coverage.
- Research: Long-horizon planning, tool-use, and environment reasoning
- Develop model architectures and training regimes that sustain >60-turn interactions, robustly interpret logs, and recover from env failures.
- Sectors: AI research, foundation model development.
- Tools/workflows: Trajectory datasets, curriculum learning, reflective planning loops.
- Assumptions/dependencies: Access to large-scale high-quality agent traces; reliable evaluation harnesses; compute resources.
Glossary
- Agent framework: The orchestration layer that manages how an LLM agent interacts with tools and environments. "as the default agent framework for all models."
- Agentic backend coding: Using autonomous LLM agents to perform backend development tasks end-to-end. "evaluate agentic backend coding within a realistic, executable workflow."
- Agentic loop: An iterative agent workflow where the model observes, acts, and learns from execution feedback. "an agentic loop in which LLMs iteratively inspect repositories, modify code, and refine solutions based on execution feedback."
- Agentic post-training: Additional training tailored to agent behaviors or workflows to improve multi-step capabilities. "Effect of Agentic Post-Training."
- API-level integration tests: Tests that validate a running service via external API calls to ensure components work together. "external API-level integration tests"
- Autonomous environment configuration: The agent independently sets up dependencies and runtimes needed to run the service. "92 additionally require autonomous environment configuration and containerized service startup"
- Build Success (S1): A metric indicating whether the service environment was successfully built and started. "Build Success ()"
- Closed-loop evaluation: An end-to-end assessment that feeds execution results back into the agent workflow. "the closed-loop evaluation process."
- Conditional End-to-End Success (S2): Functional success measured only on the subset of tasks that have built and started. "Conditional End-to-End Success ()"
- Container orchestration: Coordinating containerized services and their lifecycles across components. "container orchestration."
- Containerized service: An application packaged with its environment in a container image and run as an isolated service. "instantiate a containerized service."
- Deployment-ready (backend service): A backend that can be built, started, and validated under realistic conditions. "deliver a deployment-ready backend service in a realistic stack"
- Docker configurations: Files and settings (e.g., Dockerfile, compose) that define how to build and run containers. "update Docker configurations"
- Docker image: A built, portable container artifact that packages code and dependencies for execution. "builds a Docker image from the agent's output"
- End-to-End (E2E) Testing: Testing that exercises the system through its public interfaces, validating complete behavior. "(5) End-to-End Testing (E2E)."
- Environment configuration: Preparing system dependencies and settings required to build and run software. "rigorous environment configuration"
- Environment provisioning: Allocating and preparing compute resources and dependencies to host and run a service. "environment provisioning, deployment, and live service validation."
- Environment Synthesis: Automated generation of container/runtime setup from a repository’s requirements. "Phase 2: Environment Synthesis."
- Execution-driven approach: Evaluation based on running the system and observing behavior, not just static code inspection. "This execution-driven approach ensures that agents are evaluated not on static code artifacts, but on their ability to deliver a functioning, production-ready service."
- Ground truth environment: The verified, correct runtime setup used as a reference to validate tasks and tests. "verify the correctness of the ground truth environment"
- Inner container: The evaluation container where the candidate service is built and run, separate from the agent’s workspace. "in a separate inner container"
- Interaction budget: A cap on steps, tool calls, or tokens that bounds the agent’s multi-step process. "when the interaction budget limits are reached"
- Isolated sandbox environment: A controlled, separated workspace to ensure reproducibility during evaluation. "a standardized, isolated sandbox environment"
- Masking-based strategy: Creating tasks by removing (masking) key implementation parts to simulate a pre-implementation state. "a masking-based strategy"
- Outer container: The container that hosts the agent process and its tools, separate from the service under test. "an outer container that hosts the agent"
- Pass@1: The probability that the top (first) attempt solves a task, often reported as a percentage. "average pass@1 (\%)"
- Production-like environment: An execution setting that closely mirrors real deployment conditions for validation. "ensuring the fix works in a production-like environment."
- Repository exploration: Systematic navigation of a codebase to locate relevant files, endpoints, and logic. "autonomous repository exploration"
- Reverse operation: Restoring masked code by applying the inverse of a patch to construct a solvable task. "apply a reverse operation"
- Runtime image: A container image that includes all runtime dependencies needed to start and run the service. "build the runtime image"
- Runtime synthesis: Automated creation of the runtime environment (e.g., Dockerfiles, dependencies) for a repository. "advances to runtime synthesis."
- Service connectivity: The ability of the deployed service to accept connections and respond on expected ports and endpoints. "service connectivity"
- Supervised fine-tuning (SFT): Training a model on labeled trajectories or demonstrations to improve behaviors. "supervised fine-tuning (SFT)"
- Verification suite: A set of tests that check service startup, connectivity, and functional correctness. "dedicated verification suites"
Collections
Sign up for free to add this paper to one or more collections.