- The paper introduces LoCoBench, a benchmark that evaluates long-context LLMs in complex software tasks using a systematic five-phase pipeline.
- The paper employs 17 metrics—including novel ones like ACS and DTA—to assess model performance over 8,000 scenarios spanning 10 languages and 36 domains.
- The paper’s experimental results reveal model specialization in tasks such as architectural understanding while highlighting challenges in long-context utilization.
LoCoBench: A Comprehensive Benchmark for Long-Context LLMs in Complex Software Engineering
Motivation and Benchmark Design
The proliferation of LLMs with million-token context windows has exposed a critical gap in the evaluation of software engineering capabilities: existing benchmarks are fundamentally inadequate for assessing long-context reasoning, architectural understanding, and multi-file workflows. LoCoBench addresses this gap by introducing a systematic, large-scale benchmark specifically designed to evaluate LLMs in realistic, complex software development scenarios. The benchmark is constructed via a five-phase pipeline that generates 8,000 evaluation scenarios across 10 programming languages and 36 domains, with context lengths ranging from 10K to 1M tokens.
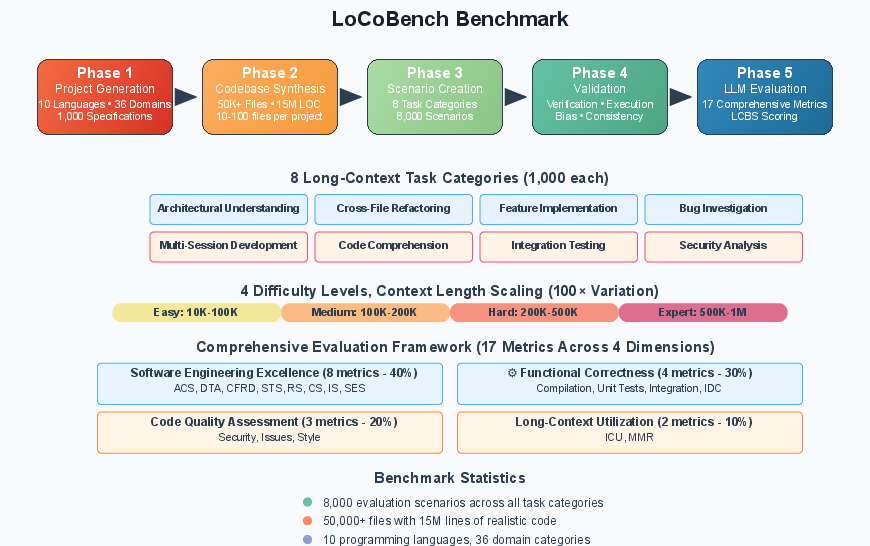
Figure 1: The LoCoBench pipeline systematically transforms high-level specifications into a comprehensive, multi-phase evaluation benchmark for long-context LLMs.
The pipeline ensures diversity and realism by generating 1,000 project specifications, each mapped to a complete, multi-file codebase. These codebases are then transformed into evaluation scenarios spanning eight long-context task categories, with rigorous automated validation for compilation, quality, and bias. The final phase evaluates LLMs using 17 metrics across four dimensions, including six novel metrics tailored for long-context software engineering.
Coverage and Diversity
LoCoBench achieves comprehensive coverage across programming languages, domains, architecture patterns, project themes, and complexity levels. Each language is equally represented, spanning paradigms from systems programming (C, C++, Rust) to web (JavaScript, TypeScript, PHP), enterprise (Java, C#), and modern scripting (Python, Go). The domain taxonomy covers 36 sub-categories grouped into 10 main categories, ensuring broad applicability.


Figure 2: LoCoBench provides balanced coverage across 10 programming languages and 36 hierarchical domains, supporting systematic evaluation of diverse software engineering scenarios.
Additional uniqueness factors include 10 architecture patterns (e.g., microservices, serverless, monolithic), 8 project themes (e.g., business, healthcare, entertainment), and 4 complexity levels (easy, medium, hard, expert), each with 25% representation. This systematic diversity enables fine-grained analysis of model performance across software paradigms and difficulty spectra.
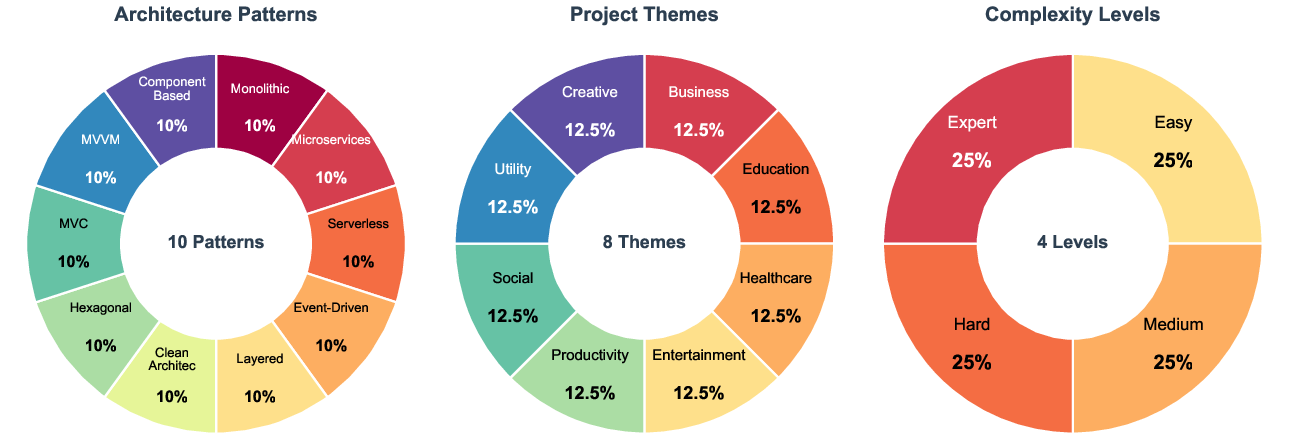
Figure 3: LoCoBench's independent factors—architecture patterns, project themes, and complexity levels—enable comprehensive, multi-dimensional evaluation.
Benchmark Statistics and Realism
The benchmark's scale and realism are validated by the distribution of lines of code and file counts, which mirror real-world software systems. The mean project size is 14,559 lines of code and 48.7 files, with right-skewed distributions reflecting both compact and enterprise-scale systems. Language-specific analysis reveals expected complexity patterns: systems languages yield compact, high-complexity codebases, while object-oriented and web languages exhibit larger, more modular structures.
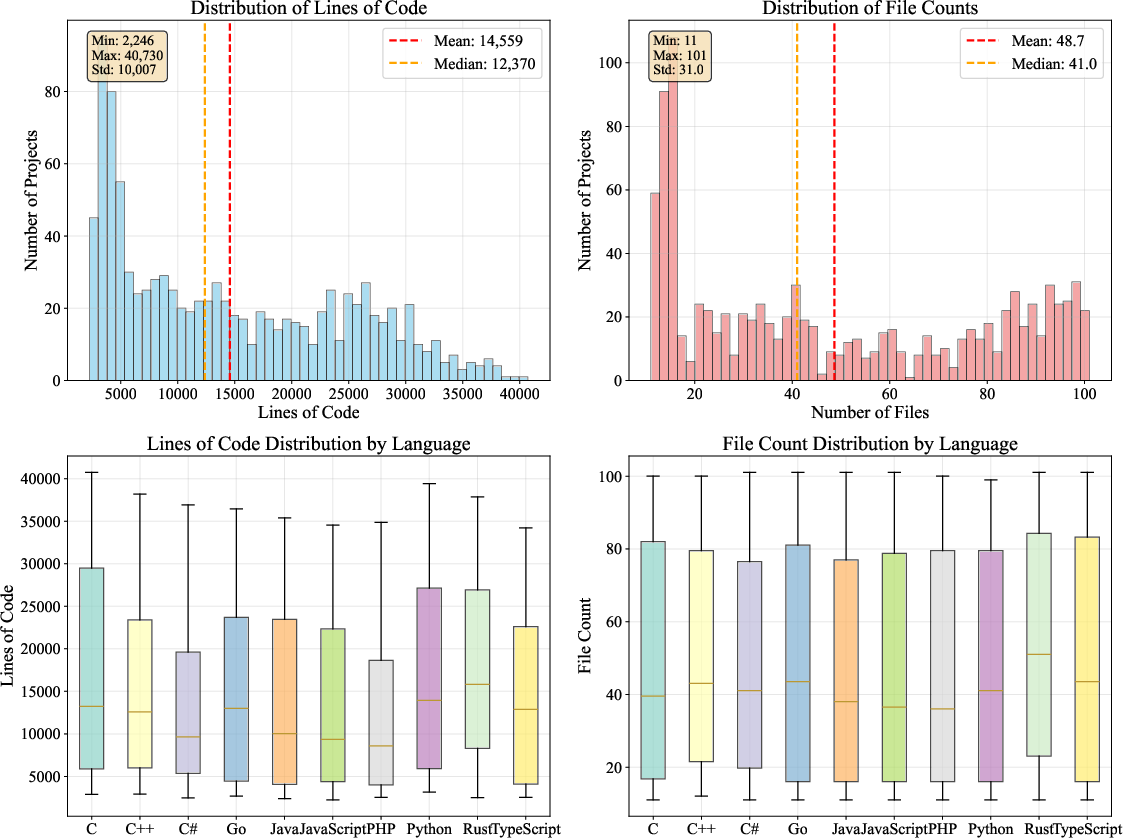
Figure 4: LoCoBench's project statistics demonstrate realistic distributions of code size and file count, with language-specific complexity patterns.
Task Categories and Long-Context Capabilities
LoCoBench evaluates eight task categories essential for long-context software engineering:
- Architectural Understanding: System design, pattern recognition, and component relationship analysis.
- Cross-File Refactoring: Multi-file code restructuring with architectural constraint preservation.
- Feature Implementation: Integration of new functionality into existing systems.
- Bug Investigation: Root cause analysis across multi-file systems.
- Multi-Session Development: Context retention and incremental development across sessions.
- Code Comprehension: Deep understanding and information extraction from large codebases.
- Integration Testing: System-level validation of component interactions.
- Security Analysis: Vulnerability assessment and secure design.
Difficulty is systematically calibrated, with context scaling from 10K (easy) to 1M (expert) tokens, enabling precise measurement of performance degradation as context and complexity increase.
Evaluation Metrics and Scoring
LoCoBench introduces a 17-metric framework across four dimensions:
- Software Engineering Excellence (8 metrics): Includes new metrics such as Architectural Coherence Score (ACS), Dependency Traversal Accuracy (DTA), and Cross-File Reasoning Depth (CFRD).
- Functional Correctness (4 metrics): Compilation, unit/integration test performance, and Incremental Development Capability (IDC).
- Code Quality Assessment (3 metrics): Security, issue count, and style adherence.
- Long-Context Utilization (2 metrics): Information Coverage Utilization (ICU) and Multi-Session Memory Retention (MMR).
The unified LoCoBench Score (LCBS) is a weighted aggregate, with software engineering excellence prioritized (40%), followed by functional correctness (30%), code quality (20%), and long-context utilization (10%).
Experimental Results and Analysis
LoCoBench's evaluation of state-of-the-art LLMs (e.g., GPT-5, Gemini-2.5-Pro, Claude-Sonnet-4) reveals substantial performance gaps and specialization patterns. Gemini-2.5-Pro demonstrates superior performance in cross-file refactoring, long-context utilization, integration testing, and multi-session development, while GPT-5 excels in architectural understanding. Claude-Sonnet-4 shows balanced performance with strength in code comprehension.
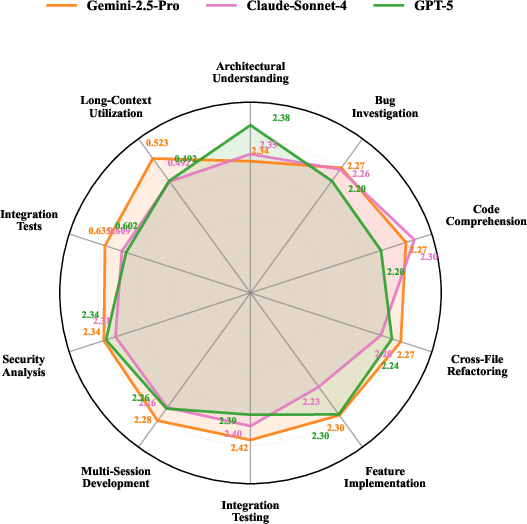
Figure 5: Model performance comparison across 10 LoCoBench dimensions, highlighting specialization and performance gaps.
Model ranking and long-context utilization analysis show that while top-tier models cluster closely in overall LCBS, their long-context processing capabilities diverge significantly, indicating that context management remains a major technical challenge.
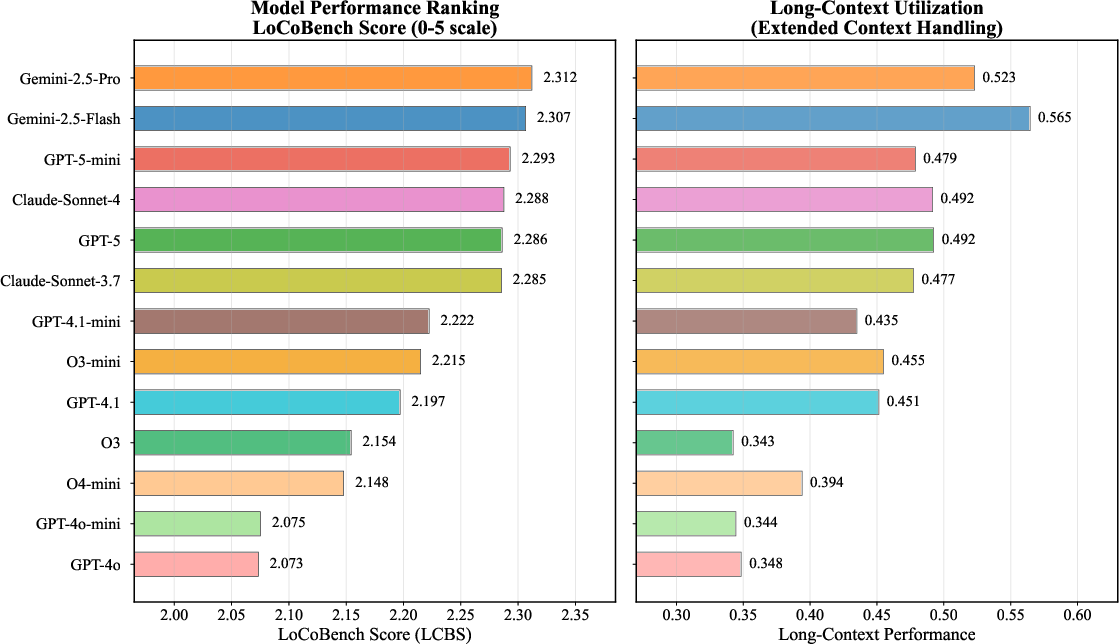
Figure 6: Left: LCBS model rankings. Right: Long-context utilization performance, revealing divergence in extended context handling.
Language, Task, and Domain Analysis
Performance heatmaps across languages show that models perform best on high-level languages (Python, PHP) and struggle with systems languages (C, Rust), reflecting both language complexity and training data distribution.
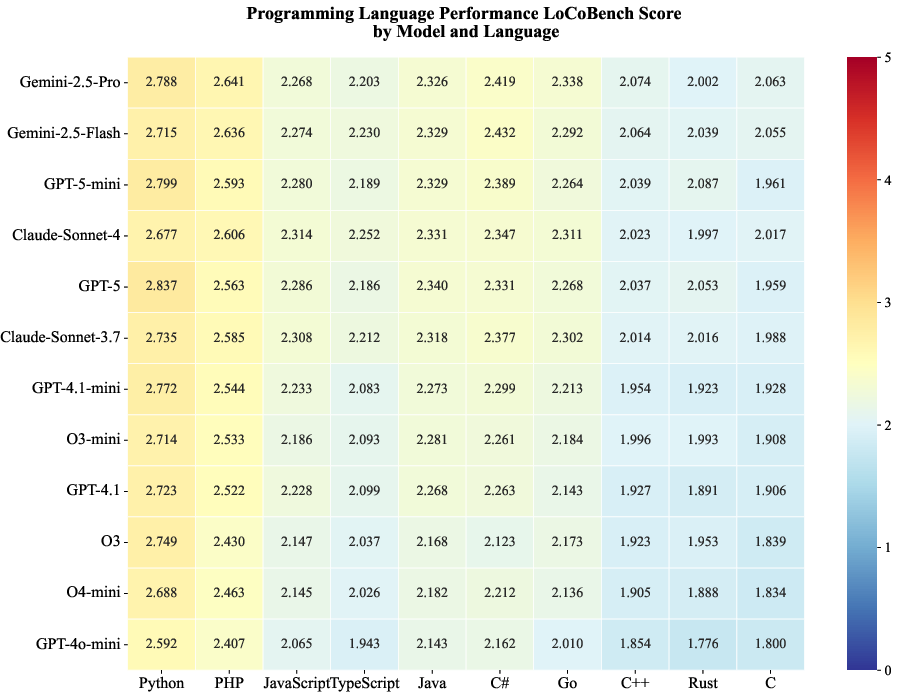
Figure 7: Programming language performance heatmap, ordered by increasing difficulty.
Task category analysis reveals that integration testing and architectural understanding are more tractable, while bug investigation and multi-session development remain challenging.
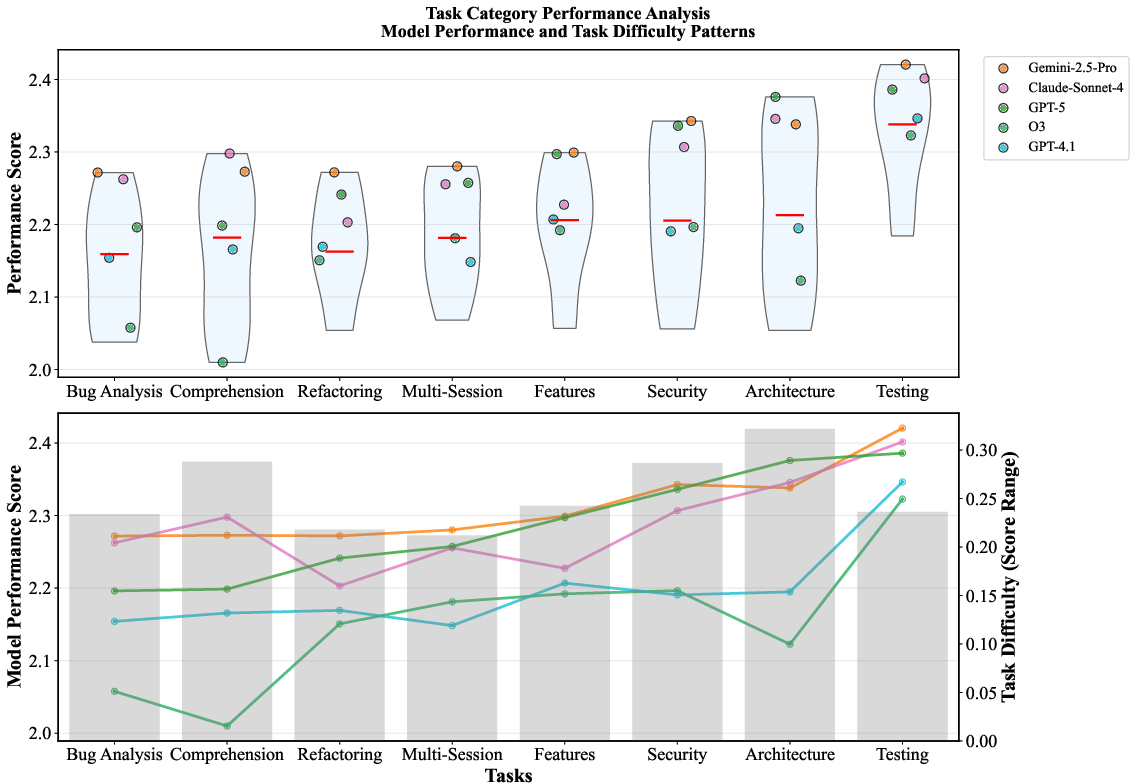
Figure 8: Top: Task category performance distribution. Bottom: Task difficulty and model performance trends.
Context length and difficulty scaling analysis demonstrates compounding performance degradation as both factors increase, with some models exhibiting graceful degradation and others showing sharp drops at higher difficulty levels.

Figure 9: Context length and difficulty impact analysis, including performance consistency and specialization patterns.
Domain specialization analysis shows that model performance varies significantly across application domains, with gaming simulation and API services posing greater challenges than blockchain or desktop applications.
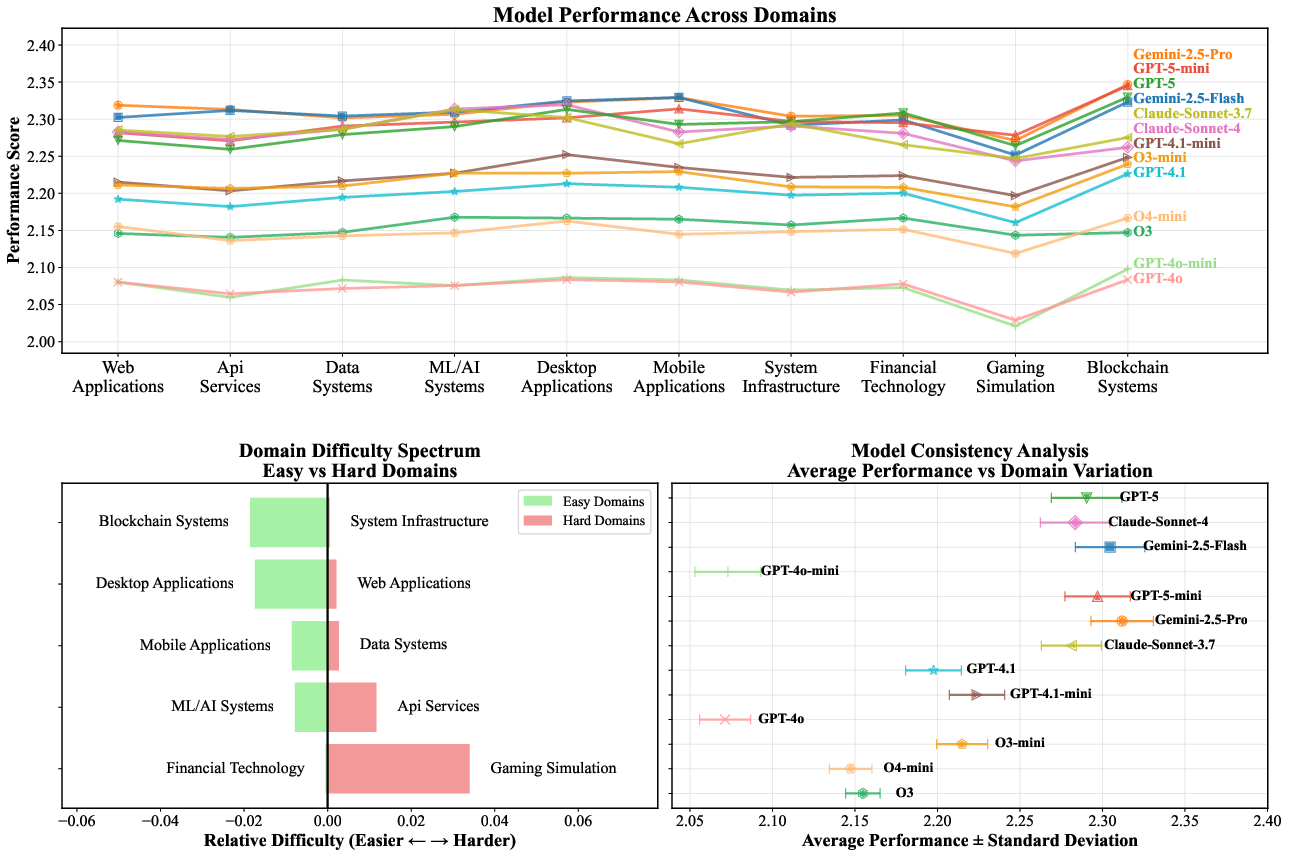
Figure 10: Domain specialization and performance analysis, including domain difficulty spectrum and consistency patterns.
Architectural Pattern Analysis
Performance across architectural patterns indicates that certain paradigms (e.g., microservices, hexagonal) are more challenging for LLMs, and that coupling/cohesion characteristics influence model success. Models optimized for specific patterns may not generalize well to others.
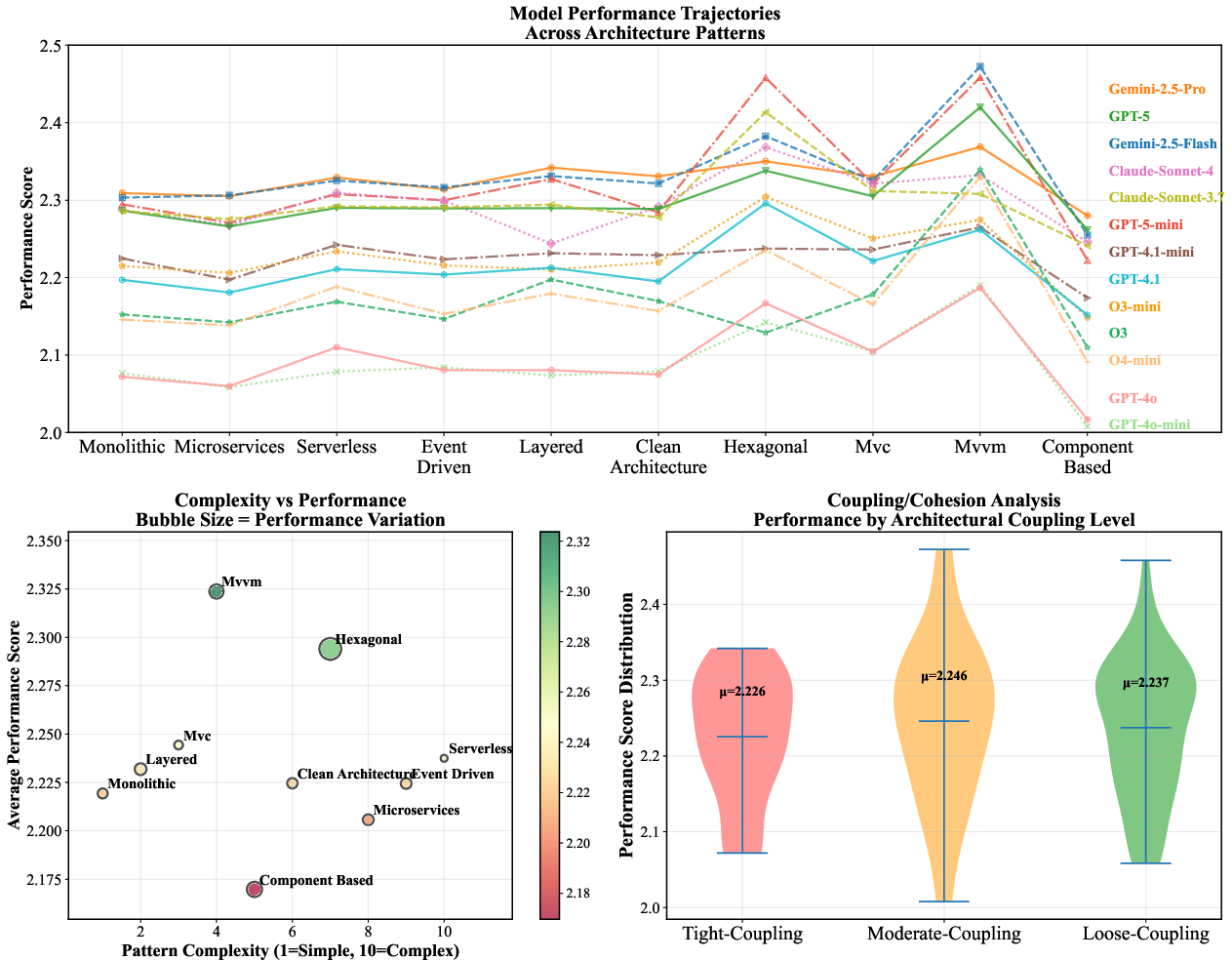
Figure 11: Architecture pattern performance analysis, including complexity-performance and coupling/cohesion relationships.
Implementation Considerations
LoCoBench's pipeline is fully automated, with deterministic project specification generation, architecture-aware codebase synthesis, graph-theoretic context selection, and multi-metric validation. The evaluation infrastructure supports any LLM with a standardized API, context windowing, and robust error handling. Resource requirements are substantial: codebase generation and validation require scalable compute and storage, and LLM evaluation at million-token contexts demands high-throughput inference infrastructure.
For practitioners, LoCoBench enables:
- Fine-grained benchmarking of LLMs for specific languages, domains, and architectural patterns.
- Systematic analysis of long-context degradation and specialization.
- Identification of model suitability for targeted software engineering workflows.
Implications and Future Directions
LoCoBench establishes a new standard for evaluating long-context LLMs in software engineering, revealing that current models exhibit significant specialization and performance gaps, especially as context and complexity increase. The results indicate that long-context understanding, architectural reasoning, and multi-session memory remain unsolved challenges. The benchmark's multi-dimensional metric system provides a foundation for tracking progress in these areas.
Future research should focus on:
- Architectures and training strategies optimized for long-context, multi-file reasoning.
- Enhanced memory and retrieval mechanisms for multi-session development.
- Domain- and pattern-specific fine-tuning to address specialization gaps.
- Extension of evaluation frameworks to interactive, tool-augmented development scenarios.
Conclusion
LoCoBench provides the first comprehensive, systematic benchmark for long-context LLMs in complex software engineering, enabling rigorous, multi-dimensional evaluation at scale. The benchmark's design, metrics, and experimental results highlight both the progress and the persistent limitations of current LLMs, offering actionable insights for model development, deployment, and future research in AI-assisted software engineering.

