Training AI Co-Scientists Using Rubric Rewards
Abstract: AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, LLMs currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train LLMs that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
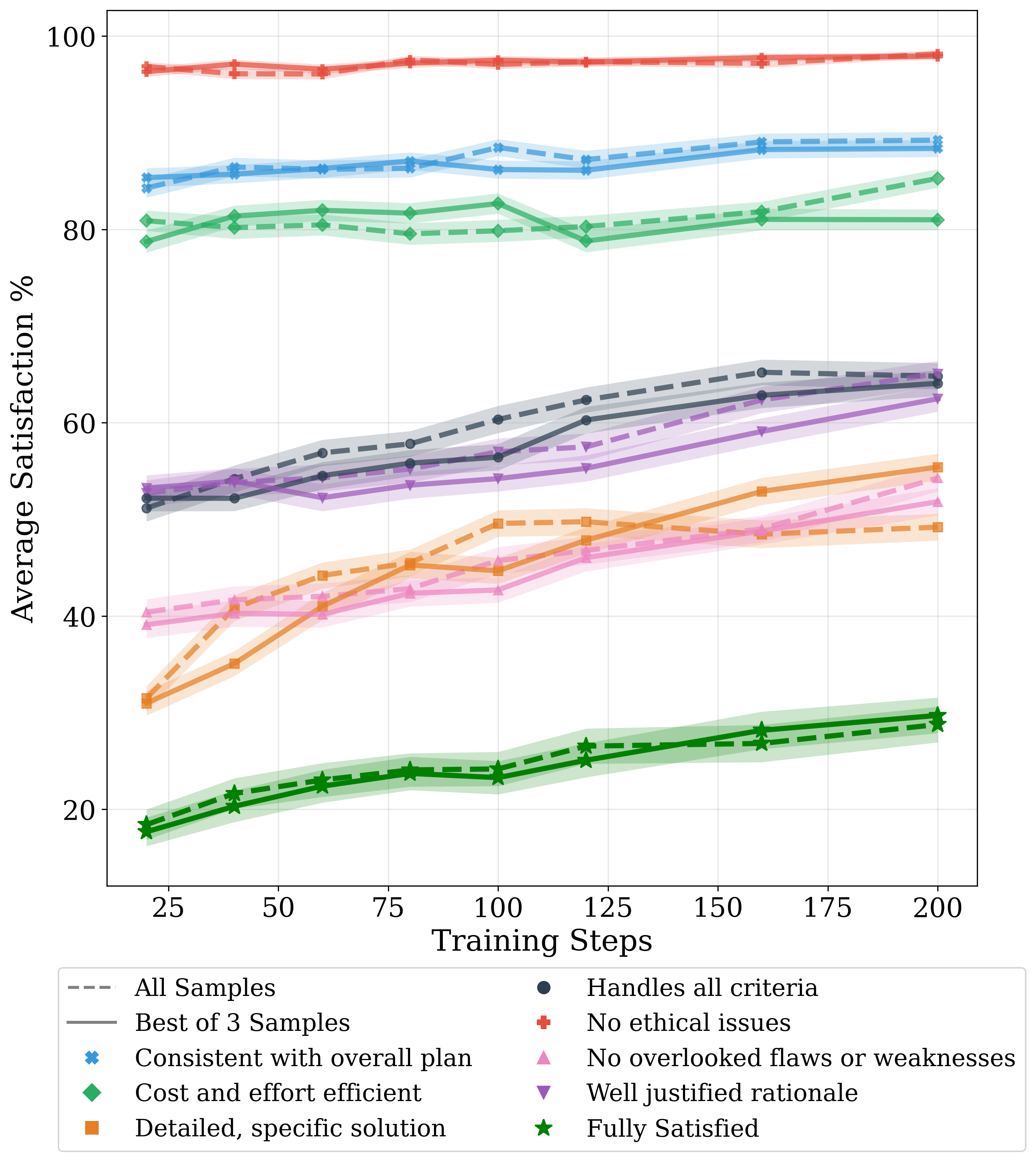
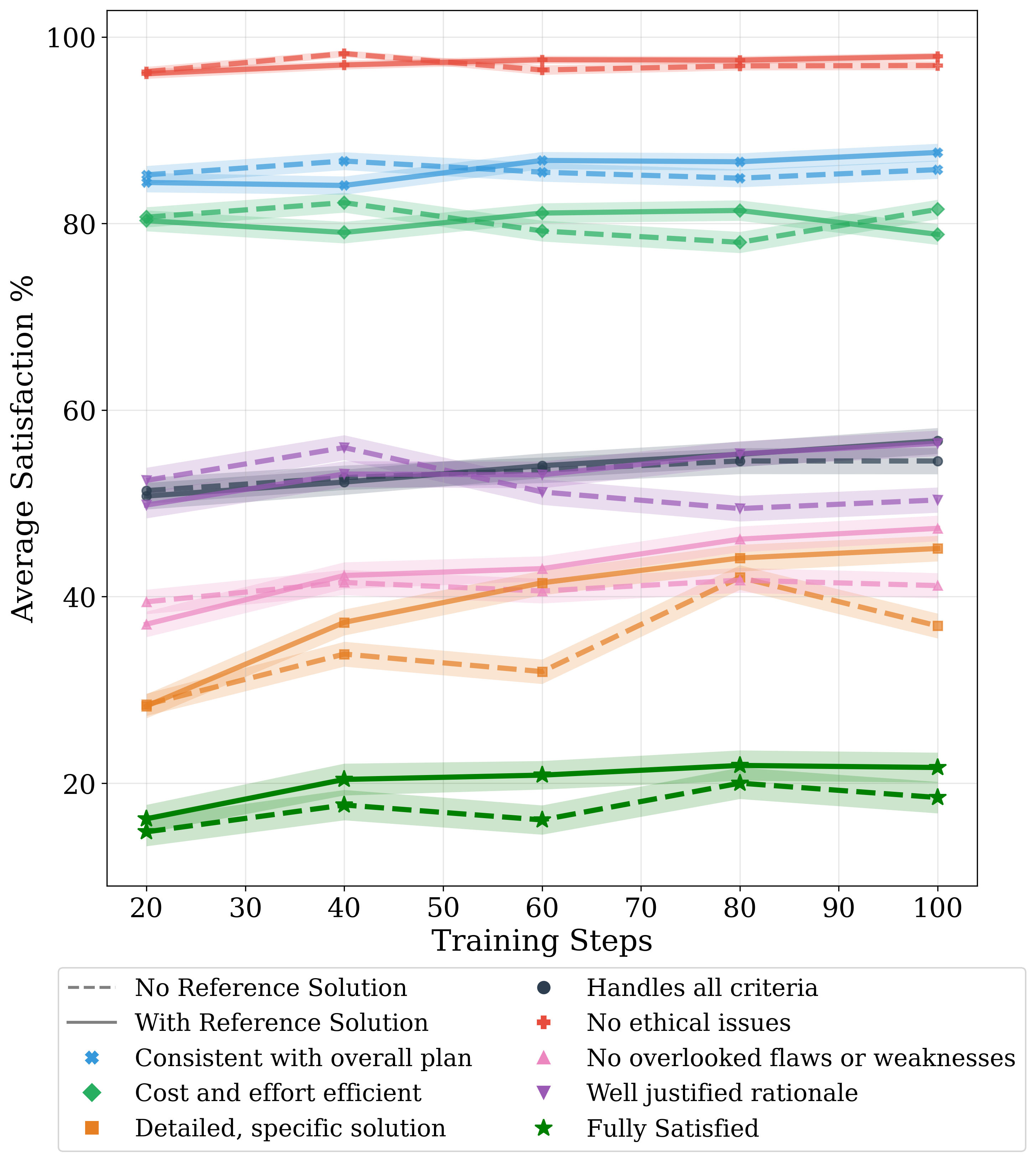
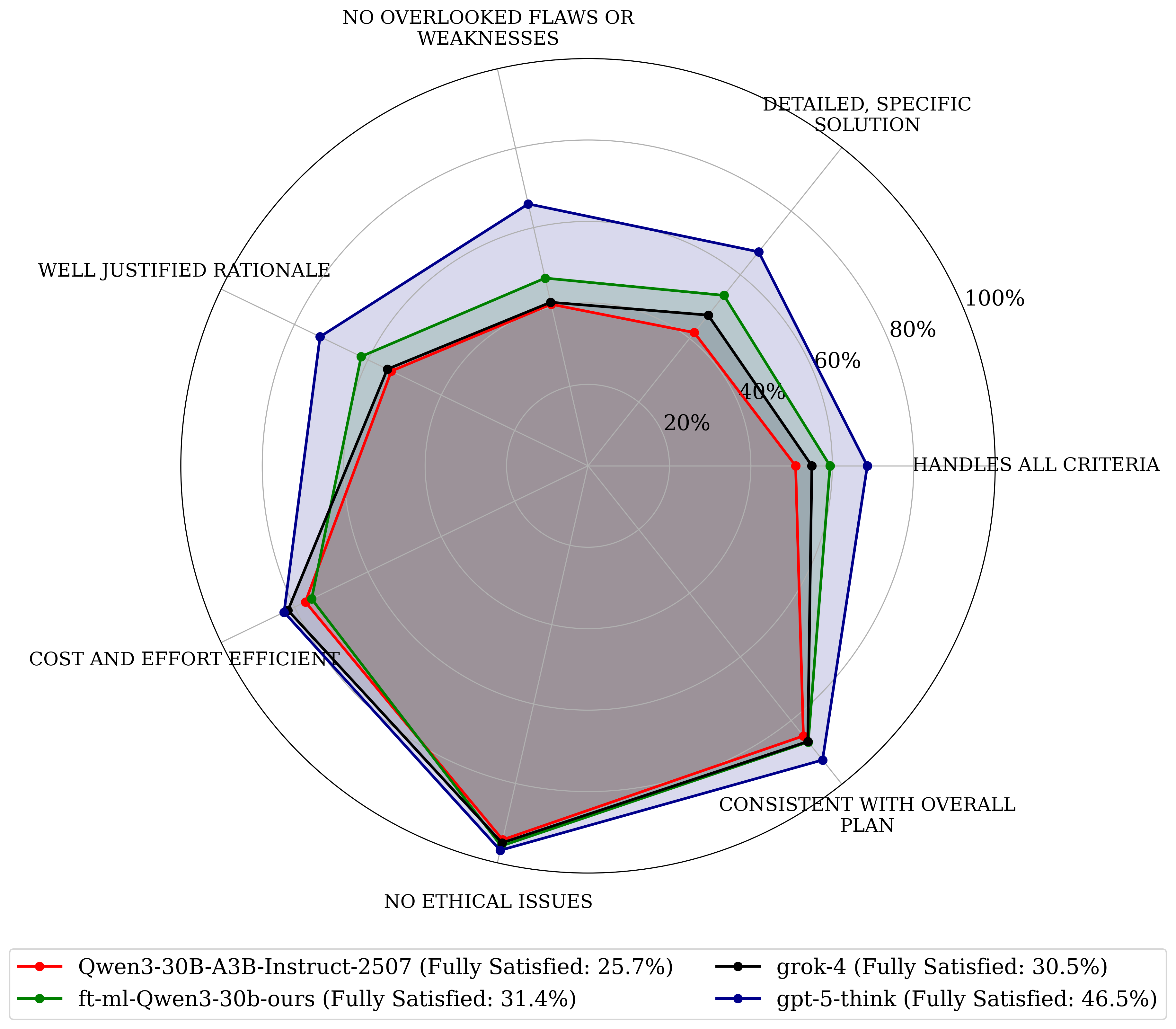
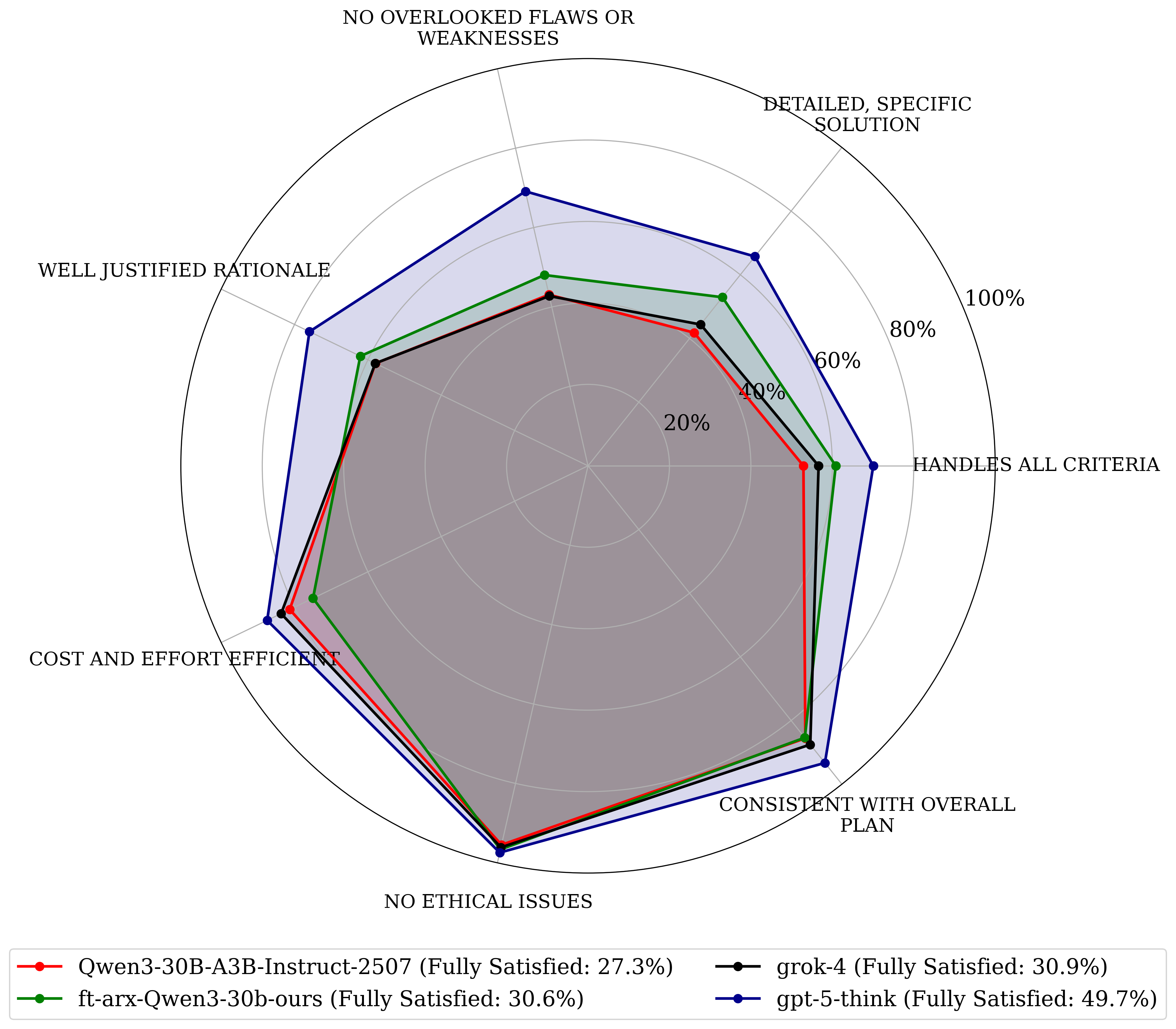

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper is about teaching an AI “co‑scientist” to write better research plans. A research plan is like a step‑by‑step blueprint for how to test an idea: what to try, how to measure success, what could go wrong, and how to fix it. Instead of making the AI run real experiments (which can be slow, costly, or even unsafe—especially in areas like medicine), the authors train it to write strong plans by learning from past scientific papers and using smart grading rules called rubrics.
The main questions the paper asks
- How can we train an AI to create detailed, practical research plans for open‑ended problems (not just math problems or coding tasks with exact answers)?
- Can we do this without running real experiments for feedback?
- Will this training work across different fields (like machine learning, medicine, and physics)?
- Do human experts actually prefer the AI’s plans after this training?
How they did it (the approach, explained with everyday ideas)
Think of a classroom where:
- The “student” is the AI that writes research plans.
- The “teacher” is a frozen copy of the same AI that only grades plans.
- The teacher has the answer key: a goal to plan for and a detailed grading rubric (a checklist of what a good plan must include).
Here’s the step‑by‑step idea:
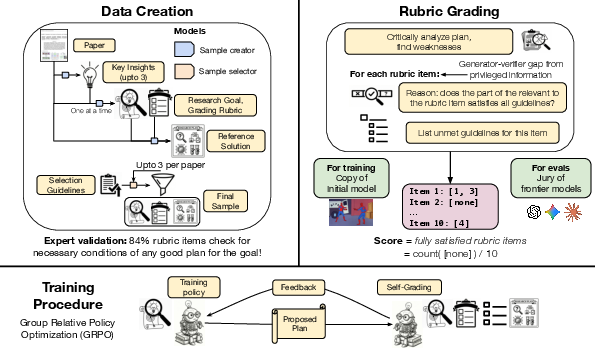
1) Turning papers into practice problems
The researchers automatically scan real scientific papers and extract:
- A research goal: the problem the original paper tried to solve, including constraints (like “must be fully automated”).
- A goal‑specific rubric: a list of must‑have items a good plan should include for that goal (e.g., “handles changing tools over time,” “avoids ethical issues,” “works with multiple models”).
- A reference solution: a model‑written example plan to help the grader understand the intent.
They use one AI to draft several candidate goal–rubric–solution sets from each paper and another AI to pick the best one. This creates a large training set called ResearchPlanGen.
2) Training with “self‑grading” (like practicing essays with a checklist)
- The plan‑writing AI (the “student”) writes a plan for a goal.
- The grading AI (the “teacher,” a frozen copy) scores it using:
- The goal‑specific rubric (custom checks for that goal).
- Seven general guidelines that catch common mistakes, like:
- Don’t be vague.
- Justify your choices.
- Watch cost/effort.
- Avoid ethical issues.
- The student doesn’t see the rubric; only the teacher does. This makes grading easier than generation—like a teacher with a secret checklist—so the student has to truly improve to get higher scores. This is sometimes called a “generator–verifier gap.”
- The training method (a kind of reinforcement learning) is “try, get a score, improve.”
Analogy: It’s like practicing speeches where the judge checks a secret list of requirements. You don’t know the exact list, but you learn over time what gets you higher marks.
3) Keeping plans strong but not overly long
The AI is allowed to “think” as much as it wants privately, but the final written plan must fit a word limit. This prevents the AI from winning points by being overly long and helps it be clear and concise.
4) Guarding against “over‑fitting the judge”
The authors watch for signs that the student is just gaming the specific judge (the frozen teacher) instead of truly getting better. They check progress with stronger outside judges (frontier AI models) and stop training when general improvements level off.
What they found (results that matter)
- Human experts prefer the trained AI’s plans:
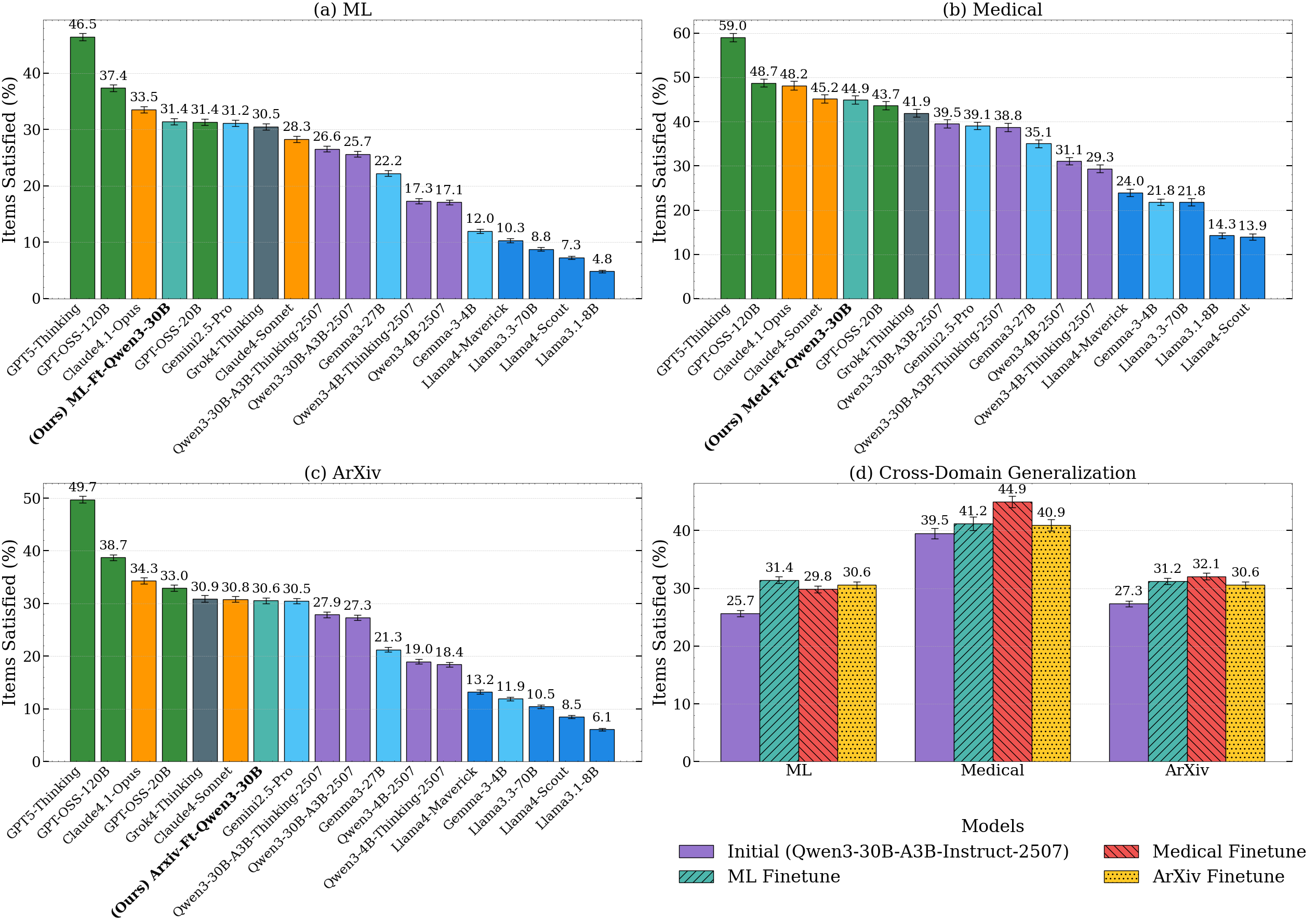
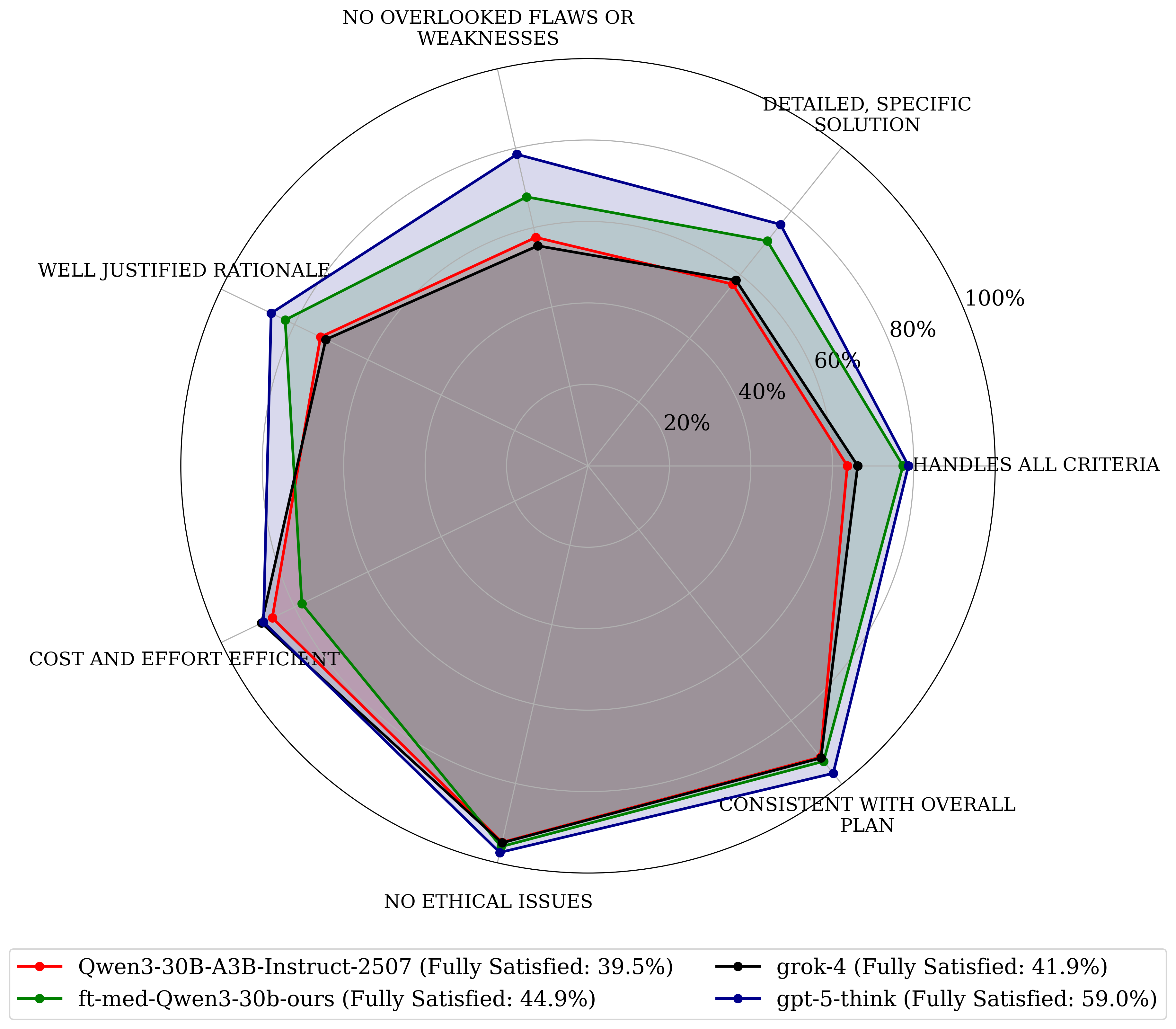
- In a 225‑hour study with 25 machine learning experts evaluating 100 problems, the trained model’s plans were preferred about 70% of the time.
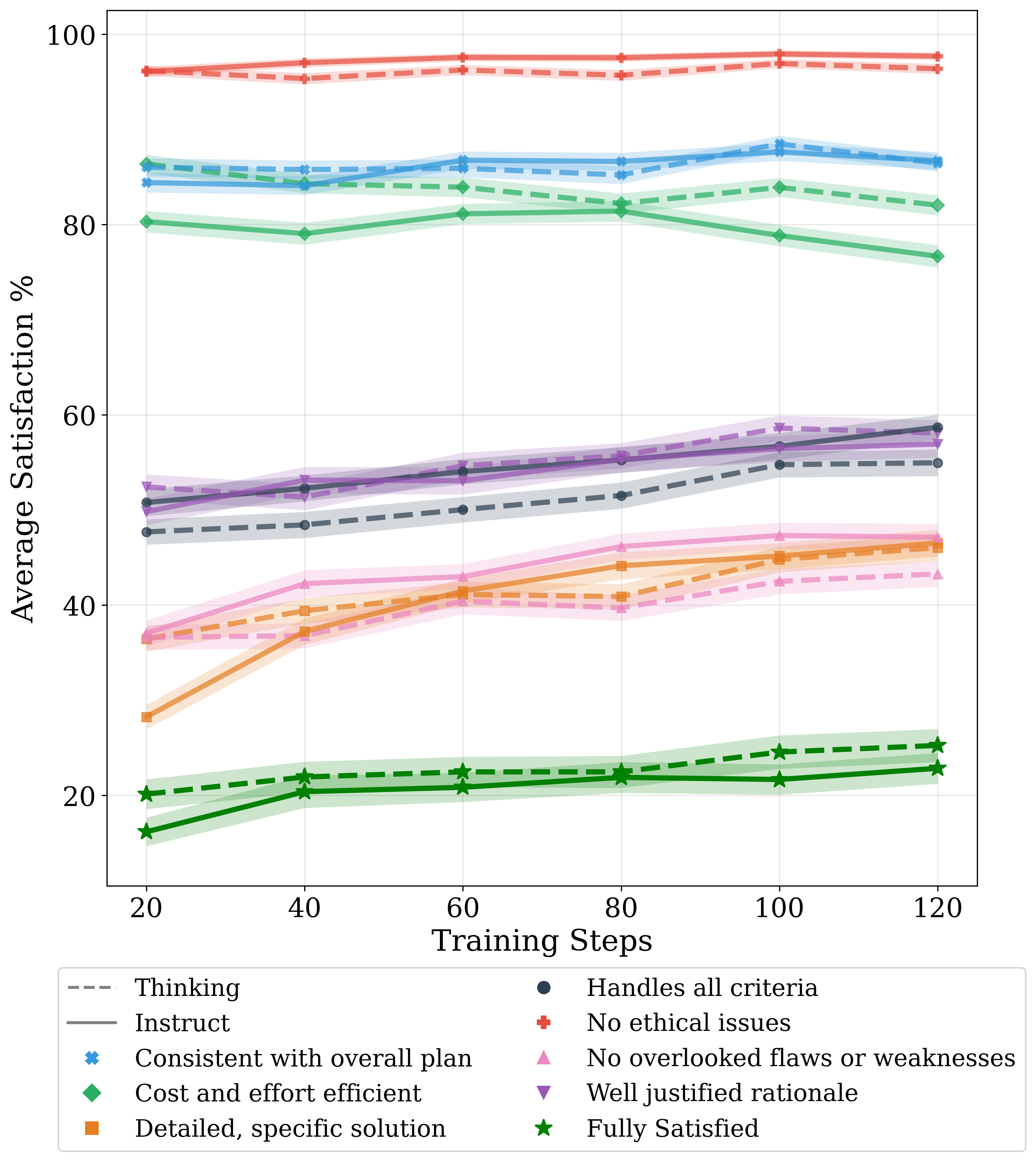
- Experts said the trained plans handled requirements better, were more thorough, and likely to lead to better outcomes. A trade‑off: they were sometimes a bit less simple to execute.
- The rubrics are good:
- Experts rated 84% of the rubric items as necessary parts of a strong plan, and average quality was 4.3/5. That means the automated method can reliably extract useful grading checklists from papers.
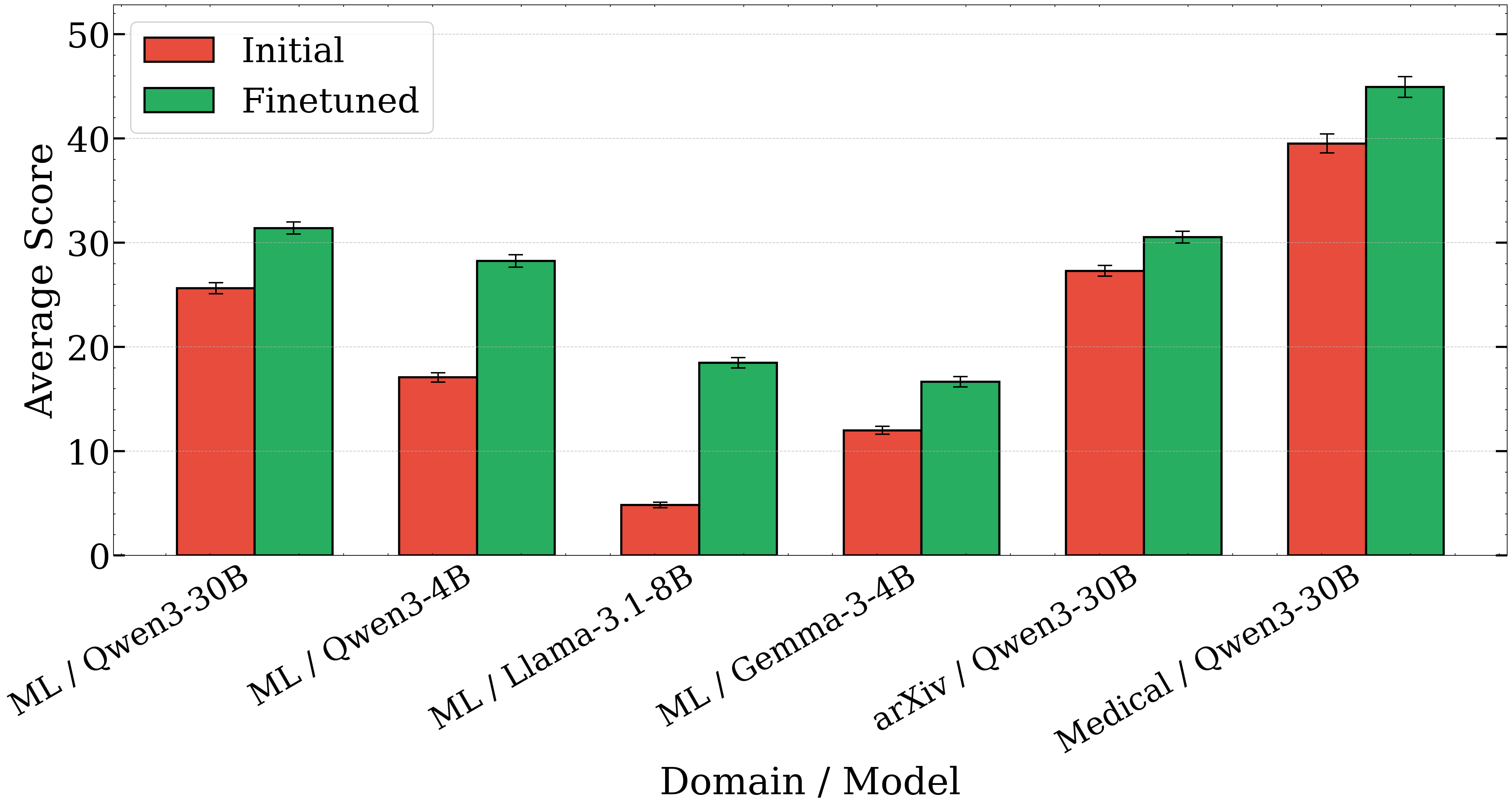
- It works across fields:
- Using automated “jury” grading from several strong AI models, the trained system improved by about 12–22% on research goals from medicine and fresh arXiv papers (new preprints).
- Training on one field (like medicine) still helped on others (like machine learning), suggesting the method teaches general good habits of planning.
- It’s competitive but not the best yet:
- The trained 30B‑parameter model became competitive with some large “thinking” models, though top frontier models still performed best.
- What didn’t work as well:
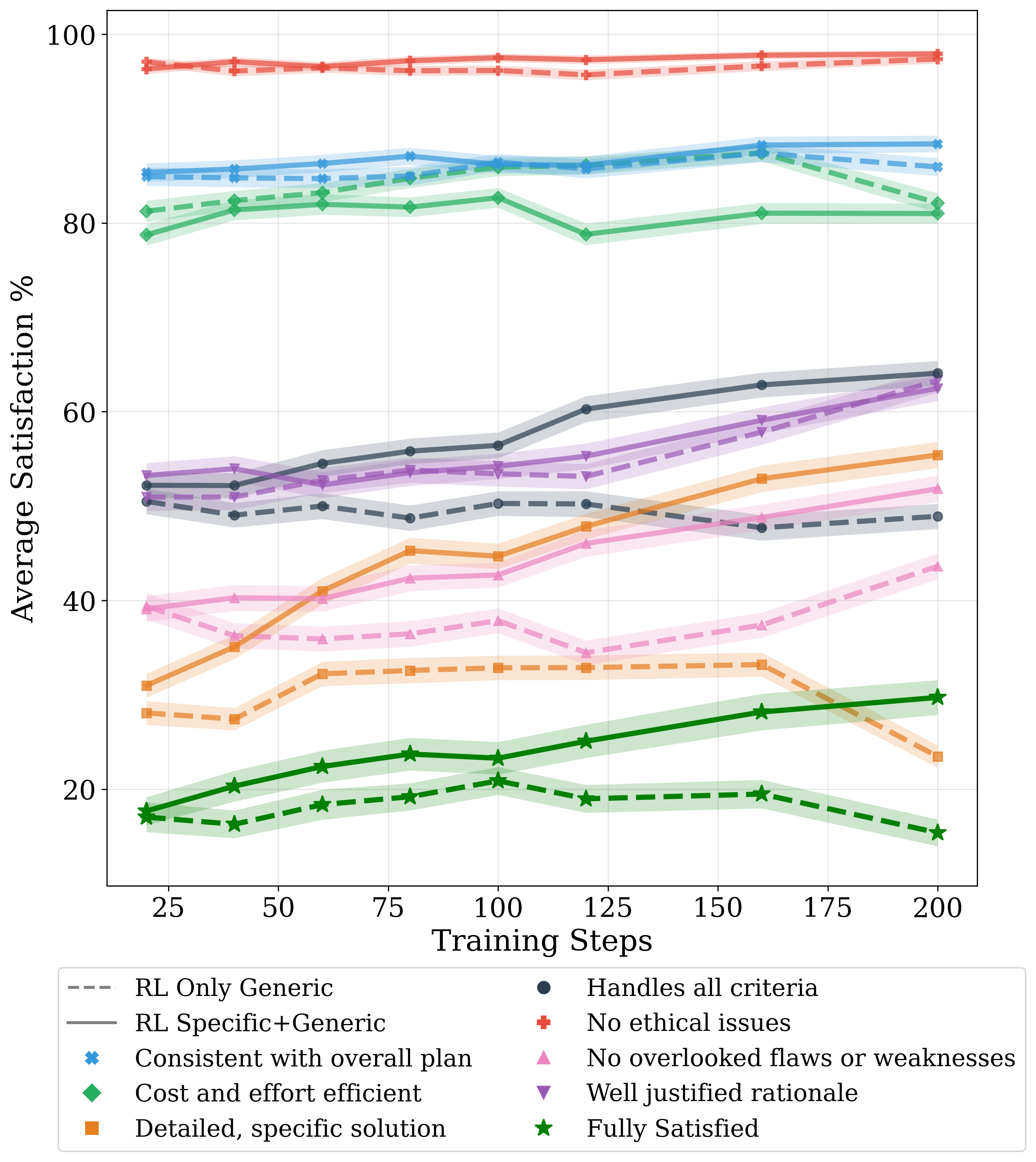
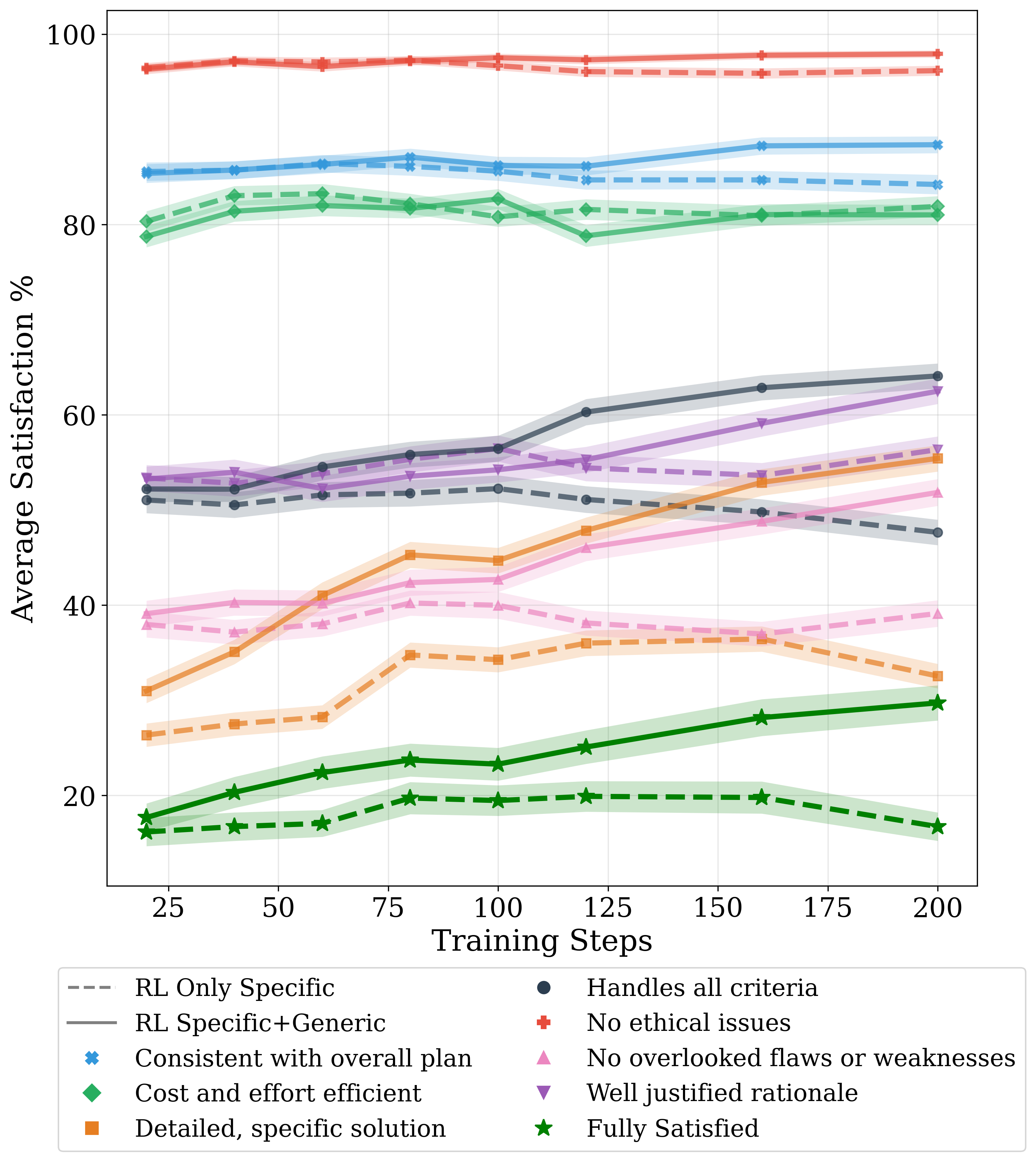
- Simple “copy‑the‑answer” training (supervised fine‑tuning) made plans worse—more style mimicry, less requirement‑following.
- The best results came from reinforcement learning with rubric rewards, a stronger grader, and both custom (goal‑specific) and general guidelines.
Why this matters (implications and potential impact)
- Scalable and safer training: The method improves planning without running real experiments. That saves time and money and avoids risky or unethical test runs (especially in medicine).
- Better AI lab partners: The AI becomes a stronger “co‑scientist” that can propose practical, well‑justified plans researchers can refine and use.
- Works beyond one domain: Because it learns general planning habits, it can adapt to many areas of science.
- Open resources: The authors release ResearchPlanGen, a new dataset to help others build and test AI co‑scientists.
- Human in the loop: The AI doesn’t replace scientists’ judgment. People still set goals, check for novelty and importance, and decide what to actually run. But this can speed up brainstorming, organization, and rigor in early‑stage planning.
In short, the paper shows a promising, scalable way to train AI to write high‑quality research plans by learning from science itself and using smart rubrics for feedback—bringing us a step closer to useful, reliable AI co‑scientists.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up work.
- External validity beyond rubric satisfaction: there is no systematic, implemented evaluation showing that generated plans, when executed, lead to better empirical outcomes across domains; conduct randomized implementation studies (or simulated execution where possible) to measure end-to-end effectiveness.
- Limited human evaluation scope: human expert judgments were only collected for ML (100 goals, 225 hours); expand to medical and arXiv domains with larger, stratified samples and report inter-rater reliability and topic coverage.
- Reliance on model-based judges: medical and arXiv results hinge on automated rubric juries; quantify and mitigate judge bias, and validate with humans to establish alignment and robustness across graders.
- Weak grader alignment: Cohen’s κ with human consensus is 0.297; develop stronger cross-grader calibration, ensembles, and adjudication protocols to raise agreement toward human gold standards.
- Reward overoptimization: observed divergence between self-grader gains and stronger grader scores; design adversarial and cross-judge regularizers, randomized rubric variants, and early-stopping criteria grounded in held-out human checks.
- Cost-efficiency degradation: training worsened cost/effort efficiency per held-out grader; incorporate explicit resource budgets, complexity penalties, and multi-objective reward terms to align with feasibility constraints.
- Static rubric weighting: all rubric items contribute equally; learn or elicit item importance weights (e.g., via expert elicitation or inverse propensity) and evaluate if weighted rewards improve practical utility.
- Rubric quality outside ML: human validation of rubric items exists only for ML; assess rubric necessity/sufficiency in medical and arXiv sets, and measure error rates (missing/incorrect constraints).
- Data extraction fidelity: automated insight/goal/rubric extraction may hallucinate or misinterpret papers; audit a random sample across domains to quantify extraction precision/recall and introduce correction loops.
- Reference solution quality and influence: reference solutions used by graders were judged weak in ablations; evaluate whether grader access to low-quality references biases rewards, and test training without references or with vetted summaries.
- Generator–verifier gap size: using a frozen copy of the initial policy as grader may not create a sufficient difficulty gap; test stronger/verifiably independent graders and measure the effect on learning.
- Generality of guidelines: seven general guidelines are derived from prior LM failure modes; validate and expand domain-specific guidelines (e.g., regulatory/IRB compliance in medicine, reproducibility in ML) and measure impact on plan quality.
- Ambiguous or human-authored goals: goals are extracted from polished papers; assess performance on noisy, incomplete, or ambiguous human-written research aims, and add interactive clarification steps.
- Interactive co-scientist behavior: current setup is single-shot planning; study multi-turn workflows where the model asks questions, revises plans with feedback, and tracks assumptions and risks.
- Domain coverage gaps: outside ML/medical/arXiv (quantitative fields), many areas (chemistry wetlab, neuroscience, qualitative social sciences, field studies) are underrepresented; expand dataset diversity and measure cross-domain transfer.
- Contamination and pretraining overlap: medical corpus may overlap with base pretraining; quantify contamination and design held-out benchmarks with known non-overlap to isolate finetuning gains.
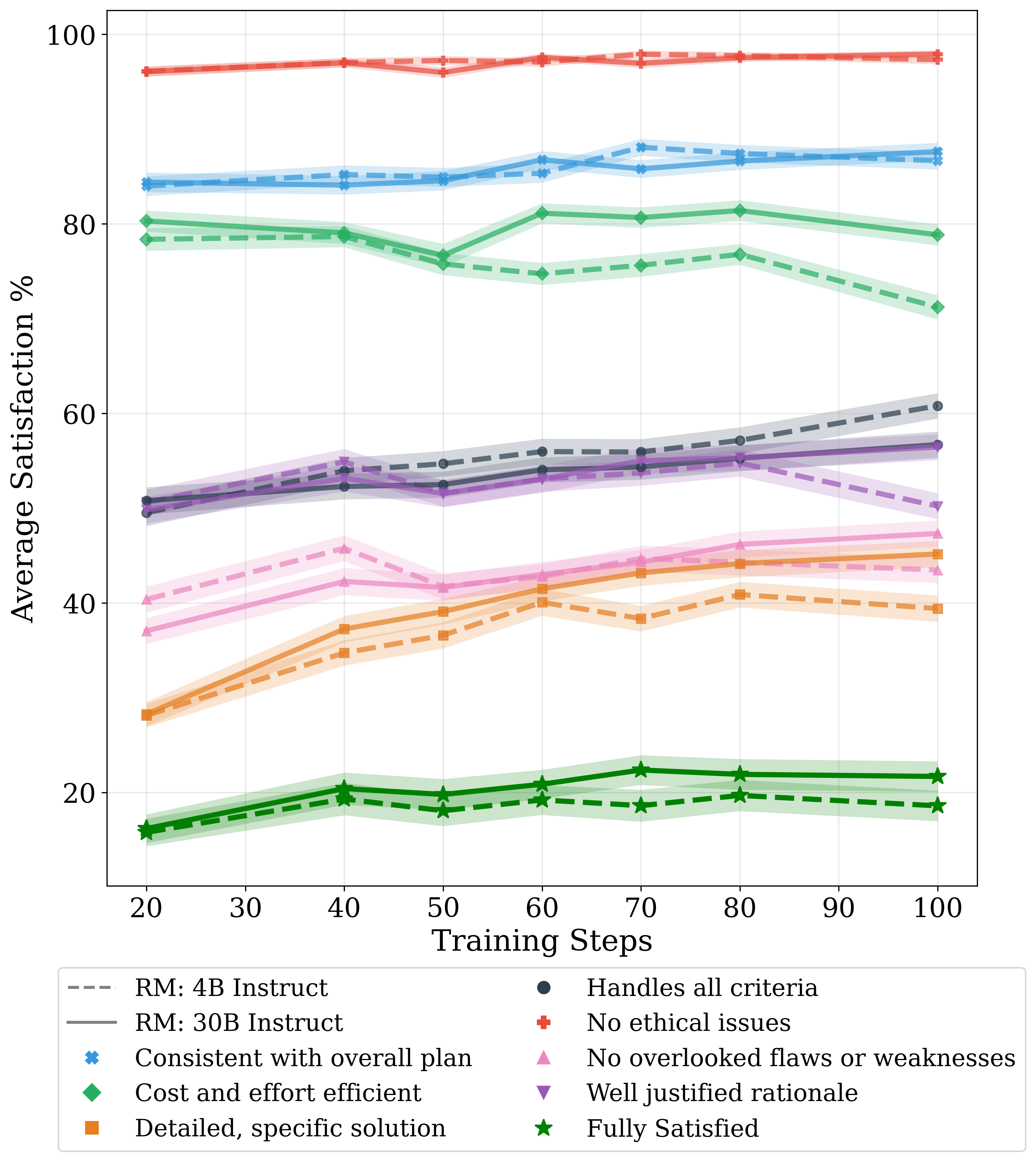
- Scaling laws and model size: improvements were shown for 4B and 30B MoE, but no systematic scaling analysis; study how performance, overoptimization, and cost scale with parameter count and grader strength.
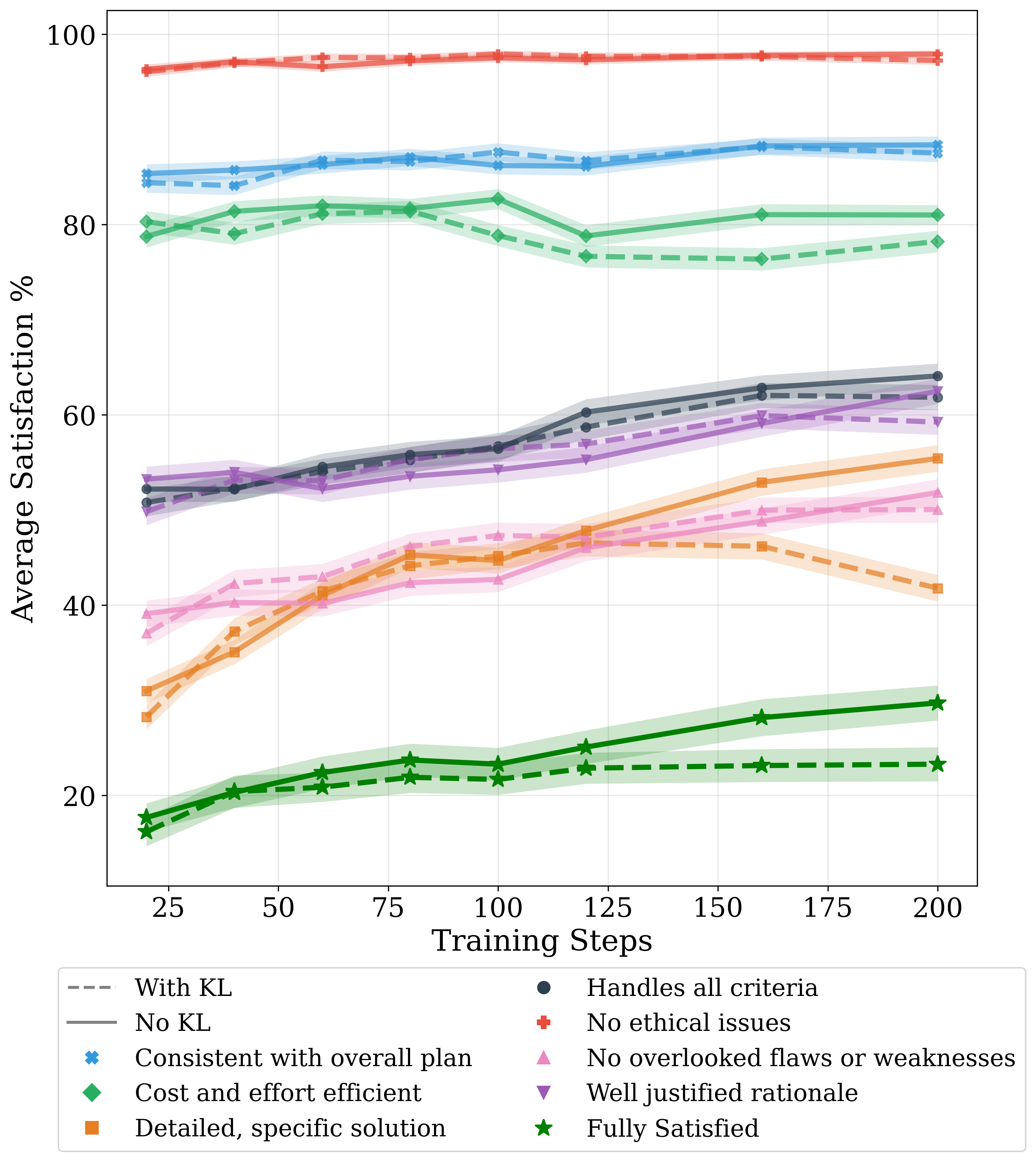
- Impact on non-planning capabilities: finetuning with disabled KL may cause drift; evaluate catastrophic forgetting and performance changes on unrelated tasks (coding, QA, reasoning).
- Prompt/format robustness: the length-control scheme depends on
<solution>tags; test robustness to formatting errors, adversarial prompt changes, and length-neutral evaluation protocols. - Goodhart’s law risks: optimizing for rubric satisfaction may distort planning style (verbosity, superficial specificity); introduce audits for shallow compliance vs genuine rigor, and diversify rubrics and judges.
- Multi-objective RL: current reward is a single scalar fraction of satisfied items; explore multi-objective optimization balancing feasibility, ethics, novelty, rigor, and resource use with Pareto or preference-based methods.
- Baseline comparisons: lack of comparisons to strong prompting/scaffolding agents, tool-augmented planners, or retrieval-augmented systems; benchmark against contemporary agentic baselines under identical goals and constraints.
- Safety and ethics depth: ethical checks are generic; incorporate domain-specific safety policies (e.g., biosafety levels, patient data governance) and measure the model’s adherence and refusal behavior.
- Reproducibility and openness: trained models are not stated as released; release weights, prompts, grader configs, and training logs to enable independent replication and ablation studies.
- Compute and environmental costs: training configuration and reward computation costs are not benchmarked; report compute, energy, and cost per improvement, and compare to alternative training recipes.
- Cross-language generalization: dataset and evaluations appear English-only; build multilingual research-goal corpora and assess planning quality across languages and translation settings.
- Real-time and evolving tools: tool documentation refinement example presumes dynamic tools; evaluate planning under changing APIs, version drift, and incomplete tool specs to stress-test robustness.
- Clarifying assumptions and uncertainty: plans are graded on rubric compliance, not on explicit uncertainty quantification; require plans to declare assumptions, risks, and fallback strategies and evaluate their quality.
- Per-item error analysis pipeline: violation-based grading enables analysis but no systematic remediation loop is presented; implement targeted fine-tuning on frequently violated items and measure closed-loop improvements.
- Human–AI collaboration metrics: the study gauges expert preferences but not collaborative efficiency (time saved, errors caught); design user-in-the-loop experiments quantifying productivity and error reduction.
- Long-term generalization: cross-domain gains are shown short-term; track performance drift and retention over time and after additional finetuning or deployment feedback.
- Compliance with institutional processes: plans don’t consider grant constraints, procurement, IRB, or lab resources; integrate operational constraints into goals/rubrics and evaluate adherence.
- Novelty vs rigor trade-offs: novelty judgments are delegated to humans; explore mechanisms to incorporate novelty targets without sacrificing soundness (e.g., novelty-aware rubrics with safeguards).
- Adversarial robustness: test whether models can be induced to game rubrics or exploit grader biases; design red-team evaluations and defenses (e.g., adversarial rubrics, randomized item phrasing).
- Judge diversity in training: evaluation uses a judge jury, but training uses a single grader; explore training with ensembles, disagreement-aware rewards, or meta-graders that penalize judge-specific exploitation.
Glossary
- Ablations: Controlled experiments that remove or vary components to measure their impact on performance. "Training Ablations"
- AlphaEvolve: An AI system for scientific optimization and discovery via agent-based experimentation. "AlphaEvolve"
- AlphaFold: A deep learning system for predicting protein structures from amino acid sequences. "AlphaFold"
- Bootstrap sampling: A statistical resampling technique used to estimate uncertainty such as confidence intervals. "we use bootstrap sampling throughout our experiments."
- Claude-4-Sonnet: A frontier LLM used as a judge and sample selector in evaluations. "Claude-4-Sonnet"
- Cohen's kappa (κ): A statistic measuring inter-rater agreement beyond chance. "achieves a Cohen's alignment score of $0.297$"
- Confounders: Variables that can distort or bias experimental conclusions if not controlled. "checking for relevant confounders"
- Creator-solver gap: A setup where the data creator has access to privileged information, making their task easier than the solver’s. "This creates a creator-solver gap"
- End-to-end executable environment: A fully specified, automated environment where models can run experiments and receive programmatic feedback. "create an end-to-end executable environment for a specific task"
- Frontier models: The most capable state-of-the-art LLMs used for evaluation or adjudication. "a jury of frontier models"
- Generator-verifier gap: A training configuration where the verifier has more information than the generator, enabling targeted improvement signals. "creates a generator-verifier gap that enables improvements"
- Group Relative Policy Optimization (GRPO): An RL optimization method that normalizes rewards within groups, removing the need for a separate value network. "Group Relative Policy Optimization (GRPO)"
- HealthBench: A rubric-based benchmark for evaluating LLMs on health-related tasks. "rubric benchmarks like HealthBench"
- Held-out grader: A stronger, separate judge used only for validation to detect over-optimization to the training reward. "held-out stronger grader, Claude-4-Sonnet"
- Kullback–Leibler divergence (KL divergence): A measure of difference between probability distributions; used as a regularization penalty in RL fine-tuning. "disable the KL divergence penalty"
- KL penalty: A regularization term that discourages the policy from deviating too far from its prior; often adjusted to balance exploration. "disabling the KL penalty increases performance"
- Length Control Strategy: A method to constrain the final plan length while allowing unlimited internal reasoning tokens. "Length Control Strategy."
- Mixture-of-Experts (MoE): A model architecture that routes inputs to specialized expert sub-networks, increasing capacity efficiently. "a Mixture-of-Experts (MoE) model with 3B active parameters."
- Policy model: In RL, the model that outputs actions (here, plans) given inputs or states. "train a policy model , i.e., the plan generator"
- Privileged information: Information available to the grader but hidden from the generator to simplify verification and provide sharper rewards. "rubrics as privileged information"
- Reinforcement Learning (RL): A training paradigm where models learn by maximizing rewards from feedback signals. "via Reinforcement Learning (RL) with self-grading."
- Reward hacking: Exploiting loopholes in a reward function to achieve high scores without genuine task performance. "reward hacking"
- Reward model (grader): The model that evaluates outputs and produces scalar rewards for RL training. "reward model (grader)"
- Rubric Grading: Evaluation using goal-specific checklists of required features to determine plan quality. "Rubric Grading"
- Rubric-RL: Reinforcement learning that uses rubric-based judgments to shape the reward signal. "implement the Rubric-RL framework"
- Self-grading: Using a (frozen) copy of the model to grade its own outputs to produce training rewards. "self-grading"
- Self-rewarding loop: A setup where the model improves by maximizing scores produced by its own grader. "This creates a self-rewarding loop"
- Stratified sample: A sampling method ensuring balanced representation across predefined subgroups. "We create a stratified sample from all subjects to avoid imbalance"
- Supervised Fine-Tuning (SFT): Training a model on labeled examples to imitate desired outputs. "Supervised Fine-Tuning (SFT) worsens plan quality."
- Value network: An RL component that estimates expected returns; GRPO obviates the need for it by within-group normalization. "removes the need for a separate value network"
- VeRL library: An open-source system used to implement RL fine-tuning workflows. "using the VeRL library"
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging rubric-guided plan generation, dataset curation, and self-grading RL as presented in the paper. They focus on augmenting human decision-making, improving planning quality, and standardizing evaluation with instance-specific rubrics.
- Research planning copilot for academia
- Sector: Education/Academia
- Use cases:
- Graduate student support: generate, compare, and refine research plans for thesis topics or course projects using goal-specific rubrics.
- Grant proposal drafting: convert research aims and constraints into detailed, testable plans and evaluation criteria; auto-check for feasibility, clarity, and ethical compliance via general guidelines.
- Lab meeting workflows: create structured research agendas that explicitly address confounders, hypotheses, and measurement plans; track rubric satisfaction over iterations.
- Tools/products/workflows:
- “Plan Studio” IDE integration for plan drafting with rubric-based checks.
- A rubric-aware peer review assistant to pre-screen internal proposals.
- Assumptions/dependencies:
- Access to relevant literature and internal documents for reliable goal extraction.
- Human-in-the-loop oversight to judge novelty, value, and methodological rigor.
- R&D planning assistant for industry teams
- Sector: Software/Tech
- Use cases:
- A/B test design: generate experiment plans with defined metrics, guardrails, counterfactuals, and resource constraints; auto-check against general guidelines (e.g., overlooked flaws).
- Feature launch evaluation: propose pre-/post-analysis plans ensuring alignment with constraints and cost-efficiency.
- Tool documentation improvement workflows: plan iterative documentation updates driven by usage logs and failure modes (inspired by the example rubric on tool-learning for LLMs).
- Tools/products/workflows:
- Rubric-augmented PRD (product requirements document) assistant integrated with issue trackers.
- “Rubric-RL Evaluator” service to grade internal plans and suggest revisions.
- Assumptions/dependencies:
- Access to telemetry, experimentation platforms, and internal tooling; careful handling of proprietary data.
- Adoption of structured plan-length controls to reduce verbosity bias.
- Clinical and biomedical research plan assistant
- Sector: Healthcare/Medical Research
- Use cases:
- Draft clinical protocol outlines with eligibility criteria, outcomes, confounders, and ethical safeguards; grade against goal-specific rubrics.
- Observational study design plans with bias mitigation, data quality checks, and statistical analysis frameworks.
- Hospital quality improvement projects: standardize initiatives with clear metrics and feasibility checks.
- Tools/products/workflows:
- “Protocol Planner” generating plans and rubric-based compliance checklists for IRB submission.
- Model jury evaluation for cross-checking plan quality pre-implementation.
- Assumptions/dependencies:
- Mandatory expert review; regulatory compliance (IRB, HIPAA/GDPR); strict data privacy and safety constraints.
- No autonomous execution—use plans as scaffolds, not directives.
- Policy analysis and program evaluation support
- Sector: Public Policy/Government
- Use cases:
- Design program evaluation frameworks (RCTs, quasi-experimental setups) with explicit rubric criteria for feasibility, ethics, and cost-effectiveness.
- Procurement and oversight: rubric-based screening of vendor proposals for clarity, measurable outcomes, and risk mitigation.
- Tools/products/workflows:
- “Policy Plan Checker”: rubric library for program evaluations and audits; integrates general guidelines for consistency and ethicality.
- Assumptions/dependencies:
- Availability of domain-specific rubrics; transparent documentation to avoid bias and ensure reproducibility.
- Human adjudication for political, social, and ethical trade-offs.
- Finance and quantitative research planning
- Sector: Finance/Quantitative Research
- Use cases:
- Backtesting and risk modeling study plans: define data splits, confounders, and robustness checks; enforce pre-analysis plan rubrics.
- Compliance-oriented experiment design for algorithmic trading strategies.
- Tools/products/workflows:
- “Quant Plan Generator” with rubric grading for leakage, overfitting, and cost constraints.
- Assumptions/dependencies:
- Access to historical data and governance frameworks; careful handling of regulatory rules and internal compliance.
- Robotics and engineering experiment design assistant
- Sector: Robotics/Engineering
- Use cases:
- Benchmarking and experiment protocols for manipulation, locomotion, and perception; enforce reproducibility and safety rubrics.
- Hardware test plans with explicit measurement procedures and failure mode analysis.
- Tools/products/workflows:
- “Engineering Plan Reviewer” that applies general guidelines to detect missing specifications or overlooked hazards.
- Assumptions/dependencies:
- Availability of testbeds, simulation, or lab infrastructure; domain expert validation for safety-critical steps.
- Energy systems research planning
- Sector: Energy/Utilities
- Use cases:
- Demand-response experiment design; grid optimization pilot plans with defined metrics and constraints.
- Measurement and verification (M&V) protocols with rubric checks for cost-efficiency and feasibility.
- Tools/products/workflows:
- “Energy Pilot Planner” for structured trial design and rubric-based evaluation.
- Assumptions/dependencies:
- Access to operational data; compliance with regulatory and safety standards.
- Education and training
- Sector: Education
- Use cases:
- Course assignments: student-facing planning exercises with auto-generated instance-specific rubrics and feedback.
- Instructor tools: automated grading of project proposals against general guidelines (clarity, soundness, ethicality).
- Tools/products/workflows:
- “RubricBench” for coursework and capstone projects; dashboards showing rubric satisfaction rates.
- Assumptions/dependencies:
- Careful calibration to avoid over-reliance on automated scoring; instructor oversight.
- Daily life and personal projects
- Sector: Consumer/Personal Productivity
- Use cases:
- Structured planning for science fair projects, DIY experiments, and learning goals; use general guidelines to improve clarity and feasibility.
- Concise plan generation via length-control prompting (e.g., tag-based content boundaries).
- Tools/products/workflows:
- “Plan Coach” app: outputs concise, rubric-checked plans; tracks revisions and guideline violations.
- Assumptions/dependencies:
- Simpler goals benefit most; complex domains still require expert review.
- Organizational evaluation and Evals infrastructure
- Sector: Cross-sector
- Use cases:
- Instance-specific rubric generation from internal documents (design docs, specs, whitepapers) to standardize plan evaluation.
- Jury-of-models scoring pipelines to monitor plan quality and detect over-optimization to a single judge.
- Tools/products/workflows:
- “Plan Quality Dashboard” aggregating rubric satisfaction, guideline violations, and human-review outcomes.
- Assumptions/dependencies:
- Governance around evaluation drift and model bias; periodic alignment with human judgments.
Long-Term Applications
These applications require further research, scaling, regulatory clearance, or deeper integration with execution environments. They leverage the generator–verifier gap, rubric datasets, and RL training to move beyond plan generation toward more autonomous and reliable scientific workflows.
- Generalist AI co-scientist for cross-domain research orchestration
- Sector: Academia/Industry R&D
- Vision:
- A model that proposes, revises, and maintains research plans across domains (ML, biology, materials, social science), tuned with instance-specific rubrics and general guidelines.
- Supports hypothesis refinement, multi-experiment scheduling, risk mitigation, and meta-analysis planning.
- Dependencies:
- Stronger, diverse rubrics; robust model jury alignment with human experts; scalable human oversight and governance.
- Continual learning on new literature with contamination controls.
- Integrated plan-to-execution agents
- Sector: Software/Robotics/Engineering
- Vision:
- Seamless handoff from rubric-validated plans into execution agents (e.g., code agents, lab automation, robotics controllers) with closed-loop feedback to update plans and rubrics.
- Auto-detection of reward model over-optimization via held-out evaluators; dynamic length-control strategies to manage verbosity and precision.
- Dependencies:
- Reliable simulators or lab automation; safety and compliance frameworks; robust failure mode detection; cost-effective compute.
- Clinical trial design optimization and registry integration
- Sector: Healthcare/Medical Research
- Vision:
- AI-supported trial design that optimizes inclusion criteria, endpoints, statistical power, and ethical safeguards under rubric constraints; integrates with clinical trial registries and IRB systems.
- Dependencies:
- Regulatory approval pathways; validation against human expert panels; patient safety guarantees; data privacy protections.
- Policy co-designer for program governance and evaluation
- Sector: Government/Public Policy
- Vision:
- AI systems that co-design policies with embedded rubrics for fairness, accountability, and feasibility; simulate outcomes and propose evaluation plans, including pre-analysis registration.
- Dependencies:
- Transparent model governance; public oversight; bias mitigation; legal guardrails for automated policy support.
- Enterprise-grade Evals ecosystem for planning quality
- Sector: Cross-sector/Enterprise
- Vision:
- Standardized rubric libraries and automated graders tailored to domains (health, finance, energy) with periodic human calibration; detect reward hacking and evaluation drift; longitudinal quality tracking.
- Dependencies:
- Interoperable standards; secure data access; auditor frameworks; model jury updates aligned with human consensus.
- Knowledge base of rubric patterns and meta-science analytics
- Sector: Meta-Research/Knowledge Management
- Vision:
- A living repository of reusable rubric patterns and plan archetypes by field; analytics on what plan features correlate with successful outcomes; guidance for designing better rubrics.
- Dependencies:
- Large-scale aggregation of plans and outcomes; privacy-preserving data sharing; methods for causal attribution.
- Tool ecosystems with self-maintaining documentation
- Sector: Software/DevTools
- Vision:
- LLM-aware tools whose documentation, examples, and affordances are auto-refined based on agent interactions and failures, guided by rubrics for completeness, accuracy, and cross-model generalization.
- Dependencies:
- Standardized telemetry; consent and privacy; developer buy-in; evaluation harnesses for documentation quality.
- Safety-aware autonomous planning in high-stakes environments
- Sector: Robotics/Energy/Healthcare
- Vision:
- Planners that couple rubric checks with formal safety constraints and runtime monitors; propose and adapt plans while provably respecting safety and ethical guidelines.
- Dependencies:
- Formal verification tooling; certified runtime guards; domain-specific safety rubrics; regulatory approval.
- Economic and environmental impact planning
- Sector: Energy/Finance/Policy
- Vision:
- Planning systems that incorporate cost-efficiency, lifecycle analysis, and risk under rubric constraints; automate sensitivity analyses and counterfactual planning for large-scale interventions.
- Dependencies:
- High-quality data; robust uncertainty modeling; cross-disciplinary rubrics; stakeholder governance.
Cross-cutting assumptions and dependencies
- Rubric quality and coverage: Instance-specific rubrics must capture critical constraints and implicit requirements; periodic expert validation is essential.
- Model judge reliability: Generator–verifier gaps help, but model jury alignment with humans varies; avoid over-optimization to a single judge by using held-out evaluators and human calibration.
- Human oversight: Subjective judgments (novelty, societal value) remain with humans; AI outputs should be scaffolds, not final decisions.
- Data governance: Respect licensing, privacy, and regulatory constraints when extracting goals and rubrics from documents; ensure secure handling of proprietary data.
- Safety and ethics: Particularly in healthcare, energy, and robotics, adopt conservative deployment with explicit compliance workflows.
- Compute and cost: Training and evaluation with large models and model juries require significant resources; organizations may need smaller local graders with periodic cross-checks against stronger models.
- Integration and adoption: Success depends on embedding rubric-aware planning tools into existing workflows (IDEs, EHRs, experiment platforms, policy portals) with change management and user training.
Collections
Sign up for free to add this paper to one or more collections.