- The paper presents a comprehensive benchmark that evaluates LLM-based unstructured data systems for accuracy, computational cost, and latency.
- It outlines a multi-stage system architecture with query interfaces, logical and physical optimizations, and curated datasets from diverse domains.
- The evaluations demonstrate that chunking strategies and filter optimization effectively balance performance, cost, and real-time processing.
Unstructured Data Analysis using LLMs: A Comprehensive Benchmark
This paper presents a significant contribution to evaluating LLM-powered systems for unstructured data analysis (UDA), which is increasingly critical given the ubiquitous presence and analytical potential of unstructured data in modern organizations. The benchmark proposed is comprehensive, with datasets spanning across various domains, rich in content and complexity, designed to test the effectiveness, efficiency, and cost-effectiveness of such systems.
System Architecture
The architecture of unstructured data analysis systems typically includes several critical components: query interface, logical optimization layer, physical optimization layer, and data processing layer (Figure 1). The query interface allows users to define analytical tasks using SQL-like language or declarative Python APIs. The logical optimization layer transforms user queries into an optimal execution plan, often employing techniques such as filter reordering and pushdown strategies. The physical optimization layer chooses implementations for operators that optimize for accuracy, cost, and latency. Data processing involves organizing diverse types of unstructured data (text, images, etc.) into formats conducive for analysis, such as CSV, JSON, or semantic hierarchical trees.
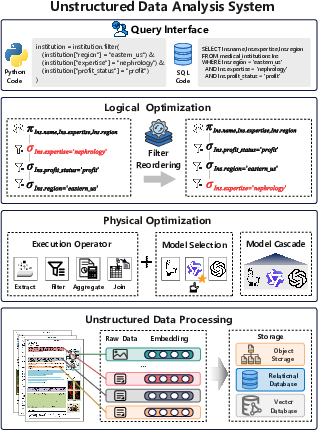
Figure 1: Architecture of Unstructured Data Analysis System.
UDA systems powered by LLMs strive to optimize for accuracy, computational cost, and latency. Accuracy matters due to potential model hallucinations and the necessity to retrieve relevant chunks of data. Cost management is essential given the high computational expense of LLM inference, primarily driven by input token usage. Latency reduction is critical for efficiency, often managed by minimizing token count and utilizing parallel processing.
Benchmark Construction
The benchmark construction involved careful curation and annotation, resulting in datasets that reflect diverse aspects like volume, modality, and domain specificity. Each dataset includes numerous documents with varying characteristics:
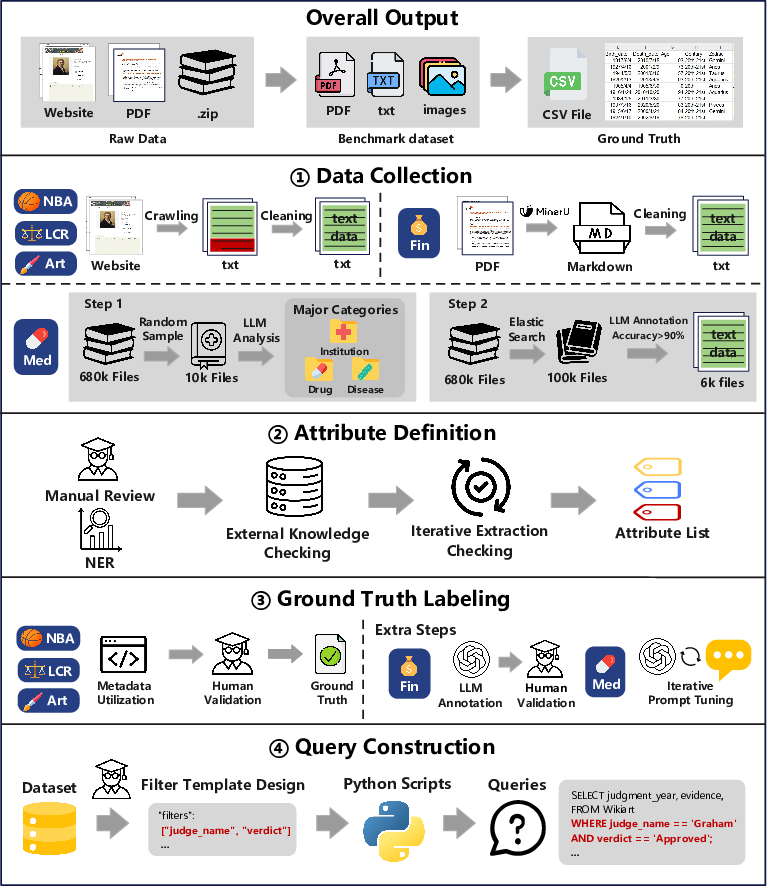
Figure 2: Benchmark Construction Process.
- WikiArt: Includes 1,000 art-related documents combining text and high-resolution images.
- NBA: Compiles 225 documents from Wikipedia encompassing detailed historical and statistical information of NBA entities.
- Legal: Contains 570 legal cases from AustLII, rich in domain-specific complexity.
- Finance: Features 100 lengthy financial reports from the Enterprise RAG Challenge.
- Healthcare: Comprised of 100,000 documents from MMedC, encapsulating broad medical content.
For each dataset, attributes are identified, requiring different levels of extraction complexity. Precise labeling is performed by graduate students supported by LLM cross-validation processes, leading to a high-quality ground truth necessary for robust evaluation.
Evaluations and Results
Accuracy: Evaluations indicated that systems feeding whole documents to LLMs generally attain higher accuracy for complex datasets, whereas strategies that implement extraction before filter evaluation yield better results for straightforward datasets.
Cost Analysis: Feeding entire documents tends to be more cost-effective for shorter documents but is less viable for longer ones. Systems like QUEST and ZenDB utilize chunking strategies, reducing the computational costs significantly while maintaining reasonable accuracy levels.
Latency Analysis: Latency correlates with token consumption and LLM call frequency. Strategies that minimize both input tokens and LLM invocations, like QUEST and ZenDB, show efficiency advantages.
Logical Optimization: Strategies for filter reordering involving selectivity and token cost optimization reduced costs more effectively than random ordering. Filter pushdown strategies demonstrated advantage in cases where joins can be optimized similarly to filters.
Physical Optimization: Model selection and cascades offer cost reductions without sacrificing accuracy, crucial for handling complex attribute extraction. Parallelism maximizes efficiency for large datasets, maintaining consistent accuracy levels.

Figure 3: Evaluation of Model Selection.
Conclusion
The comprehensive benchmark established in this paper profoundly enhances the evaluation landscape for UDA systems using LLMs. By addressing dataset diversity, query complexity, and precise labeling, it provides a solid foundation for subsequent research and development in this domain. The insights gained suggest further opportunities to refine chunking strategies, semantic alignment, and end-to-end optimization approaches—all pivotal for advancing AI-driven data analysis methodologies.