- The paper presents TableEval, introducing a robust benchmark that integrates complex table structures, multiple languages, and domain-specific reasoning.
- It uses SEAT, a structured evaluation framework comparing LLM outputs against human-verified, structured reference answers.
- Experimental results reveal state-of-the-art models struggle with nested structures and multilingual challenges, highlighting the need for improved table understanding.
TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering
Introduction
"TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering" presents TableEval, a benchmark designed to address limitations in current Table Question Answering (TableQA) evaluation methods. Existing benchmarks are typically limited by their focus on simple table structures and lack multilingual and multi-domain context, rendering them unsuitable for real-world applications. TableEval aims to fill this gap by introducing a comprehensive evaluation framework that integrates diverse table structures, languages, and domain-specific reasoning. The benchmark includes tables with hierarchical and nested structures sourced from various domains and multilingual scenarios (Simplified Chinese, Traditional Chinese, and English).
Dataset Construction
TableEval's dataset is constructed through a meticulous process, designed to minimize data leakage and ensure relevance to current TableQA challenges. Data is collected from financial reports, industry research, academic papers, and governmental data published in 2024, ensuring the novelty and applicability of the benchmark. The collection process involves:
- Tabular Data Collection: Tables are extracted from source documents and reviewed for accuracy, ensuring alignment with the original PDFs. These tables are then categorized into types such as vertical, horizontal, matrix, hierarchical, concise, and nested structures.
- Question Generation: Multiple strategies, including Template-Prompted and Role-Prompted questions, are employed to generate diverse question types associated with the tables. To ensure question variety and relevance, K-means clustering is used for sampling and deduplication.
- QA Acquisition and Human Annotation: Human annotators verify each QA pair to ensure the accuracy and relevance of questions to table content. Structured answer extraction is employed to improve the precision of evaluations.
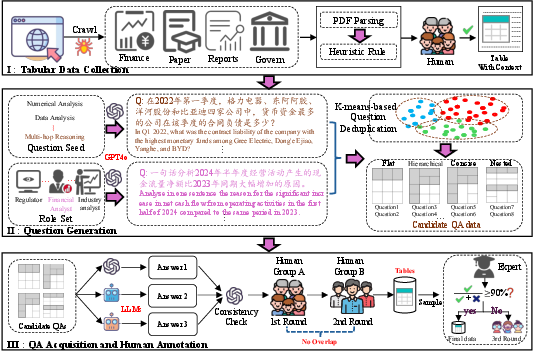
Figure 1: Overview of data collection. (1) Tabular Data Collection, collecting tables from financial reports, industry research, academic papers, and governmental data; (2) Question Generation, using Template-Prompted and Role-Prompted strategies to generate TableQA questions, filtered through clustering and deduplication; (3) QA Acquisition and Human Annotation iteratively refining answers through LLM consistency checks, human reviews, and structured answer extraction, ensuring accuracy, completeness, and alignment with the original tabular data.
Evaluation Framework - SEAT
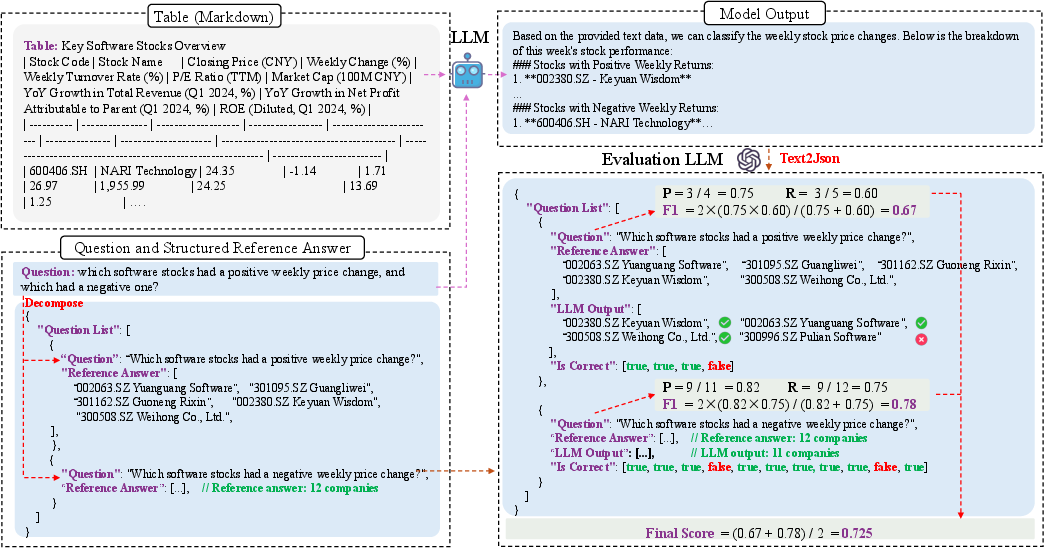
To evaluate LLMs on TableQA tasks, SEAT (Structured Evaluation for Answers in TableQA) is proposed as a framework that uses LLMs to compare generated responses against structured reference answers. SEAT's evaluation involves:
SEAT outperforms traditional metrics by focusing on semantic correctness rather than surface-level accuracy, showcasing higher agreement with human evaluations.
Experimental Results
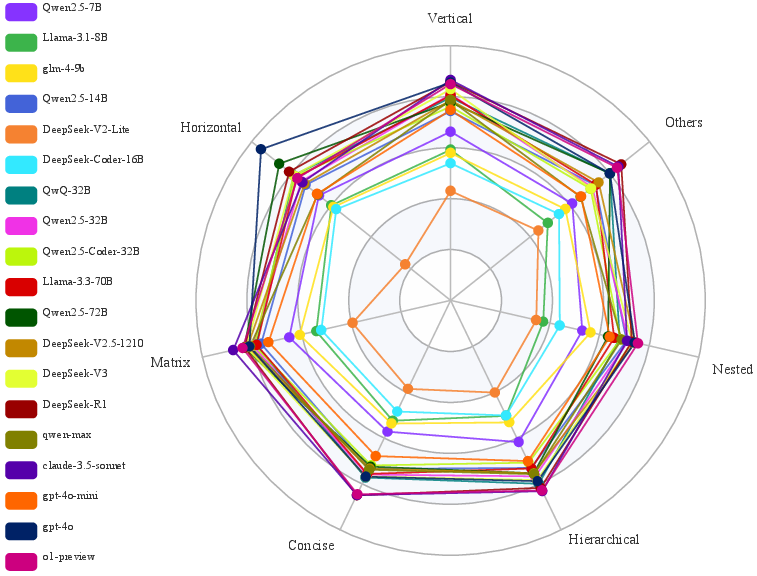
Tests on TableEval demonstrate significant gaps in the ability of state-of-the-art LLMs to manage complex TableQA tasks:
Implications and Future Directions
TableEval and SEAT highlight critical areas for further research in TableQA:
- Structure-Aware Representations: Improving models' understanding of complex table structures can enhance performance.
- Enhanced Multilingual Capability: Developing methods to improve cross-lingual generalization is necessary for broader applicability.
- Domain Adaptation: Domain-specific fine-tuning or pretraining could bridge existing performance gaps.
Conclusion
TableEval advances the evaluation of LLMs by introducing diverse table structures, multilingual data, and realistic benchmarking conditions. While current models show potential, especially when scaled, significant challenges remain in understanding nested structures and reasoning across diverse domains and languages. SEAT provides a robust evaluation mechanism that aligns well with human judgment, particularly for complex QA tasks. This advancement in benchmarking promises to guide future improvements in LLM capabilities for TableQA.
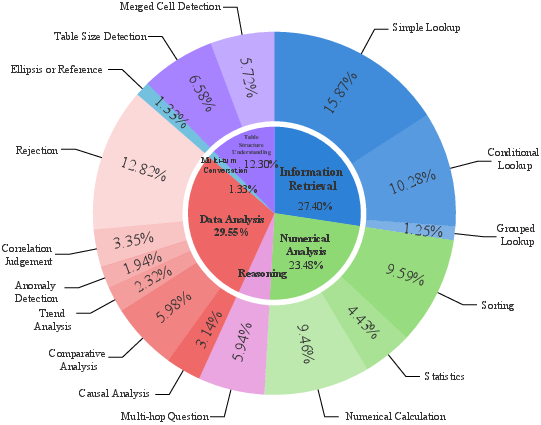
Figure 4: Task distribution of our TableEval.
Through TableEval and SEAT, the research community is equipped with tools to explore innovative approaches in handling complex, real-world TableQA scenarios.