- The paper introduces an LLM-powered system that converts natural language queries into detailed semantic analytics pipelines.
- It integrates a vision-based partitioner, distributed document engine, and a query planner to overcome traditional RAG limitations.
- The system demonstrates robust performance with superior document segmentation and a 72% accuracy in query planning on real-world data.
Aryn: An LLM-Powered Unstructured Analytics System
This paper introduces Aryn, an LLM-powered unstructured analytics system designed to perform complex semantic analyses on large collections of unstructured documents. Aryn leverages a declarative query processing approach, allowing users to specify queries in natural language, which the system then translates into a semantic plan for execution. The system incorporates several key components, including Sycamore, a distributed document processing engine; Luna, a query planner; and the Aryn Partitioner, which converts raw documents into a structured format suitable for analysis. The paper demonstrates Aryn's capabilities through a real-world use case involving the analysis of NTSB accident reports.
Use Cases, Challenges, and Design Tenets
The paper highlights several enterprise use cases that motivate the development of Aryn. These include building AI assistants for customer support, creating Q&A systems for manufacturing, summarizing patient records, conducting financial analysis, and analyzing legal documents. The key challenge addressed is the limitation of traditional RAG approaches, which struggle with complex reasoning, large datasets, and documents containing tables, graphs, and images. The paper argues that RAG accuracy degrades quickly as one asks more complex questions, adds more data, or works with more complex data. To overcome these limitations, the design of Aryn is guided by three tenets: leveraging LLMs for their strengths while incorporating human expertise, using visual models to enhance document understanding, and ensuring explainability of results.
System Architecture and Components
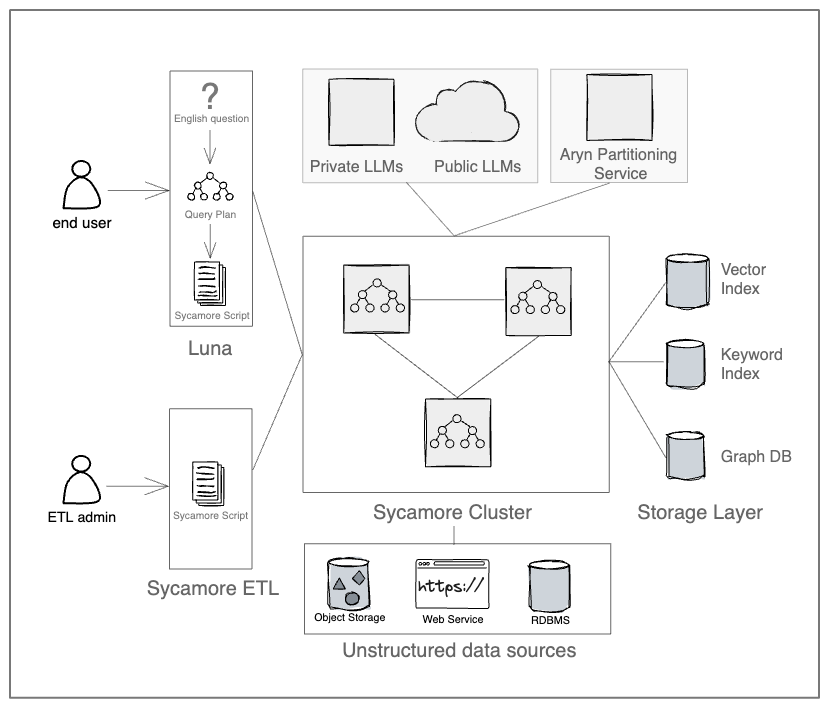
Figure 1: A high-level architectural overview of the Aryn system, illustrating the interplay between the Aryn Partitioner, Sycamore, and Luna.
Aryn's architecture (Figure 1) comprises three primary components: the Aryn Partitioner, Sycamore, and Luna.
Aryn Partitioner
The Aryn Partitioner is responsible for segmenting raw documents into structured components. It employs a vision-based document segmentation model based on the Deformable DETR architecture, trained on the DocLayNet dataset. The model achieves a mean average precision (mAP) of 0.602 and a mean average recall (mAR) of 0.743 on the DocLayNet competition benchmark, outperforming a document API from a large cloud vendor, which achieved only an mAP of 0.344 with an mAR of 0.466. The partitioner also incorporates table extraction using the Table Transformer model, image processing, and OCR capabilities.

Figure 2: An example of the Aryn Partitioner's output on an NTSB accident report, showcasing the identification of tables and cells.
Sycamore
Sycamore is a document processing engine built on DocSets, which are reliable distributed collections of hierarchical documents represented as semantic trees. It provides a set of transformations for ETL and analytics, including flattening, embedding, filtering, summarizing, and extracting information. Sycamore integrates with LLMs to power many of these transformations, with lineage tracking for debugging. The system adopts a Spark-like execution model, with operations pipelined and executed lazily. Sycamore is built on top of the Ray compute framework, which provides primitives for distributing Python objects.
Luna
Luna is the query layer that translates natural language questions into semantic query plans. It uses LLMs to construct query plans that users can inspect and validate, providing explainability and enabling debugging. Luna incorporates a combination of traditional data-processing operators (count, aggregate, join) and semantic operators (llmFilter, llmExtract). The framework achieved a 72% accuracy on a micro-benchmark using questions from financial customers on an earnings report dataset, and questions for the NTSB reports.
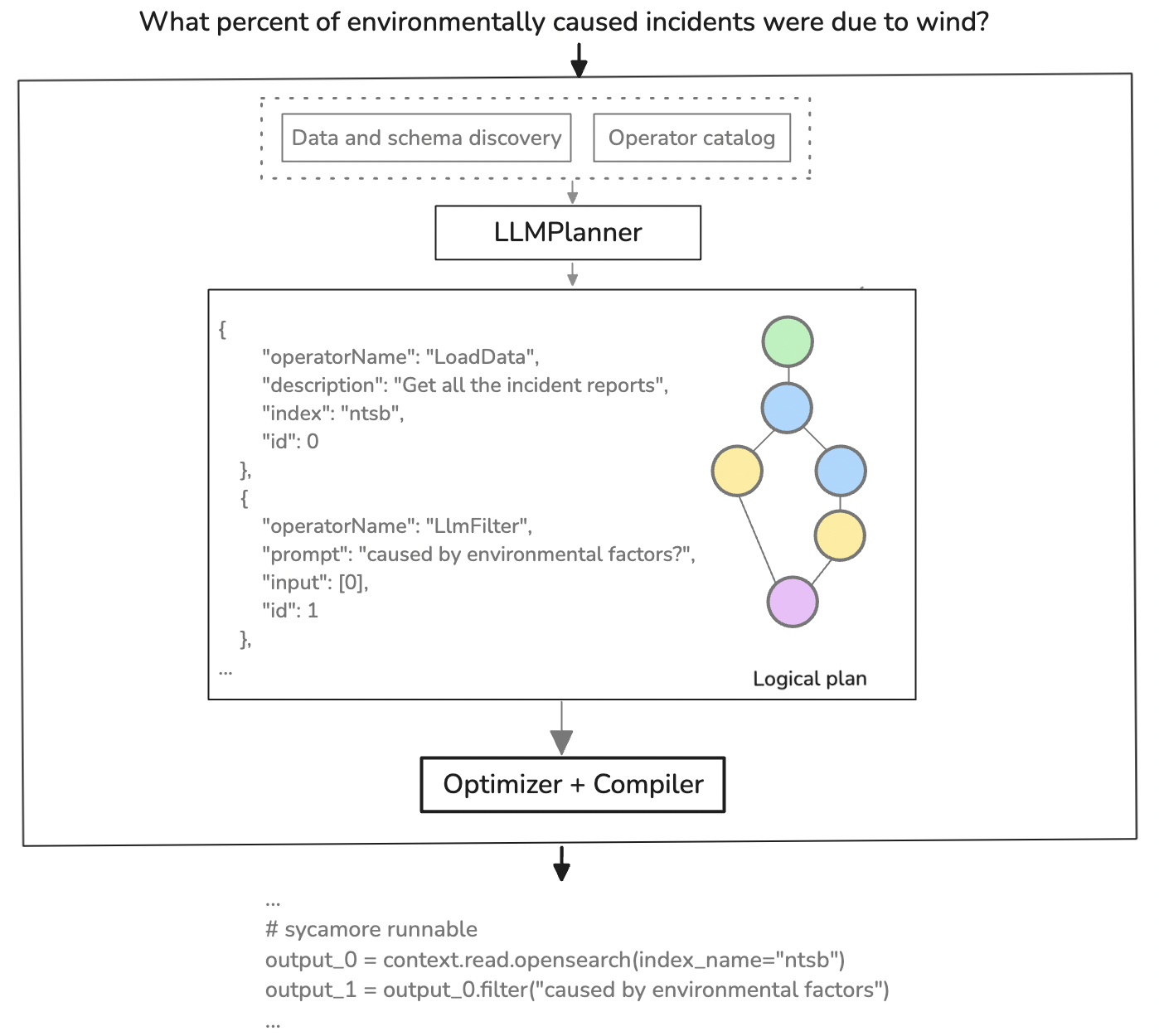
Figure 3: A visual representation of Luna's query execution workflow, illustrating the steps involved in processing a natural language query.
The paper references existing work on natural language to SQL translation, LLM-based query generation, and the use of LLMs for specific ETL tasks. It differentiates Aryn by its broader set of LLM-based operations, focus on hierarchical datasets, and emphasis on interactive interfaces. The authors position Aryn within the landscape of end-to-end systems like ZenDB, LOTUS, EVAPORATE, CHORUS and Palimpzest, emphasizing Aryn's human-in-the-loop paradigm. The Aryn Partitioner is contextualized within research on document segmentation and object detection models like DETR and Deformable DETR, as well as multi-modal models such as Donut and LayoutLMV3.
Conclusion
Aryn represents a significant step toward unifying unstructured and structured analytics by leveraging LLMs to process multi-modal datasets. The system's human-in-the-loop design acknowledges the limitations of current models while providing a path for future improvements. Key areas for future work include developing more robust data and querying abstractions, exploring knowledge graphs, and building more scalable systems for processing large multi-modal repositories.

